





前言
接收者操作特征曲线(ROC)可以用来对分类器的表现可视化,可以依据分类器在ROC上的表现来选择最终的模型。
分类性能TP、FP、TN、FN
以二分类问题为例,每个实例I将会被映射到正例和负例上{p,n}。模型会将每个实例一个预测结果,结果可能是连续的,也可能是离散的;对于连续的结果,需要根据阈值再进行分类。为了和分类标签区分,我们使用{Y,N}表示每个样本的预测结果。
给定一个分类器和一个样本,会有4个输出。如果样本是正例而且被预测为正例,则归为TP;如果被预测为负例,则归为FN;如果样本是负例而且被预测为正例,则归为FP;如果被预测为负例,则归为TN。给定一个分类器以及一个测试集,我们可以根据这4种情况,将预测结果进行分类,得到一个混淆矩阵:
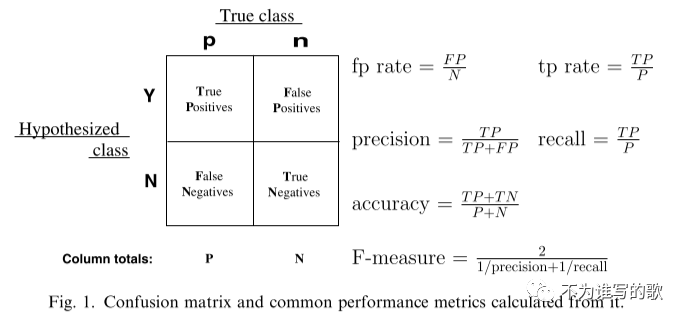
真阳率,又称为recall,召回率(查全率)
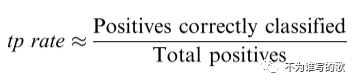
表示在预测的正例中真正的正例TP占所有正例P的比例,是一个覆盖面的度量。eg:分类器可以将所有测试集都预测为正例,这样tp rate(recall)=1,表示所有的正例都预测出来了,虽然会有误报FP的存在。
假阳率:
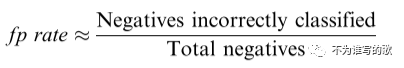
表示被错误归为正例的负例即FP占所有负例的比例。
precision,查准率,预测为正例中真正正例所占的比例。
ROC空间
ROC曲线图有两个维度,横轴表示fp rate,纵轴表示tp rate。ROC表示了在收益(true positives)和成本(false positives)之间的权衡关系。
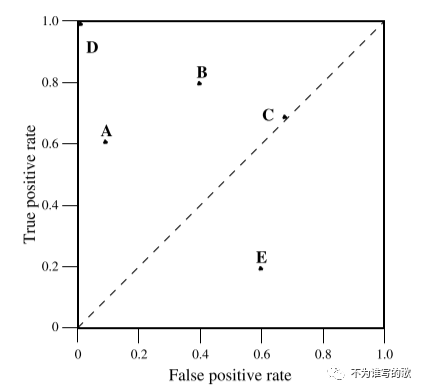
在ROC曲线中,需要注意几个点。左下角的(0, 0)表示分类器将所有测试集都预测为负例,从不做正类预测,所以tp rate、fp rate均为0;另一个极端是右上角的(1,1),表示分类器将所有的测试集都预测为正例,因此tp rate、fp rate均为1。最佳的分类点是(0,1),表示分类器将所有的正例、负例都准确地预测,TP=P, FP=0,TN=N, FN=0。在上图中分类器D的表现最好接近(0,1)点。
一般来说,在ROC空间中一个点越接近西北方即(0,1)点表现会越好(tp rate更高,fp rate更低)。
出现在ROC图中左侧的分类器,离X轴越近的分类时越保守,只有当证据非常充足时才会预测为正例(以逻辑回归来说,分类阈值越大,越保守-只有当f(x) > 0.9时才会归为正类),因此假阳率也会很低,false postive很少。在ROC图中越靠近右上方,分类器越激进,只有满足很松的条件就被归为正例,因此tp rate会很高;相应的,被错误归为正例的负例false positiv也会很高。在上图中分类器A比B更保守。在实际的很多问题中,负例的数量远远大于正例,因此,ROC左侧的分类器会更加受关注。
上图中的直线y=x表示采取随机猜测的分类器,类似于抛硬币。比如点(0.5, 0.5)表示预测过程中对样本一般时间预测为正例、一般时间预测为负例。(0.9,0.9)表示预测过程中90%的时间将样本预测为正例。最后得到y=x这样的曲线。点C接近于(0.7,0.7)表示在预测过程70%预测为正例。
