







一、前言背景:
目前大数据时代,传统关系型数据库不可或缺,但是早不足以支撑后续数据存储应用工作,在项目初期都是仅采用mysql数据库作为业务数据库,但是随着数据的增长,当单表的数据超过千万级后,在怎么对查询SQL语句进行优化性能都不理想。这种情况下,我们就可以考虑通过ES来实现项目的读写分离:写操作对Mysql库进行操作,读操作采用ElasticSearch。那么我们应该如何保证ES和Mysql的数据同步呢?
本博主考虑了几种方案:
第一种是Alibaba的开源神器Canal。
第二种是本文通过Logstash实现mysql数据定时增量同步到ElasticSearch。本博主选择第二种解决方案,因为Logstash为Elastic Stack(技术栈)中的其中一员,同时为ELK中重要一员。兼容性,操作简便性,肯定是官方集成作为合适,所以本博主选择使用Logstash作为数据同步的中间件。
Logstash介绍
Logstash是一个数据收集处理转发系统,最常用于ELK中作为日志收集器使用,是 Java开源项目。 它只做三件事:
数据输入(Input):常见File、syslog、redis、beats(如:Filebeats)、Kafka、MySql。
数据加工(Filter):(不是必须的):如过滤,改写等
eg:转变参数类型 convert,复制字段 copy,正则表达式替换 gsub,大小写转换 lowercase,字段重命名 rename,增加字段 add_field等......
数据输出(Output):Elasticsearch、Kafka、console
一、系统配置
在本篇文章中,我使用下列产品进行测试:
MySQL:5.7Elasticsearch:6.5.1Logstash:6.5.1Java:1.8.0_191-b12JDBC连接器驱动:mysql-connector-java-5.1.31.jar上述Mysql版本和驱动器连接版本保持一致,ElasticSearch 需要JDK1.8以上的版本支撑,并且
Logstash的版本需要和ElasticSearch版本保持一致。
二、环境搭建
安装Mysql数据库环境,创建MySql需要同步的表结构
表名:wx_test
CREATE TABLE `wx_test` (
`id` int NOT NULL AUTO_INCREMENT COMMENT '唯一id',
`outpost_uid` int NULL DEFAULT NULL COMMENT '用户id',
`create_time` datetime NULL DEFAULT NULL COMMENT '通过时间',
`apply_open_id` varchar(255) ,
`scan_result` int NULL DEFAULT NULL,
`reason` varchar(255) ,
`phone` varchar(255),
`tz_place_id` varchar(255) ,
`address_id` int NULL DEFAULT NULL,
`u_id` int NULL ,
PRIMARY KEY (`id`) USING BTREE,
INDEX `create_time`(`create_time` ASC) USING BTREE,
INDEX `phone`(`phone` ASC) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 223989 CHARACTER SET = utf8 COLLATE = utf8_general_ci COMMENT = '前哨记录' ROW_FORMAT = DYNAMIC;
SET FOREIGN_KEY_CHECKS = 1;安装ElasticSearch环境,创建ElasticSearch结构Mapping,用来支援后续海量全文检索的服务应用。
