







非参数模型(在AI 也叫作cased-based reasoning instance-based learning, case-based or memory-based)
非参数模型在相似度定义上不同,没有global model,local model 随着需要而估计,只受nearby 训练实例影响
不需要prior参数形式 复杂度取决于训练集的大小或者数据内部的复杂问题
非参数模型也成做实例-based 或者memory-based 学习算法
左右的训练实例存储O(N)的内存,根据所给输入找相似输出的计算量也是O(N),也称作lazy学习算法。不用马上计算模型,而是在给测试实例时在计算,缺点是对内存和计算能力的需求增加
相似输入有相似输出
非参数密度估计

- 对累积分布函数的非参数估计
- 对密度函数的非参数估计
h是tiny interval
直方估计
输入空间划分为等大小的intervals->bins,x0 原点,bin(宽度h)[xo + mh, xo + (m + 1)h),
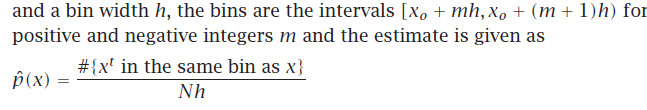
超参数-需要选择x0和h
x0原点->影响bins的near 边界估计
h->影响估计的smoothness,小bins,估计就spiky;大bins,估计更平滑
直方估计的优点是 一旦bin估计计算和存储,则无需保留训练集
不连续:如果在bin边界且估计值为0
Naive 估计器
(不用设置原点, x总是在bin的zise h 中心)两种写法:
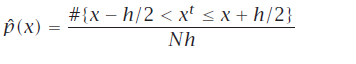
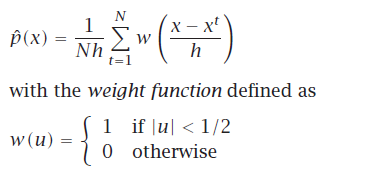
不连续 在
h
t
+
−
h
/
2
h^{t}+-h/2
ht+−h/2处跳跃,影响区域是0/1,非参数估计为sum of
x
t
x^{t}
xt的influence(包含x的区域)
每个x^{t}有对称region of influence(size h )around it 对于x落在该区域的贡献为1
Kernel 估计器
为了平滑估计,用平滑权重函数,kernel function

小h->每个实例在小范围内影响大
大h->更多kernel 的overlap,得到更平滑的估计
但是窗口宽度固定,需要自适应的方法。
K 临近估计
根据本地数据的密度适应平滑的数量
到neighbor的距离
类似于naive 估计:这里确定K,让实例都到bin里,计算bin的size(而不是确定h):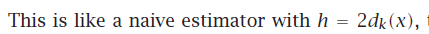
knn密度估计(不连续):
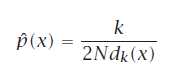
不平滑但可以用kernel function:
多元数据的泛化Generalization to Multivariate Data

- 非参数估计用在高维空间要小心维数灾难(curse of dimensionality)
- 高维中,close变得模糊,所以选择h很重要
- 欧式范数表明the kernel is scaled equally on all dimensions
- 不同scale的输入需要归一化使他们的variance相同
考虑correlations相关性,better results are achieved when the kernel has the same form as the underlying distribution,用样本协方差(sample covariance matrix)
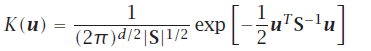
非参数分类
用非参数方法估计class-conditional densities, 后验=likelihood*先验

投票的权重由kernel function K(·)给出,closer 实例有更多的权重
特别的,KNN,K为奇数减少ties,把输入分到其k个邻居占的most examples 的class
k越小, variance越大, bias小;
k越大,var小,bias大。
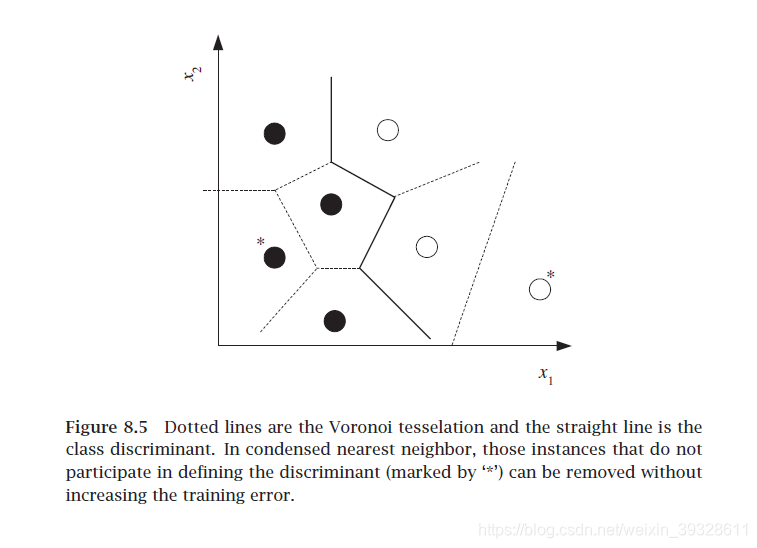
Voronoi tesselation:knn, k=1的特例
自适应的NN
适应度量通过向class 概率不变的方向伸展
高维空间中,类别分布可能只在低维子空间改变,因此自适应度量是很重要的优点
当在高维特征空间中做最近邻分类时,最近邻的点可以离得非常远,带来偏差,并且降低了分类器的效果.

