







select模型
三个功能:
- 监控
- 添加描述符
- 移除描述符
通过对大量事件集合中的描述符阻塞进行各自的事件监控;
当对应集合中有描述符事件就绪/超时则返回事件就绪,描述符当前可读/可写/异常;
返回之前将集合中没有就绪的描述符全部删除;
int select(int nfds, fd_set* readfds, fd_set* writefds, fd_set* exceptfds, struct timeval* timeout);
nfds:等于监控的描述符中,最大的那个描述符+1;
fd_set:描述符集合
readfds:读事件集合
writefds:写事件集合
exceptfds:异常事件集合
timeout:select等待的超时时间
返回值:
小于0—>监控出错
等于0—>等待超时
大于0—>当前有多少个描述符就绪
1、定义fd_set:
描述符集合(是一个位图,位图大小取决于_FD_SETSIZE = 1024)
2、监控:
将集合拷贝到内核进行监控,监控的原理是对所有的描述符进行轮询遍历状态;
3、移除操作符
当有描述符就绪的时候,在调用返回之前将集合中没有就绪的描述符剔除出去;
4、用户操作:
对所有的描述符进行遍历,查看哪一个还在集合中,那么这个描述符就已经就绪
void FD_CLR(int fd, fd_set* set); //将指定的描述符在集合中移除
int FD_ISSET(int fd, fd_set* set); //判断指定的描述符是否在集合中
void FD_SET(int fd, fd_set* set); //将指定的描述符添加到监控集合中
void FD_ZERO(fd_set* set); //清空描述符集合
优点:
- select遵循POSIX,可以跨平台——移植性强
- 监控的超时时间更加精细——微秒
缺点:
- 所能监控的描述符是有上限的(默认:1024,取决于_FD_SETSIZE = 1024)
- select实现监控原理是在内核中进行轮询遍历状态,因此性能会随着描述符增多而下降
- select每次监控返回时会修改描述符集合(移除未就绪的描述符),需要每次监控时重新添加到描述符集合中
- select要监控的集合中的描述符数据,需要每次重新向内核中拷贝
- 不会告诉用户哪一个描述符就绪,只是告诉用户有就绪事件,需要用户遍历查找
poll模型:
poll本质上和select没有区别;
int poll(struct pollfd *fds, nfds_t nfds, int timeout)
fds:事件数组
nfds:监控事件个数
timeout:超时等待时间
监控实现原理:
1.用户定义一个事件数组,对描述符可以添加关心的事件,进行监控;
// pollfd结构
struct pollfd {
int fd; /* 用户监控的文件描述符 */
short events; /* 保存用户关心的事件 */
/*(POLLIN / POLLOUT)*/
short revents; /* 保存当前就绪事件 */
};
2.poll实现监控的原理也是将事件结构拷贝到内核,然后进行轮询遍历监控,性能随着描述符的增多而下降;
3.若有描述符就绪,则修改这个响应描述符事件结构中的实际就绪事件
4.用户根据返回的revents判断哪一个事件就绪,然后进行操作即可
5.poll也不会告诉用户哪一个描述符就绪,只是告诉用户有就绪事件,需要用户遍历查找
优点:
- 采用事件结构的方式对描述符进行监控,简化了多个事件集合的监控方式
- 没有描述符的具体监控上限
缺点:
- 不能跨平台
- poll采用轮询遍历的方式判断就绪,性能随着描述符的增多而下降
- 不会告诉用户哪一个描述符就绪,只是告诉用户有就绪事件,需要用户遍历查找
epoll模型
基础知识
epoll是在2.6内核中提出的,是之前的select和poll的增强版本。
相对于select和poll来说,epoll更加灵活,没有描述符限制。
epoll使用一个文件描述符管理多个描述符,将用户关系的文件描述符的事件存放到内核的一个事件表中,这样在用户空间和内核空间的copy只需一次。
epoll接口
epoll操作过程需要三个接口,分别如下:
#include <sys/epoll.h>
int epoll_create(int size);
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
int epoll_wait(int epfd, struct epoll_event * events, int maxevents, int timeout);
1、int epoll_create(int size);
创建一个epoll的句柄,size用来告诉内核这个监听的数目一共有多大。这个参数不同于select()中的第一个参数,给出最大监听的fd+1的值。需要注意的是,当创建好epoll句柄后,它就是会占用一个fd值,在linux下如果查看/proc/进程id/fd/,是能够看到这个fd的,所以在使用完epoll后,必须调用close()关闭,否则可能导致fd被耗尽。
2、int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
epoll的事件注册函数,它不同与select()是在监听事件时告诉内核要监听什么类型的事件epoll的事件注册函数,它不同与select()是在监听事件时告诉内核要监听什么类型的事件,而是在这里先注册要监听的事件类型。
第一个参数是epoll_create()的返回值;
第二个参数表示动作,用三个宏来表示:
- EPOLL_CTL_ADD:注册新的fd到epfd中;
- EPOLL_CTL_MOD:修改已经注册的fd的监听事件;