Mapping 结构如下,同时ES索引的名字和MySql表名不需要一致,博主为了方便写为相同。
PUT http://ip:9200/wx_test
{
"settings": {
"number_of_shards": 3,
"number_of_replicas": 1
},
"mappings": {
"doc": {
"dynamic": "false",
"properties": {
"id": {
"type": "keyword",
"index": "true"
},
"outpost_uid": {
"type": "keyword",
"index": "true"
},
"create_time": {
"type": "date",
"format" : "yyyy-MM-dd HH:mm:ss||epoch_second"
},
"apply_open_id": {
"type": "text",
"index": "false"
},
"scan_result": {
"type": "text"
},
"reason": {
"type": "text"
},
"phone": {
"type": "keyword"
},
"tz_place_id": {
"type": "keyword",
"index": "true"
},
"address_id": {
"type": "keyword",
"index": "true"
}
}
}
}
}上述ES和MySql下载完毕后,启动下载Logstash组件,下载地址如下:
 https://www.elastic.co/cn/downloads/past-releases#logstash
https://www.elastic.co/cn/downloads/past-releases#logstash
本博主的Logstash下载连接
链接:https://pan.baidu.com/s/1C_-oIAhj6VUQFMDeBnhcBA
提取码:h26v
下载完毕后,上传服务器,解压,将需要同步的Mysql数据库的驱动,拷贝到Logstash的文件夹下面,如下图所示: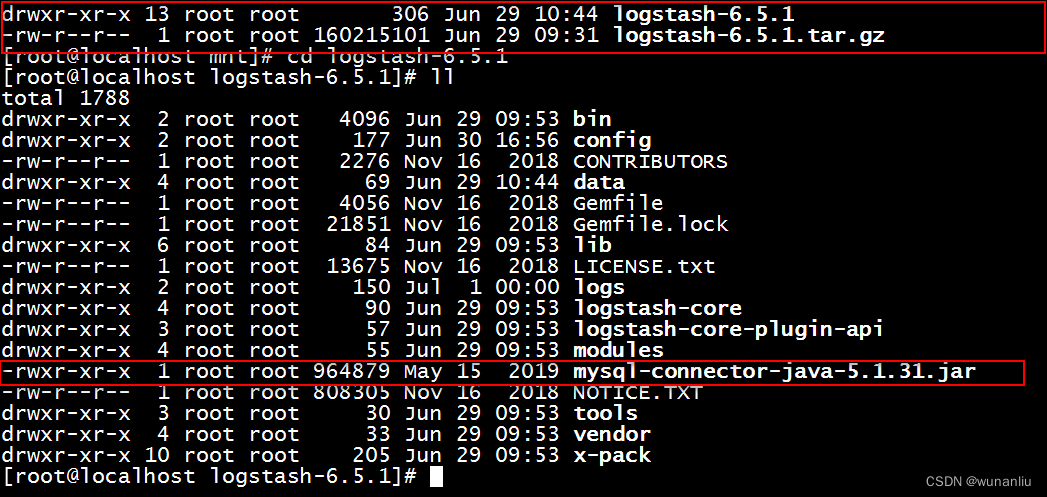
三、使用配置Logstash
MySql数据同步进入ElasticSearch服务
在Logstash目录的config文件下创建mysql.conf,配置文件内容如下:
#logstash 数据处理流程,分为input,filter,output 三步骤。
input {
jdbc {
#jdbc连接的驱动地址
jdbc_driver_library => "/mnt/logstash-6.5.1/mysql-connector-java-5.1.31.jar"
#jdbc驱动类
jdbc_driver_class => "com.mysql.jdbc.Driver"
#mysql的连接地址
jdbc_connection_string => "jdbc:mysql://ip:3306/databases"
#mysql账号的用户名
jdbc_user => "root"
#mysql 账号的密码
jdbc_password => "123456"
#是否开启分页
jdbc_paging_enabled => true
#需要记录查询结果某字段的值时,此字段为true
use_column_value=>true
#需要记录的字段,用于增量同步 此处ID为当前表增量的ID ,自增主键。
tracking_column=> "id"
#增量对应字段类型,类型只有numeric(数字类型)和timestamp(时间戳)字段的类型只能选择,默认
#numeric类型,所以可以不写这个配置
tracking_column_type=>"numeric"
