



欢迎大家关注「几米宋」的微信公众号,公众号聚焦于 AI、云原生、开源软件、技术观察以及日常感悟等内容,更多精彩内容请访问个人网站 jimmysong.io。
📄 文章摘要
探讨 AI 时代开源的变革,从 Kubernetes 到 Qwen,揭示中美厂商在开源策略上的根本差异与新机遇。
AI 时代的开源已不再是“看得见源码”,而是“能加载模型、能微调智能”。美国厂商闭源筑护城河,中国厂商开源抢生态,开源的意义和玩法都发生了根本变化。
AI 时代开源的逻辑彻底变了
引言
十年前,云原生浪潮掀起时,美国的 Google、Red Hat、Docker 等公司开源了大量基础设施软件——Kubernetes、Docker、Istio 成了全球开发者的共同语言。
然而进入大模型时代,局面却完全反转:美国科技公司几乎不再开源核心模型,而中国厂商(如智谱、阿里、面壁、零一万物、月之暗面等)却频频发布开源大模型。为什么会出现这种转变?“AI 开源”与“基础设施开源”又有什么根本区别?
云原生时代与 AI 时代的开源逻辑变化
下表对比了云原生与 AI 时代开源的核心逻辑、盈利方式和资源依赖。
| 时代 | 代表技术 | 开源核心逻辑 | 盈利方式 | 对资源依赖 |
|---|---|---|---|---|
| 云原生时代(2010s) | Istio、Kubernetes、Docker | 共建标准、扩张生态 | 托管服务(GKE、EKS) | CPU 级算力,可社区驱动 |
| AI 大模型时代(2020s) | Ollama、GPT、Qwen | 模型即资产、控制数据 | API 服务或闭源 SaaS | GPU 级算力、集中化 |
云原生开源强调“共建标准”,而 AI 大模型开源则意味着“核心资产的开放”,两者的本质和动因截然不同。
美国公司为何不再真正开源
美国科技公司在 AI 时代选择闭源,背后有多重原因:
• 商业逻辑转向护城河思维:训练成本高昂,模型权重成为核心壁垒,开源等于让出竞争力。
• 算力与数据不可复制:社区难以复现 GPT-4 级别模型。
• 安全与合规约束:模型权重可能涉及用户数据,监管严格。
• “开放”被重新定义为“API 可访问”:开放平台更多指接口开放,而非代码与权重开放。
中国公司为何更愿意开源
中国厂商在 AI 领域积极开源,主要基于以下考量:
• 用开源换生态、换认知,快速建立品牌影响力。
• “开源 + 商业许可”双轨模式,兼顾生态扩展与商业收益。
• 数据政策环境更灵活,政策鼓励自主模型。
• 国家战略驱动,“自主可控”与“开源生态”成为科技战略重点。
开源载体的迁移:从 GitHub 到 Hugging Face
开源的载体也发生了变化。下表展示了 GitHub 与 Hugging Face 在开源形态上的区别。
| 平台 | 时代 | 核心资产 | 开源形态 |
|---|---|---|---|
| GitHub | 软件 / 云原生 | 源码 (.go /.py /.js) | 可编译、可运行 |
| Hugging Face | AI 模型 | 模型权重 + Tokenizer + 推理脚本 | 可加载、可微调 |
GitHub 主要开源“程序逻辑”,而 Hugging Face 则开源“模型智力”,两者的核心资产完全不同。
