








摘要
本文会讲清楚:
1)博弈搜索
2)MiniMax算法
3)Alpha-Beta剪枝算法
一、博弈搜索概念
在多Agent环境中(竞争环境),每个Agent的目标之间是有冲突的,所以就引出了对抗搜索(Adversarial search problems)(通常称为博弈)。
Games are a form of multi-agent environment. 人工智能中的博弈通常指博弈论专家们称为有完整信息的,确定性的,轮流行动的,两个游戏者的零和游戏(如象棋)。
由于在博弈问题中,搜索图(树)实在太大,A*搜索效率是很低的。在博弈搜索的算法中,剪枝允许我们在搜索树中忽略那些不影响最后决定的部分,启发式的评估函数允许在不进行完全搜索的情况下,估计某状态的真实效用值。
博弈问题的的6个元素:
1)
S0
S
0
:初始状态(游戏开始时的情况)
2)Player(s):定义此时该谁动
3)Actions(s):此状态下的合法移动集合
4)Result(s,a):转移模型,定义行动的结果
5)Terminal-test(s):终止测试,游戏结束返回真,否则假。
6)Utility(s,p):效用函数,定义游戏者p在终止状态s下的数值。 零和博弈是指所有棋手的收益之和在每个棋局实例中都相同。国际象棋中是0+1, 1+0或1/2+1/2。
二、MiniMax算法
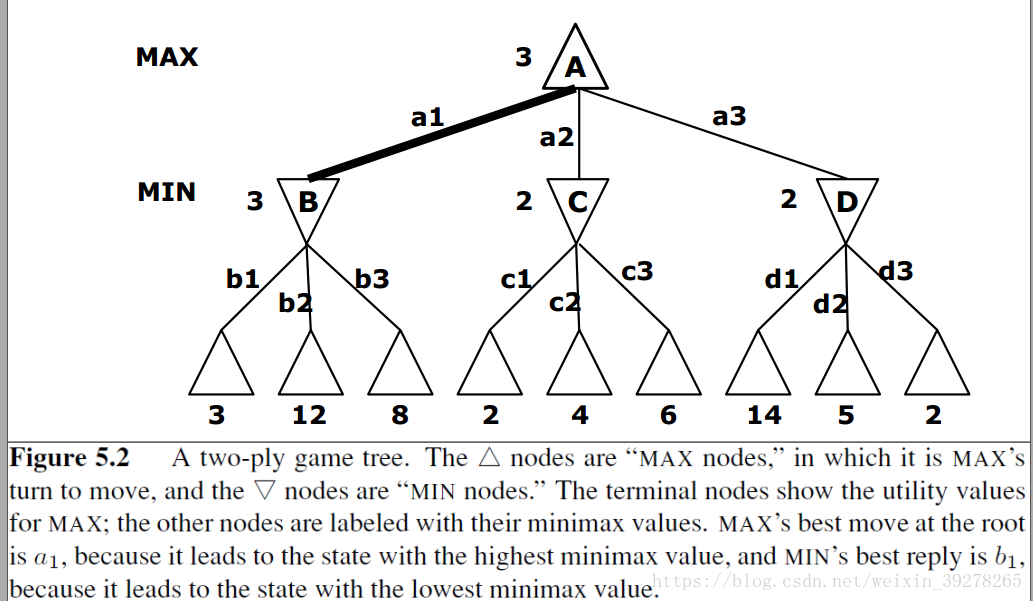
