





因为课业要求,搭建一个简单的搜索引擎,找了一些相关资料并进行了部分优化(坑有点多)
一.数据
数据是网络上爬取的旅游相关的攻略页面

这个是travels表,在索引中主要用到id和url两个字段。
页面中文文章内容的爬取用了newspaper3k这个包(如果页面里面文章字数过多,需要设置一下超时时间,不然会报错)
defarticle(url):try:
a=Article(url,language="zh")
a.download()
a.parse()returna.textexcept:pass
return -1
如果报错不退出程序,返回-1
二.分词
文章爬取下来之后的分词有两种模式,全文分词,分词后提取关键词
全文分词
defcutworf(url):
text=article(url)
seg_list=jieba.cut_for_search(text)return seg_list
如果有很多的页面需要爬取,全文分词的速度会很慢,所以我用了关键词分词
jieba有提供两个关键词分词的方式 TF-IDF以及TextRank算法,在这里我不多详细的说明两个算法的区别。在经过分词结果的比较后,我选择了TF-IDF。
textrank =analyse.textrank
tfidf=analyse.extract_tagsdefkeyword(url):
text=article(url)if text==-1:return -1
else:#基于TF-IDF算法进行关键词抽取
keywords =tfidf(text)#print ("keywords by tfidf:")
#输出抽取出的关键词
#for keyword in keywords:
#print (keyword + "/")
return keywords
三.建立索引
创建3个链表类型,3个节点类型(括号中表示)。
Linklist(Node):对每一个网页分词后,将词加入此链表。
Weblist(Web):把网页按照所拥有的词加入词链表,接在词的后面。
Resultlist(Result):搜索结果加入此链表。
设定停用词
ignorewords=set(['的','但是','然而','能','在','以及','可以','使','我','我们','大家','高兴','啊','哦'])
停用词可以根据文章进行添加
把分词加入链表
defindex(url,count):#words=cutworf(url)
keys=keyword(url)if keys==-1:return -1dickey=list(keys)#dicn=list(words)
#for i in range(len(dicn)):
#word = dicn[i]
#if word in ignorewords: continue
#if ll.getlength() == 0:
#wl = linklist.WebList()
#wl.initlist(count)
#ll.initlist(word, wl)
# #if ll.getlength() > 0:
#i = ll.index(word)
#if i == -1:
#wl = linklist.WebList()
#wl.initlist(count)
#ll.append(word, wl)
## print(word)
#if i != -1:
#j = ll.getwh(i).index(count)
#if j == -1:
#ll.getwh(i).append(count)
for i inrange(len(dickey)):
word=dickey[i]if word in ignorewords: continue
if kl.getlength() ==0:
wl=linklist.WebList()
wl.initlist(count)
kl.initlist(word, wl)if kl.getlength() >0:
i=kl.index(word)if i == -1:
wl=linklist.WebList()
wl.initlist(count)
kl.append(word, wl)#print(word)
if i != -1:
j=kl.getwh(i).index(count)if j == -1:
kl.getwh(i).append(count)return 1
注释掉的部分是全文分词
最后就是遍历链表,加入索引库

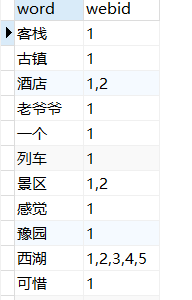
对14000多条url进行处理大概花费25个小时
建议放到服务器上运行,用nohup命令,可以在关闭远程连接后让程序继续运行。会自动生成nohup.out文件,报错输出结果什么的可以在里面看到。
四.源代码
五.一些坑
这些运行时间很长的程序一定要加异常处理!!!不然运行一半报错了又要重头开始...
连接数据库不要在还没用到的时候连,在用之前再连接。我在分词之前连了数据库,然后运行 20多个小时以后,链表处理完了...数据库链接失效报错...因为连接之后太长时间没有进行操作,数据库会断开连接。















 9075
9075











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