AI 开源的核心要素
AI 时代的开源不仅仅是代码开放,更包括权重、推理代码和微调能力。下面分别说明三大要素。
开放权重(Weights)
模型训练后的全部知识都存储在权重参数中。拥有权重即拥有模型的“智力本体”。闭源模型(如 GPT-4)只提供 API,不开放权重。
开放推理代码(Inference Code)
推理代码定义了如何加载权重、分词、并发计算和显存优化。下方代码演示了如何加载 Qwen3 模型:
from transformers import AutoModelForCausalLM, AutoTokenizer
# 加载模型与分词器
model_name = "Qwen/Qwen3-4B-Instruct-2507"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto", # 自动选择 FP16 或 FP32
device_map="auto" # 自动分配到 GPU / CPU
)
# 推理
prompt = "你好,请简要介绍一下大模型的微调原理。"
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
outputs = model.generate(**inputs, max_new_tokens=200)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))微调(Fine-tuning)
微调是在开源模型基础上再训练,使其适应特定数据和场景。常见方式有 LoRA / QLoRA,成本低,能让通用模型变成企业专属助手。
企业为何选择自部署而非 API
企业在实际应用中,往往更倾向于自部署开源模型。下表总结了主要原因和说明。
| 原因 | 说明 |
|---|---|
| 数据隐私 | 敏感数据不能外传 |
| 成本可控 | API 按调用计费,长期昂贵 |
| 可定制性 | 可结合企业知识做 RAG / Agent |
| 可运维性 | 可离线运行、统一监控、合规部署 |
Qwen3-4B-Instruct-2507 模型结构与使用
以 Qwen3-4B-Instruct-2507 为例,介绍 Hugging Face 上模型的目录结构和使用方法。
目录结构说明
模型下载后目录结构如下:
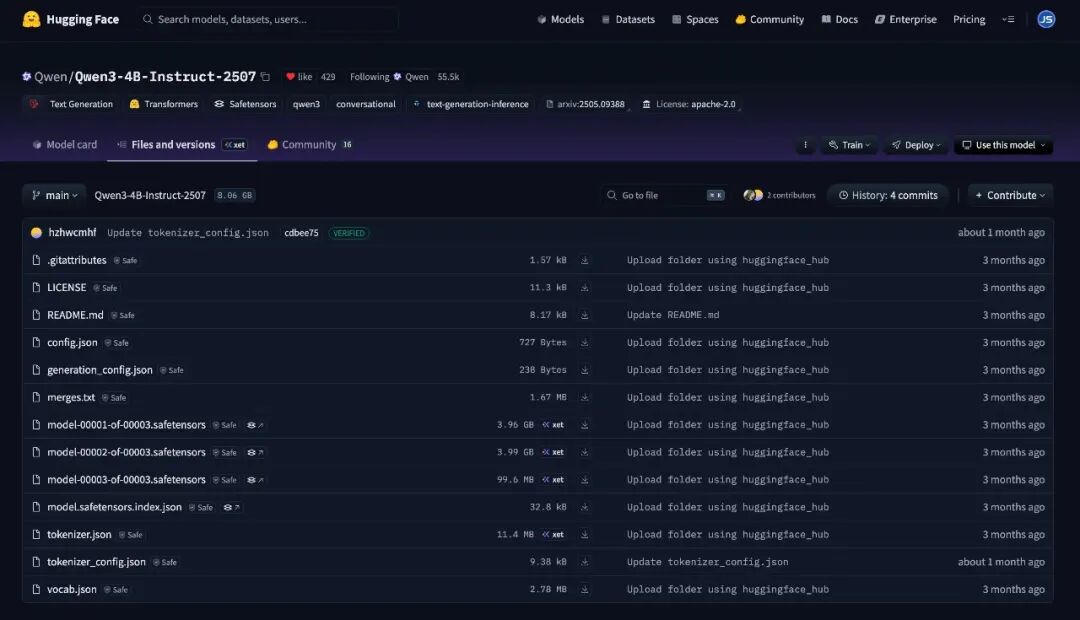
Qwen3-4B-Instruct-2507 目录结构
开源模型的目录结构可以用下图表示:
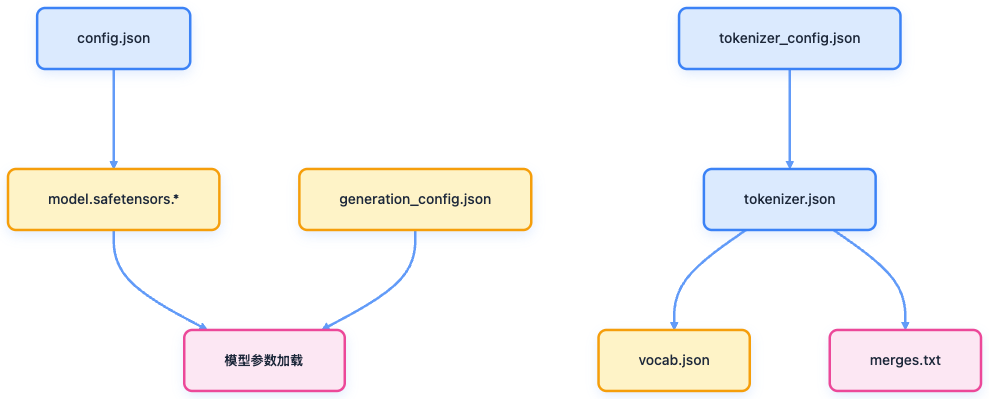
开源大模型目录结构
在开源模型的目录结构中,model.safetensors 文件即为模型权重,存储数十亿参数。
还有其他文件,如 README.md、LICENSE、.gitattributes,其作用说明如下:
| 分类 | 文件 | 作用说明 |
|---|---|---|
| 模型定义 | config.json, model.safetensors.*, model.safetensors.index.json | 定义模型结构与参数权重 |