一般地,这要求最近邻分类中采用自适应的度量,使得得到的邻域沿着类别不会改变太多的方向上拉伸.
不同的metric 在每查询query点使用,根据neighborhood的类别分布
在各类中计算covariance
判别自适应最近邻DNN:
在每个查询点,构造其大小为 50 个点的邻域,并且用这些点的类别分布来决定怎么对邻域进行变形——也就是,对度量进行更新.接着更新后的度量用在该查询点的最近邻规则中.因此每一个查询点都可能采用不同的度量.
假设一个局部判别模型,局部 类别内 (within-) 和 类别间 (between-) 协方差矩阵的信息就足以确定邻居的最优形状.
判别自适应最近邻DANN在查询点x0的度量定义:
 类内协方差W,类间协方差B
类内协方差W,类间协方差B
它首先将数据关于 W进行球面化,接着沿着 B*(球面化数据的类间方差)的零特征值方向拉伸邻域.参数 ϵ 围绕着邻域,从无穷的长条到椭球,避免使用离查询点过远的点.一般 ϵ=1 的效果很好.
- data 根据W球面化分布
- neighborhood延伸到B的零特征值方向
- 四舍五入邻域,从无限长条变为ellipsoid椭圆
- 邻域保持椭圆 在pure regions with 只有一类时(B=0,covariance矩阵是单位阵)
condensed NN
The core idea of the algorithm is that if the instance cannot be correctly classified by the currently selected set, the selected set is added.(CR: http://www.pudn.com/Download/item/id/3148619.html )
在不降低效果的情况下较少存储的实例数量 选最小的子集,用其替代原集合时误差不增加

是一种贪婪算法,目的是最小化训练误差和复杂度,用存储的subset大小来measure。寻找z,每个用存起来的z判断是否正确被1-nn分类,分裂错误则被加到z,直到z不变
是一种局部搜索,依赖训练实例出现的顺序,不保证找到最小consistent subset,NP完全问题。增广误差函数: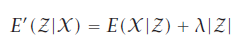
 第二项类似正则化项
第二项类似正则化项
原型方法 (prototype methods)
用特征空间中的点集来表示训练数据.这些原型通常不是训练样本的实例,除了后面讨论的 1-最近邻分类情形.
https://esl.hohoweiya.xyz/13-Prototype-Methods-and-Nearest-Neighbors/13.2-Prototype-Methods/index.html
每个原型有其对应的类别标签,并且将查询点
x分到“最近的”原型类别中.“最近的”通常是由特征空间中的欧氏距离定义的,在计算欧式距离前,需要将训练样本中的每个特征进行标准化后使其均值为 0,方差为 1.
K-means
- 对于每个类别,其它类的点对该类的原型所在位置没有影响.
- 很多原型靠近类别边界,导致离这些边界很近的点有潜在的误分类误差
更好的方式是用所有的数据确定原型的位置
learning Vector optimiazation量化学习向量
在 Kohonen(1989)1 的这种技术中,原型是按照 特定 (ad-hoc) 的策略放在判别边界上的.LVQ 是一种 online 的算法——每次处理一个观测值.
想法是训练点吸引正确类别的原型,同时排斥其它的原型.迭代完成时,原型应该与它们类别中的训练点很近.
学习速率 ϵ 随着每次迭代的进行降低至 0,遵循随机近似学习率的指导原则.

高斯混合模型(更加光滑)
也可以看成是原型方法,思想上类似K均值和LVQ
每个簇用高斯密度来描述,有一个形心(如在
K均值中一样),以及一个协方差矩阵.如果我们现在每个组分的高斯分布有标量化的协方差矩阵,这种比较变得更加清晰.轮流进行EM算法的过程与K均值中的两个步骤很类似.

https://esl.hohoweiya.xyz/13-Prototype-Methods-and-Nearest-Neighbors/13.2-Prototype-Methods/index.html














 1992
1992











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