- EPOLL_CTL_DEL:从epfd中删除一个fd;
第三个参数是需要监听的fd;
第四个参数是告诉内核需要监听什么事;
struct epoll_event结构如下:
struct epoll_event {
__uint32_t events; /* Epoll events */
epoll_data_t data; /* User data variable */
};
events可以是以下几个宏的集合:
EPOLLIN :表示对应的文件描述符可以读(包括对端SOCKET正常关闭);
EPOLLOUT:表示对应的文件描述符可以写;
EPOLLPRI:表示对应的文件描述符有紧急的数据可读(这里应该表示有带外数据到来);
EPOLLERR:表示对应的文件描述符发生错误;
EPOLLHUP:表示对应的文件描述符被挂断;
EPOLLET: 将EPOLL设为边缘触发(Edge Triggered)模式,这是相对于水平触发(Level Triggered)来说的。
EPOLLONESHOT:只监听一次事件,当监听完这次事件之后,如果还需要继续监听这个socket的话,需要再次把这个socket加入到EPOLL队列里
3、int epoll_wait(int epfd, struct epoll_event * events, int maxevents, int timeout);
等待事件的产生,类似于select()调用。参数events用来从内核得到事件的集合,maxevents告之内核这个events有多大,这个maxevents的值不能大于创建epoll_create()时的size,参数timeout是超时时间(毫秒,0会立即返回,-1将不确定,也有说法说是永久阻塞)。该函数返回需要处理的事件数目,如返回0表示已超时。
工作模式
epoll对文件描述符的操作有两种模式:
- LT(level trigger)(水平触发)
- ET(edge trigger)(边缘触发)
水平触发
LT(level triggered)是缺省的工作方式,并且同时支持block和no-block socket.在这种做法中,内核告诉你一个文件描述符是否就绪了,然后你可以对这个就绪的fd进行IO操作。如果你不作任何操作,内核还是会继续通知你的,所以,这种模式编程出错误可能性要小一点。传统的select/poll都是这种模型的代表。
- 优点:
当进行socket通信的时候,保证了数据的完整输出,进行IO操作的时候,如果还有数据,就会一直的通知你。 - 缺点:
由于只要还有数据,内核就会不停的从内核空间转到用户空间,所有占用了大量内核资源,试想一下当有大量数据到来的时候,每次读取一个字节,这样就会不停的进行切换。内核资源的浪费严重。效率来讲也是很低的。
边缘触发
ET(edge-triggered)是高速工作方式,只支持no-block socket。在这种模式下,当描述符从未就绪变为就绪时,内核通过epoll告诉你。然后它会假设你知道文件描述符已经就绪,并且不会再为那个文件描述符发送更多的就绪通知。
请注意,如果一直不对这个fd作IO操作(从而导致它再次变成未就绪),内核不会发送更多的通知(only once)。
- 优点:
每次内核只会通知一次,大大减少了内核资源的浪费,提高效率。 - 缺点:
不能保证数据的完整。不能及时的取出所有的数据。
应用场景: 处理大数据。使用non-block模式的socket。
由于不会重复触发,所以我们要循环读取数据,以确保把socket读缓存的所有数据取出。
原理解释
epoll可以理解为event poll,不同于忙轮询和无差别轮询,epoll之会把哪个流发生了怎样的I/O事件通知我们。此时我们对这些流的操作都是有意义的。(复杂度降低到了O(1))
在讨论epoll的实现细节之前,先把epoll的相关操作列出:
1、epoll_create 创建一个epoll对象,一般:
epollfd = epoll_create()
2、epoll_ctl (epoll_add/epoll_del的合体),往epoll对象中增加/删除某一个流的某一个事件
比如:
epoll_ctl(epollfd, EPOLL_CTL_ADD, socket, EPOLLIN);//注册缓冲区非空事件,即有数据流入
epoll_ctl(epollfd, EPOLL_CTL_DEL, socket, EPOLLOUT);//注册缓冲区非满事件,即流可以被写入
3、epoll_wait(epollfd,…)等待直到注册的事件发生
epoll_wait(epollfd,...);
(注:当对一个非阻塞流的读写发生缓冲区满或缓冲区空,write/read会返回-1,并设置errno=EAGAIN。而epoll只关心缓冲区非满和缓冲区非空事件)。
一个epoll模式的代码大概的样子是:
while(true)
{
active_stream[] = epoll_wait(epollfd)
for i in active_stream[]
{
read or write till
}
}
总结:

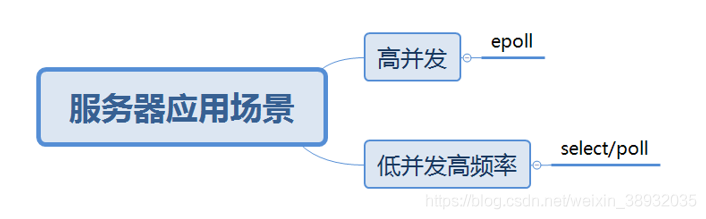
综上,在选择select,poll,epoll时要根据具体的使用场合以及这三种方式的自身特点。
1、表面上看epoll的性能最好,但是在连接数少并且连接都十分活跃的情况下,select和poll的性能可能比epoll好,毕竟epoll的通知机制需要很多函数回调。
2、select低效是因为每次它都需要轮询。但低效也是相对的,视情况而定,也可通过良好的设计改善














 388
388











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