在该算法中,每个节点都有一个极小极大值,即为MiniMax(n)。Max始终想要最大的MiniMax值,Min始终想要最小的MiniMax值。
那么MiniMax(n)值怎么取呢,假设两个游戏者始终按照最优策略行棋,那么节点的极小极大值就是对应状态的效用值(Utility(s))。
极大极小算法:采用了简单的递归算法计算每个后继的极小极大值,直接实现上面公式的定义,递归算法自上而下一直前进到树的叶节点,然后随着递归回溯通过搜索树把极小极大值回传。
MiniMax算法对博弈树执行完整的深度优先搜索,如果树的最大深度是m,在每个节点合法的行棋有b个,时间复杂度: O(bm) O ( b m ) ,空间复杂度:O(bm)(一次性生成所有后继),O(m)(每次只生成一个后继)。 然而,对于真实的游戏,这样的时间开销完全不实用,但是此算法仍然可以作为对博弈进行数学分析和设计实验算法的基础。
2.2 多人博弈时的最优决策
比如说A,B,C三个人玩游戏,那么效用值就是一个向量
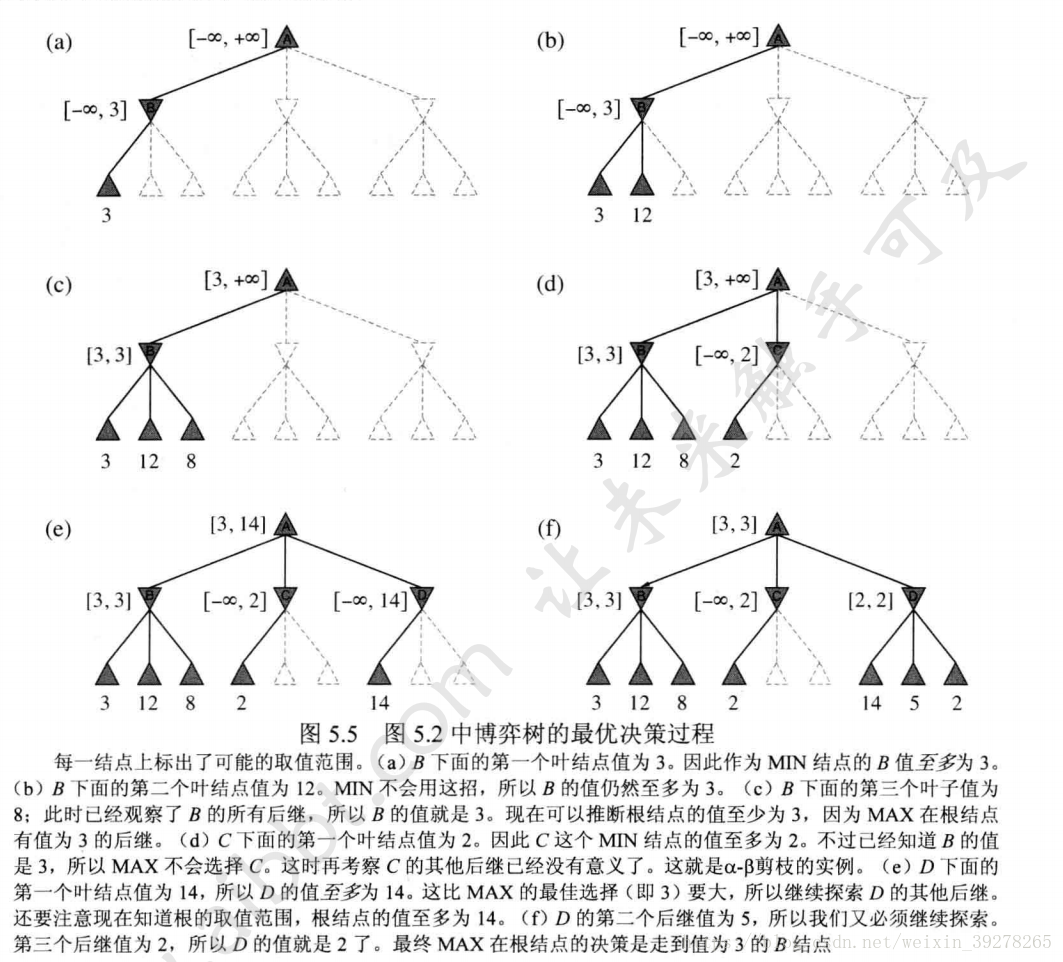
三、Alpha-Beta剪枝算法

四、文末诗词
晓看天色暮看云,行也思君,坐也思君。
——唐寅《一剪梅·雨打梨花深闭门》














 4616
4616











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