| 分词系统 | tokenizer.json, tokenizer_config.json, vocab.json, merges.txt | 定义文本输入输出的编码方式 |
| 推理配置 | generation_config.json | 控制生成策略(温度、top_p 等) |
| 元信息 | README.md, LICENSE, .gitattributes | 模型介绍、许可、Git 属性 |
加载与推理代码示例
以下代码展示了如何加载并运行 Qwen3-4B-Instruct-2507 模型:
from transformers import AutoTokenizer, AutoModelForCausalLM
# 加载分词器和模型
tokenizer = AutoTokenizer.from_pretrained(
"Qwen/Qwen3-4B-Instruct-2507",
trust_remote_code=True
)
model = AutoModelForCausalLM.from_pretrained(
"Qwen/Qwen3-4B-Instruct-2507",
device_map="auto"
)
# 构造输入并推理
prompt = "你好,解释一下云原生的意义。"
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
outputs = model.generate(**inputs, max_new_tokens=200)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))如显存不足,可采用量化加载方式:
mdl = AutoModelForCausalLM.from_pretrained(
"Qwen/Qwen3-4B-Instruct-2507",
device_map="auto",
load_in_8bit=True
)开源 LLM 的开发者应用场景
开源大模型为开发者带来了丰富的应用场景。下表总结了常见方向、用途和工具。
| 方向 | 能做的事 | 工具 |
|---|---|---|
| 聊天 / 助手 | 本地 ChatGPT | LM Studio、TextGen WebUI |
| 知识库 RAG | 接私有数据问答 | LangChain、LlamaIndex |
| 智能体 Agent | 任务执行、工具调用 | LangGraph、Autogen |
| 微调 / 适配 | 定制企业知识 | PEFT、LoRA |
| 模型服务 | 部署为 API 服务 | vLLM、TGI、Ollama |
| 研究实验 | 模型压缩、量化 | BitsAndBytes、FlashAttention |
开源模型生命周期
开源模型从下载到生产上线的完整生命周期如下:
1. 下载模型权重
2. 加载推理代码
3. 本地推理或部署服务
4. 微调专属数据
5. 企业集成 RAG / Agent
6. 上线生产环境
如何判断开源大模型的许可证
下载一个开源模型 = 拥有一颗可加载、可训练、可商用的“智能大脑”; 但能不能拿它赚钱,还得看它的 License。
同传统的开源项目一样,对于大模型,是否可以商用,也需要关注许可证。
查看方法:
