







线程模型
问题
redis是单线程还是多线程?
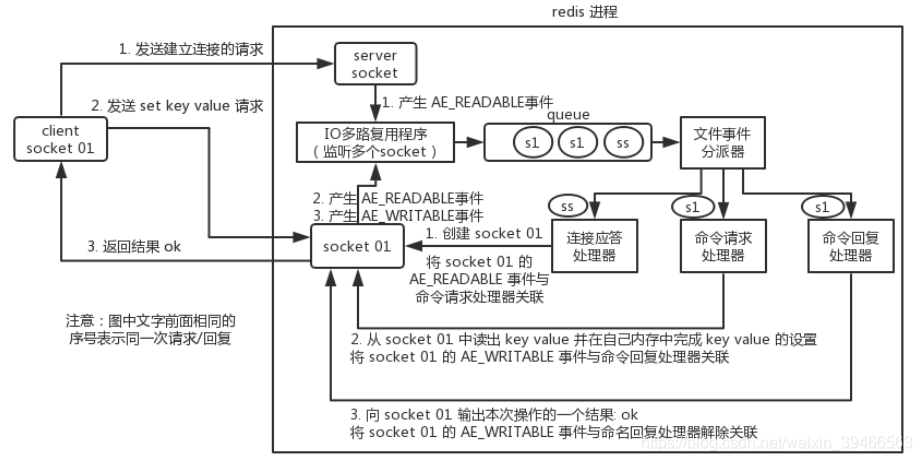
redis 内部使用文件事件处理器 file event handler,这个文件事件处理器是单线程的,所以 redis 才叫做单线程的模型。它采用 IO 多路复用机制同时监听多个 socket,将产生事件的 socket 压入内存队列中,事件分派器根据 socket 上的事件类型来选择对应的事件处理器进行处理。
文件事件处理器的结构包含 4 个部分:
- 多个 socket
- IO 多路复用程序
- 文件事件分派器
- 事件处理器(连接应答处理器、命令请求处理器、命令回复处理器)
多个 socket 可能会并发产生不同的操作,每个操作对应不同的文件事件,但是 IO 多路复用程序会监听多个 socket,会将产生事件的 socket 放入队列中排队,事件分派器每次从队列中取出一个 socket,根据 socket 的事件类型交给对应的事件处理器进行处理。
来看客户端与 redis 的一次通信过程:
要明白,通信是通过 socket 来完成的,不懂的同学可以先去看一看 socket 网络编程。
首先,redis 服务端进程初始化的时候,会将 server socket 的 AE_READABLE 事件与连接应答处理器关联。
客户端 socket01 向 redis 进程的 server socket 请求建立连接,此时 server socket 会产生一个 AE_READABLE 事件,IO 多路复用程序监听到 server socket 产生的事件后,将该 socket 压入队列中。文件事件分派器从队列中获取 socket,交给连接应答处理器。连接应答处理器会创建一个能与客户端通信的 socket01,并将该 socket01 的 AE_READABLE 事件与命令请求处理器关联。
假设此时客户端发送了一个 set key value 请求,此时 redis 中的 socket01 会产生 AE_READABLE 事件,IO 多路复用程序将 socket01 压入队列,此时事件分派器从队列中获取到 socket01 产生的 AE_READABLE 事件,由于前面 socket01 的 AE_READABLE 事件已经与命令请求处理器关联,因此事件分派器将事件交给命令请求处理器来处理。命令请求处理器读取 socket01 的 key value 并在自己内存中完成 key value 的设置。操作完成后,它会将 socket01 的 AE_WRITABLE 事件与命令回复处理器关联。
如果此时客户端准备好接收返回结果了,那么 redis 中的 socket01 会产生一个 AE_WRITABLE 事件,同样压入队列中,事件分派器找到相关联的命令回复处理器,由命令回复处理器对 socket01 输入本次操作的一个结果,比如 ok,之后解除 socket01 的 AE_WRITABLE 事件与命令回复处理器的关联。
为啥 redis 单线程模型也能效率这么高?
- 纯内存操作。
- 核心是基于非阻塞的 IO 多路复用机制。
- C 语言实现,一般来说,C 语言实现的程序“距离”操作系统更近,执行速度相对会更快。
- 单线程反而避免了多线程的频繁上下文切换问题,预防了多线程可能产生的竞争问题。
redis支持的数据结构
Redis中所有的数据结构都以唯一的key字符串为名称,然后通过这个唯一的key值获得相应的value数据。不同类型的数据结构的差异就在于value的结构不一样。
1. String
动态字符串,内部结构的实现类似于java的ArrayList,采用预分配冗余空间的方式来减少内存的频繁分配。value其实不仅可以是String,也可以是数字。
常用命令: set,get,decr(自减),incr(自增),mget 等
使用场景:常规计数:微博数,粉丝数等
底层数据结构解析
redis的字符串有两种存储方式,在长度小于44字节的时候,使用embstr形式存储,大于44字节的时候,使用raw形式存储。
为什么有44字节这个界限?
redis源码采用c语言来实现,这里需要牵扯到c语言的知识。
存储信息的解读:
所有的redis对象都包含一个头结构,redis对象头占用16字节(结构体),SDS结构体包含真实的数据信息。embstr存储形式将对象头结构和SDS对象连续存在一起,使用malloc方法一次分配,而raw使用两次malloc方法,两个对象头在内存地址上一般是不连续的。连续分配内存的最大值为64字节,如果超出64字节就认为是一个大字符串,改用raw存。
44字节的计算:
64-16=48字节来存放SDS,其中SDS内部需要3字节存放自身的内容信息,比如长度和容量,48-3=45字节长。其中c字符串以null结尾,所以embstr最大能容纳的字符长度就是44字节。
2.List