#记录上一次运行的记录,(主键增量id记录在文件中)
record_last_run=>true
#上一次运行记录存储的文件位置(文件加载的是主键增量id)
last_run_metadata_path=>"/mnt/logstash-6.5.1/config/jdbc_demo"
#是否清除last_run_metadata_path 的记录,需要增量同步时此字段必须为false
clean_run=>false
#设置时区,如果设置会将 last_modify_time 增加8小时
#jdbc_default_timezone=>"Asia/Shanghai"
#同步频率(分 时 天 月 年) 默认每分钟同步一次
schedule => "* * * * *"
#是否将字段名称转换为小写。默认转换,因为ES是区分大小写的
lowercase_column_names=>false
#第一种增量方式,基于主键,sql_last_value值为,数据存储在last_run_metadata_path 的文件目录下的记录数据,一般为上次运行的主键id,其中create_time被在Sql中进行了转化,应为不转换,数据进入ES存在时间查询展示等问题。
statement => "SELECT id,outpost_uid,DATE_FORMAT(create_time,'%Y-%m-%d %H:%i:%s') as create_time,apply_open_id,scan_result,reason,phone,tz_place_id,address_id FROM wx_outpost_scan WHERE id >:sql_last_value"
#第二种增量方式,基于时间来做增量,不如主键增量好。比如两个数据组件中服务器,时间存在插值,问题,当前数据同步会存在问题
#statement => "SELECT id,outpost_uid,DATE_FORMAT(create_time,'%Y-%m-%d %H:%i:%s') as create_time,apply_open_id,scan_result,reason,phone,tz_place_id,address_id FROM wx_outpost_scan WHERE create_time > :sql_last_value AND create_time < NOW() ORDER BY create_time desc"
}
}
#数据过滤层,下列移除掉"@timestamp","@version" 两个字段,因为使用logstash进行数据同步,会存在多2个字段,用不上,可以移除。
filter {
#数据过滤,因为数据进入ES会添加两个字段,此处避免垃圾数据,所以移除这两个字段
mutate{
remove_field=>["@timestamp","@version"]
}
}
#输出结果,当前输出结果为到ElasticSearch中,指定Index和文档主键id
output {
# 采用stdout可以将同步数据输出到控制台,主要是调试阶段使用
stdout { codec => "rubydebug"}
#数据进入ES
elasticsearch {
hosts => "ip:9200"
#hosts => ["127.0.0.1:9200","127.0.0.2:9200"]
index => "wx_test"
document_id => "%{id}"
}
}启动Logstash,并且查看数据是否同步完成。
启动命令:
正常启动运行:./logstash -f ../config/mysql.conf
后台启动运行:nohup ./logstash -f ../config/mysql.conf &
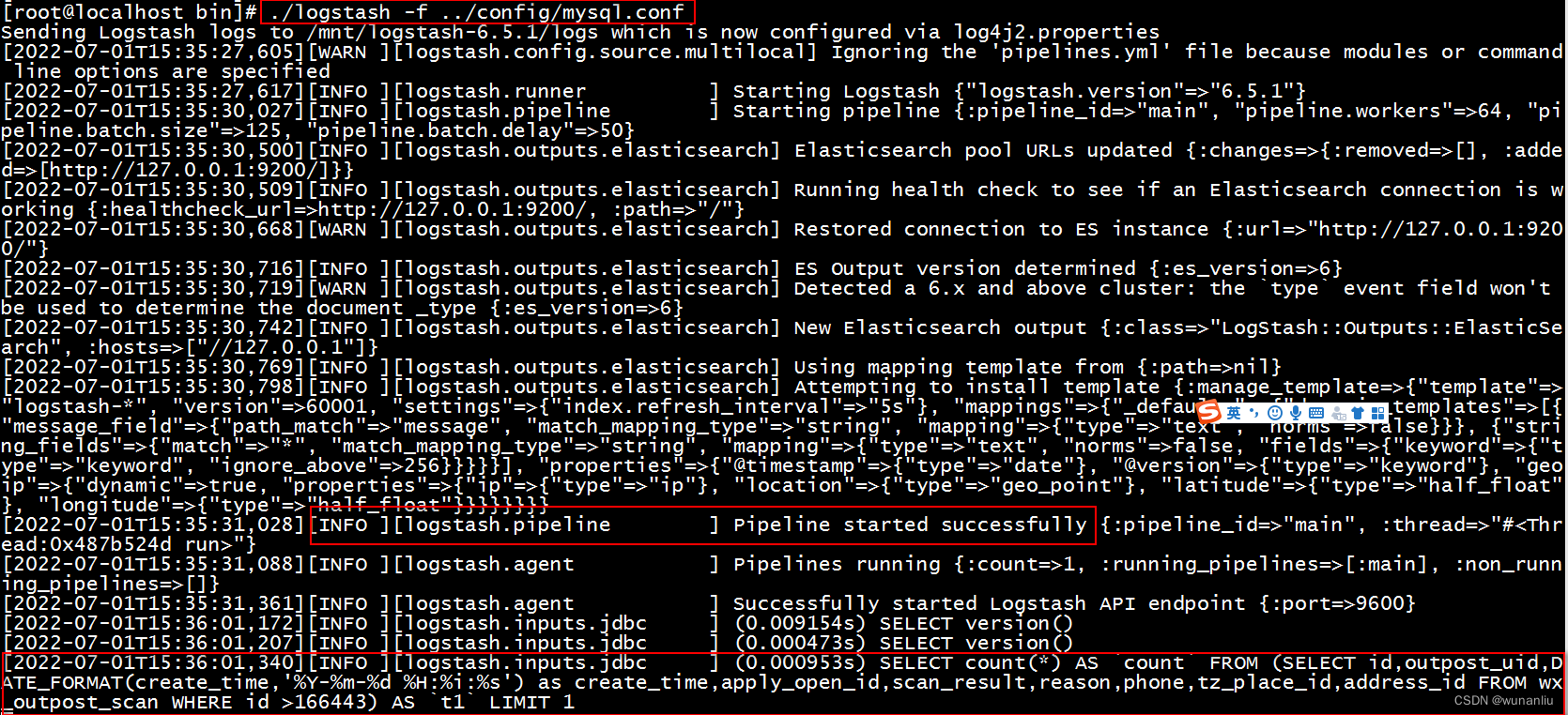
