







用python写爬虫爬取图片可谓是无数python学习者初试牛刀的作品,由于python拥有大量便捷好用的库,python初学者甚至毫无编程基础的人都可以简单地写出一个用于爬取图片的爬虫,并从中获得部分满足感。
安装python及所需的库
我使用的版本是python3.6.5,下载地址:https://www.python.org/downloads/
requests:解析url
beautifulsoup4:不会正则表达式童鞋的福音,可以容易的提取到html文件中各种标签及其属性
安装方法: 在Windows的cmd下输入以下指令
pip install requests
pip install beautifulsoup4
获取并分析网页源代码
专业人员会通过如wireshark等专业工具抓包获取大量信息,不过我们不用这么麻烦,在浏览器中,我们可以使用F12查看网页代码,我们的目标网址是https://www.1326x.com/Html/61/index.html,如果我们学习过一些简单的web,html的东西,便可以分析得出我们想要的图片的URL。
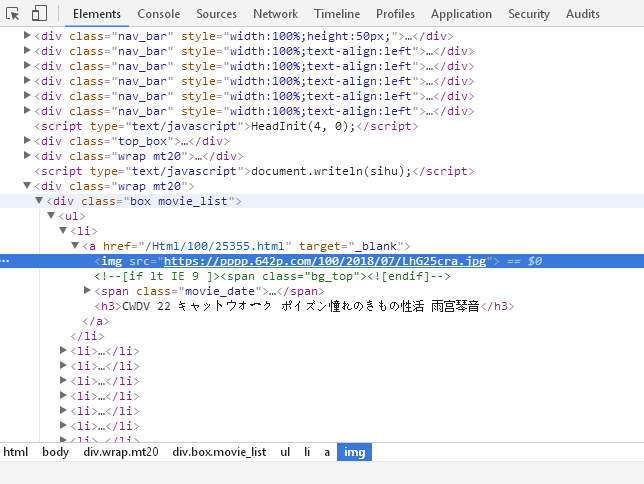
我们使用Request(url)生成Request对象,用urlopen()打开Request中的url网址并获得其内容,然后用html= response.read().decode('gbk', 'ignore')对其进行解析,gbk是编码格式,这里我们只识别gbk编码的部分,忽略无法识别的。最后用html_soup = BeautifulSoup(html,'lxml')生成BeautifulSoup对象,BeautifulSoup的引入使我们不用去管复杂的正则表达式,可以轻松从中提取想要的信息。用pic_url = element['src']就可以从上图的HTML中获取img的url。
这里有关于requests,urllib,BeautifulSoup,正则表达式的相关资料:
requests urllib BeautifulSoup 正则表达式
当然在这之前,我们最好设置一个header来模拟登陆网址。
header = {
'User-Agent': 'Mozilla/5.0 (Linux; Android 4.1.1; Nexus 7 Build/JRO03D) AppleWebKit/'
'535.19 (KHTML, like Gecko) Chrome/18.0.1025.166 Safari/535.19'
}
url = "https://www.1326w.com/Html/61/index.html"
req = urllib.request.Request(url)
response = urllib.request.urlopen(req)
html = response.read().decode('gbk', 'ignore')
html_soup = BeautifulSoup(html,'lxml')
pic_url = element['src']
print(pic_url)
pic = requests.get(pic_url)将图片下载到本地
这里我们只需要利用OS库中写文件的方法即可将图片写入指定文件夹。
print(pic_url)
pic = requests.get(pic_url)
file_name = "mzt/"+str(x)+".jpg" #拼接图片名
print(file_name)
#将图片存入本地
fp = open(file_name,'wb')
fp.write(pic.content) #写入图片
fp.close()最后我们对代码进行面向对象的处理并且循环,就可以成功下载图片了。
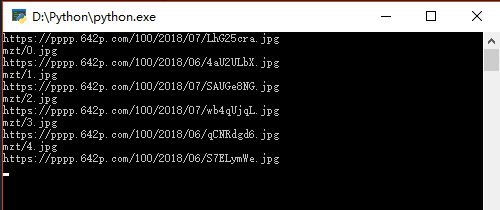
运行结果:
整体代码:
from bs4 import BeautifulSoup
import re
import sys
import urllib
import os
import requests
from urllib import request
#def download_picpage(page_url, header):
#download_req = request.Request(pic_url,header)
#response = request.urlopen(download_req)
def gethtml(page_url , headers):
req = urllib.request.Request(page_url)
#先生成一个request对象,传入url
response = urllib.request.urlopen(req)
#通过指定urlopen打开request对象中的url网址,并获得对应内容
html = response.read().decode('gbk', 'ignore')
#获取页面的html
the_html_soup = BeautifulSoup(html,'lxml')
#获取html的bs
return the_html_soup
def download(html_soup , pic_num):
pic_url = element['src']
#获取图片url
print(pic_url)
pic = requests.get(pic_url)
#下载图片
file_name = "mzt/"+str(pic_num)+".jpg"
#拼接图片名
print(file_name)
fp = open(file_name,'wb')
#将图片存入本地
fp.write(pic.content)
#写入图片
fp.close()
if __name__ == '__main__':
header = {
'User-Agent': 'Mozilla/5.0 (Linux; Android 4.1.1; Nexus 7 Build/JRO03D) AppleWebKit/'
'535.19 (KHTML, like Gecko) Chrome/18.0.1025.166 Safari/535.19'
}
purl = "https://www.1326w.com/Html/61/index-"
url1 = "https://www.1326x.com/Html/61/index.html"
#首页url
x = 0
for i in range(0,128):
if i == 0:
html_soup = gethtml(url1 , headers=header)
elif i == 1:
continue
else:
url = purl + str(i) + ".html"
#拼接本页URL
print(url)
#gethtml(url)
html_soup = gethtml(url , headers=header)
for element in html_soup.find_all('img'):
download(html_soup , x)
x += 1













 622
622











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