链表,内部结构为双向链表,即可以支持反向查找和遍历。列表是有序的,列表中的元素可以重复。广泛用于缓冲队列,消息队列等应用场景。
常用命令
1) 添加:Lpush 链表的头插法;Rpush 链表的尾插法
2) 弹出元素:lpop,返回并弹出指定Key关联的链表中的首部元素。
rpop,返回并弹出指定Key关联的链表中的尾元素。
3) lrange 命令,就是从某个元素开始读取多少个元素,可以基于 list 实现分页查询,应用:可以做类似微博那种下拉不断分页的东西(一页一页的往下走),性能高。
应用
1) 消息排队和异步逻辑处理,确保元素的访问顺序。lpop+rpush 头出+尾插
2) 微博的关注列表,粉丝列表,消息列表等功能都可以用Redis的 list 结构来实现。
3.Hash
字典,相当于java中的hashmap,无序字典,内部结构数组+链表。hash 特别适合用于存储对象,可以直接修改这个对象中的某个字段的值。
常用命令: hget,hset,hgetall 等。
hash冲突的解决方案和扩容
在Redis中,在冲突发生时,采取的是链式冲突解决办法。另外,redis采用了双哈希表结构(ht[2])。简单来说,就是初始k/v保存在ht[0]中,当冲突严重时,将ht[1]中桶的大小设置为ht[0]的两倍,并逐步将ht[0]中的元素迁移到ht[1]。等到所有元素都迁移完成后,再将ht[0]与ht[1]交换地址。搬迁的过程采用渐进式rehash,小步搬迁。
hash函数
为了将key打散的均匀,默认的hash函数是siphash,随机性特别好。
siphash指路:https://blog.csdn.net/weixin_33885253/article/details/91974290
主要是采用异或运算,多次for循环采用随机数进行异或运算。
4.Set(唯一值集合)
相当于java语言中的HashSet,内部的键值对是无序的、唯一的。 set 是可以自动去重的。
常用命令: sadd,spop,smembers,sunion 等
使用场景:
1) 中奖人不会出现两次。
2) 在微博应用中,可以将一个用户所有的关注人存在一个集合中,将其所有粉丝存在一个集合。Redis可以非常方便的实现如共同关注、共同粉丝、共同喜好等功能。这个过程也就是求交集的过程。
内部实现:
字典的形式,只不过value都是NILL。
5.Sort Set(唯一性,有序集合)zset
Sort Set拥有set的功能即确保value的唯一性,并且通过用户提供一个优先级参数来实现自动排序的。Sort set内部使用HashMap和SkipList来实现数据的有序存储,保证查询的效率以及元素有序性。
使用场景:
1)需要为某个班级的学生根据成绩来排序
2)在直播系统中,实时排行信息包含直播间在线用户列表,各种礼物排行榜,
底层数据结构解析
跳跃表结构
可以支持快速的插入、删除、查找操作,为了提高链表的基础操作的效率。由于二分查找法只能运用在数组。我们可以对链表构建索引,比如:每两个节点提取一个结点到上一级,被抽出来的这级叫做索引或索引层。支持增删查时间复杂度为O(logn)
- 查询的时间复杂度:O(n)
例如:对于一个长度为n的链表,每两个节点就抽出一个一级索引,每两个一级索引又抽出一个二级索引,所以第一级索引的结点个数大约就是 n/2,第二级索引的结点个数就是 n/4,每次规模减少一半,所以第 k 级索引的结点个数就是 n/2^k。假设一共建立了 h 级索引,最高级的索引有两个节点(如果最高级索引只有一个结点,那么这一级索引起不到判断区间的作用,那么是没什么意义的),所以有:
n/2^k=2; k=logN-1,加上原始的链表 这个高度为logN。
每级遍历 3 个结点即可,而跳表的高度为h,所以每次查找一个结点时,需要遍历的结点数为 3*跳表高度 ,所以忽略低阶项和系数后的时间复杂度就是O(logn)
- 跳表索引动态更新
当我们不停的往跳表中插入数据时,如果我们不更新索引,就可能出现某 2 个索引结点之间数据非常多的情况。极端情况下,跳表会退化成单链表。
作为一种动态数据结构,我们需要某种手段来维护索引与原始链表大小之间的平滑,也就是说如果链表中结点多了,索引结点就相应地增加一些,避免复杂度退化,以及查找、插入、删除操作性能下降。跳表是通过随机函数来维护前面提到的平衡性。我们往跳表中插入数据的时候,可以选择同时将这个数据插入到第几级索引中,比如随机函数生成了值 K,那我们就将这个结点添加到第一级到第 K 级这 K 级索引中。随机函数可以保证跳表的索引大小和数据大小的平衡性,不至于性能过度退化。
参考书籍:《Redis深度历险 核心原理与应用实践》 钱文品
转载git地址:https://github.com/doocs/advanced-java (侵权删)














 3171
3171











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









