







1. 介绍机器学习
- 了解掌握ML优势
- 理解ML背后理念
-----------------------------------------------------------------------
2. 框架处理
探讨如何将某个任务构建为ML问题,并介绍各种ML方法中通用基本词语。
监督学习supervised learning
-------------------------------------------------------
标签label
在简单线性回归中,标签是我们要预测的事物,即 y 变量。
标签可以是小麦未来的价格、图片中显示的动物品种、音频剪辑的含义或任何事物。
-------------------------------------------------------
特征feature
在简单线性回归中,特征是输入变量,即x变量。
简单的机器学习项目可能会使用单个特征,而比较复杂的机器学习项目可能会使用数百万个特征。
例:在垃圾邮件检测器示例中,特征可能包括:
- 电子邮件文本中的字词
- 发件人的地址
- 发送电子邮件的时段
- 电子邮件中包含“一种奇怪的把戏”这样的短语。
- -------------------------------------------------------
样本
样本是指数据的特定实例x。(我们采用粗体x表示它是一个矢量。)我们将样本分为以下两类:
- 有标签样本
- 无标签样本
有标签样本同时包含特征和标签。即: labeled examples: {features, label}: (x, y)
我们使用有标签样本来训练模型。在我们的垃圾邮件检测器示例中,有标签样本是用户明确标记为“垃圾邮件”或“非垃圾邮件”的各个电子邮件。
无标签样本包含特征,但不包含标签。即:unlabeled examples: {features, ?}: (x, ?)
在使用有标签样本训练模型后,使用该模型来预测无标签样本的标签。
例:在垃圾邮件检测器中,无标签样本是用户尚未添加标签的新电子邮件。
-------------------------------------------------------
模型modle
模型定义了特征与标签之间的关系。例:垃圾邮件检测模型可能会将某些特征与“垃圾邮件”紧密联系起来。
我们来重点介绍一下模型生命周期的两个阶段:
训练表示创建或学习模型
推断表示将训练后的模型应用于无标签样本
-------------------------------------------------------
回归与分类
- 回归模型可预测连续值
- 分类模型可预测离散值
-------------------------------------------------------
3. 深入了解ML
线性回归是一种找到最适合一组点的直线或超平面的方法。本节会先直观介绍线性回归,为介绍线性回归的机器学习方法奠定基础。
(1)线性回归
对于简单的线性回归,关系写下来为:y = mx + b
其中:
- y y是我们试图预测的值。
- mm是直线的斜率。
- x x是输入特征的值。
- b b是y轴截距。
按照机器学习惯例,需要写一个存在细微差别的模型方程式:y' = b + w1x1
其中:
- y′ y'是预测标签(理想输出值)。
- b b指的是偏差(y轴截距)在一些机器学习文档中,它称为w0w0。
- w1w1指的是特征1的权重。权重与上文中用m表示的“斜率”的概念相同。
- x1x1指的是特征(已知输入项)。
- -------------------------------------------------------
- (2)训练与损失
简单来说,训练模型表示通过有标签样本来学习(确定)所有权重和偏差的理想值。
监督式学习中,ML算法通过以下方式构建模型:检查多个样本并尝试找出可最大限度地减少损失的模型;这一过程称为经验风险最小化。
损失是对糟糕预测的惩罚。也就是说,损失是一个数值,表示对于单个样本而言模型预测的准确程度。如果模型的预测完全准确,则损失为零,否则损失会较大。
训练模型的目标:从所有样本中找到一组平均损失“较小”的权重和偏差。
平方损失:一种常见的损失函数loss function
平方损失(又称为 L2 损失)的损失函数,单个样本平凡损失如下:
= the square of the difference between the label and the prediction
= (observation - prediction(x))2
= (y - y')2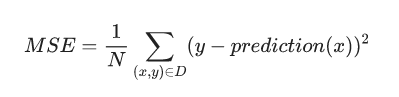
虽然MSE常用于ML,但它既不是唯一实用的损失函数,也不是适用于所有情形的最佳损失函数。
-------------------------------------------------------
以上整理转载在谷歌出品的机器学习速成课程点击打开链接 侵删!














 998
998











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