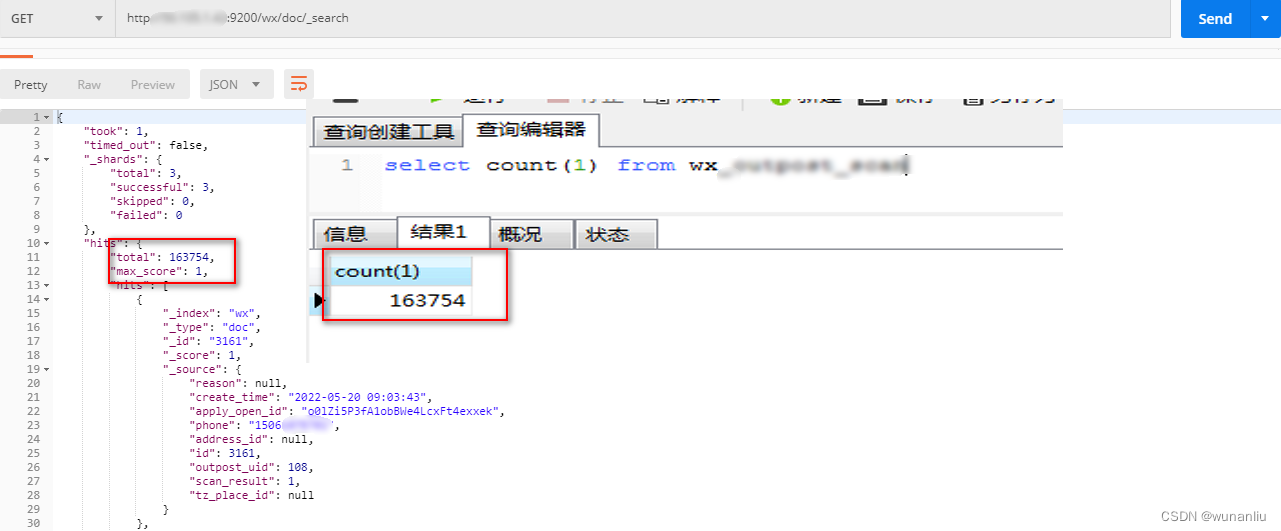
查看Mysql和ElasticSearch数据同步结果:
MySql 数据同步到 Kafka配置文件
input {
jdbc {
# 驱动jar包的位置
jdbc_driver_library => "/usr/local/logstash/jdbc-driver-library/mysql-connector-java-8.0.19.jar"
# 驱动类名
jdbc_driver_class => "com.mysql.cj.jdbc.Driver"
# 数据库连接
jdbc_connection_string => "jdbc:mysql://127.0.0.1:3306/test?characterEncoding=utf8&autoReconnect=true&serverTimezone=Asia/Shanghai&zeroDateTimeBehavior=convertToNull"
# mysql用户名
jdbc_user => "root"
# mysql密码
jdbc_password => "123456"
# 数据库重连尝试次数
connection_retry_attempts => "3"
# 开启分页查询(默认false不开启)
jdbc_paging_enabled => true
# 单次分页查询条数(默认100000,若字段较多且更新频率较高,建议调低此值)
jdbc_page_size => "2"
# 如果sql较复杂,建议配通过statement_filepath配置sql文件的存放路径;
statement_filepath => "/usr/local/logstash/sql/t_sys_loginperson.sql"
# 需要记录查询结果某字段的值时,此字段为true
use_column_value => true
# 需要记录的字段,用于增量同步
tracking_column => "last_modify_time"
# 字段类型
tracking_column_type => "timestamp"
# 记录上一次运行记录
record_last_run => true
# 上一次运行记录值的存放文件路径
last_run_metadata_path => "/mnt/t_sys_loginperson.txt"
# 是否清除last_run_metadata_path的记录,需要增量同步时此字段必须为false
clean_run => false
# 设置时区 如果设置会将 last_modify_time 增加8小时
#jdbc_default_timezone => "Asia/Shanghai"
# 同步频率(分 时 天 月 年),默认每分钟同步一次;
schedule => "* * * * *"
}
}
filter {
mutate {
# 删除字段
remove_field => ["@timestamp","@version"]
}
}
output {
kafka {
bootstrap_servers => "192.168.0.1:9092"
topic_id => "kafka-001"
codec => "json"
client_id => "kafkaOutPut"
}
} Kafka 数据到 Elasticsearch
input {
kafka {
bootstrap_servers => "10.10.6.202:9092"
client_id => "kafkaInPut"
#从最新一条开始读取
auto_offset_reset => "latest"
#消费线程,一般是这个队列的partitions数
consumer_threads => 3
decorate_events => true