1. Hugging Face 模型主页右上角 → License: ...
2. 仓库根目录下的 LICENSE 或 README.md 文件
简要的判断流程如下:
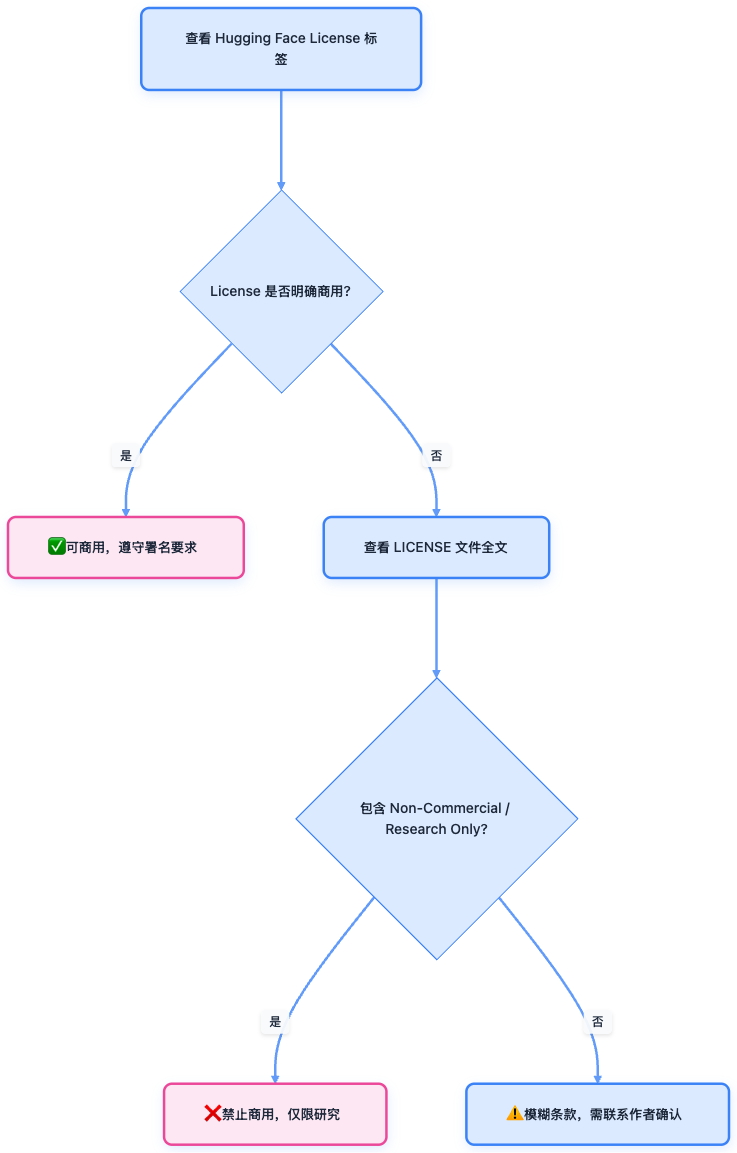
开源大模型许可证判断流程
总结
AI 时代的开源已从“能看源码”转变为“能加载模型、能微调智能”。美国厂商以闭源维护商业护城河,中国厂商则用开源抢占生态高地。开源的真正价值在于赋能开发者,让每个人都能拥有属于自己的“通用大脑”,构建智能基础设施。
参考文献
• Hugging Face - huggingface.co
• Qwen3-4B-Instruct-2507 模型主页 - huggingface.co
• Kubernetes 官网 - kubernetes.io
🔗 更多精彩内容
• 🌐 个人网站:jimmysong.io
• 🎥 Bilibili:space.bilibili.com/31004924
💫 如果这篇文章对你有帮助,欢迎点赞、分享给更多朋友!

















 1249
1249

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