#队列名称
topics => ["base-db"]
codec => "json"
}
}
filter {
mutate {
# 删除字段
remove_field => ["@timestamp","@version"]
}
}
output {
elasticsearch {
hosts => "10.10.6.202:9200"
index => "%{index_name}"
document_id => "%{id}"
}
}多个pipeline数据同步文件配置:
配置pipelines.yml
vi /usr/local/logstash/config/pipelines.yml
- pipeline.id: mysql
pipeline.workers: 1
pipeline.batch.size: 100
path.config: "/usr/local/logstash/customize-config/mysql2kafka.conf"
- pipeline.id: es
queue.type: persisted
path.config: "/usr/local/logstash/customize-config/kafka2elasticsearch.conf"启动
#无需指定配置文件,默认走pipelines.yml的配置,如果使用-e或-f时,Logstash会忽略pipelines.yml文件
nohup /usr/local/logstash/bin/logstash > /dev/null 2>&1 &==================================完结==================================
mutate过滤器使用的相关函数如下:
mutate过滤器能够帮助你修改指定字段的内容。
该过滤器指定配置:
mutate {
}
具体参数配置如下:
转变参数类型 convert
mutate {
convert => {
"name" => "string"
"age" => "integer"
}
}
2、复制字段 copy
复制一个已存在的字段到另外一个字段,已存在的字段会被重写到一个新的字段,新的字段不需要单独添加
mutate {
copy => {"name" => "name2"}
}
3、正则表达式替换 gsub
这里只针对string类型字段,如下把name字段中的“o”替换为“p”
mutate {
gsub => ["name","o","p"]
}
4、大小写转换 lowercase&uppercase
mutate {
#lowercase => [ "name" ]
uppercase => [ "name" ]
}
5、字段重命名 rename
mutate {
rename => {"name" => "name3"}
}
6、除去字段值前后空格 strip
mutate {
strip => ["name"]
}
7、更新字段值 update
mutate {
update => {"name" => "li"}
}
8、修改字段 replace
作用和 update 类似,但是当字段不存在的时候,它会起到 add_field 参数一样的效果,自动添加新的字段。
9、移除字段 remove_field
mutate {
remove_field => ["name"]
}
10、增加字段 add_field
mutate {
add_field => {"testField1" => "0"}
add_field => {"testField2" => "%{name}"} #引用name中的值
}
















 393
393

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