假设对于包含M个样本的测试集中有P个正样本、N个负样本;如果测试集是随机抽样的话,正负样本的比例是不变的。如果分类器在分类过程中90%的时间都将测试集中样本预测为正例,那预测为正例的样本有0.9M个,预测负例有0.1M个;从tp_rate, fp_rate的计算公式我们可以知道,两者分别是在所有正例P、所有负例N空间上计算的,两个分子之和等于预测为正例的样本数0.9M。无论分类器对测试集如何预测,改变的总是分子,而不同的预测方式,改变的是tp、fp,但两者的比例一般不变;所以,如果分类器90%时间都将结果预测为正例tp、fp都扩大相应的比例,tp_rate=0.9, fp_rate=0.9。
在ROC曲线中处于y=x直线下的分类器表现比随机猜测还要差。一般情况下,ROC曲线由y=x构成的下三角形是空的。如果分类器处于右下方,接近x轴,我们可以将模型的预测结果反着来[取反],就可以将roc的点搬到y=x左上方去。反着来,原来预测的正类变为负类,负类变正类;TP变FN,FP变TN。上图中分类器E比随机猜测效果还要差,实际上这个分类器是分类器B的取反结果。
处于y=x上的分类器没有利用到样本的信息;处于y=x下方的分类器利用到了样本的信息,不过没有准确的使用。
ROC曲线
很多分类器,如决策树、关联规则,在分类时直接给出分类结果,或者说模型输出是离散的,{Y,N}。当这样的模型对于测试集进行预测时,根据结果我们可以得到一个混淆矩阵,进而得到ROC空间上的一个点。
对于输出是连续值的分类器,如朴素贝叶斯、神经网络模型,对每个样本能给出一个概率值,或者一个得分score,表示样本属于某个分类的可信度。如果结果是概率值,表示样本属于正类的概率;如果为score,没有经过归一化,这种情况socore越高表示属于正例的概率越大。
对于这类排序、打分的分类器,通过设置一个threshold,可以得到分类结果:如果高于阈值,归为正类Y;低于阈值,归为负类N。设置每个不同的阈值,我们可以得到不同的混淆矩阵,进而在ROC空间中能得到不同的点,连接之后可以得到ROC曲线。比如,我们可以将阈值在(, +)间取值。
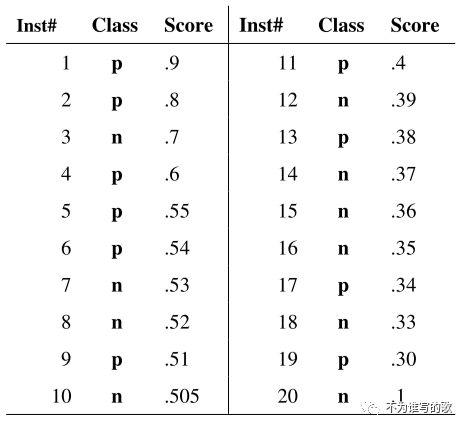
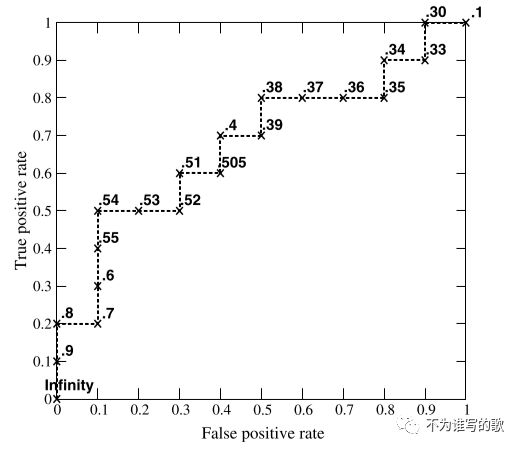
给定包含10个正类、10个负类的测试集;根据分类器预测的得分对20个样本进行降序排序(排序即可,无所谓降序、升序),然后采用不同的阈值即可得到上述的ROC曲线。从图中我们可以看到这个曲线实际上更像是一个阶跃函数折线图,这是因为测试集样本太少导致的,当测试样本增加时,ROC曲线会更加平滑。当阈值设置为正无穷时,得到点(0,0);阈值为负无穷时,可以得到(1,1);阈值为0.9时,可以得到(0,0.1)。当分类阈值不断降低时,对应模型在ROC空间中从保守区域逐渐移动到激进区域。
ROC曲线的最重要的特点是可以对分类模型产生的排序得分能力进行测量[排序得分,得分的准确性并不重要,关注的是不同类别得分之间的相对大小关系]。分类器不需要产生非常精准的、经过归一化的概率得分;只要保证产生的得分能准确地区分正例、负例即可。[正因为这个原因,AUC也只是衡量模型排序能力的指标,不能保证模型预测的精准性;比如在ctr预估中,不能保证pctr接近ctr,可以保证正例的pctr,高于负例的ctr。如果ctr,用于计算广告中,ctr直接参与竞价,并不能保证准确性,一般要经过calibration,保证与真实ctr不会偏离太多]。
The ROC curve shows the ability of the classifier to rank the positive instances relative to the negative instances, and it is indeed perfect in this ability.
ROC曲线对类别分布的变化不敏感。如果测试集中的正负样本比例发生改变,ROC曲线也不会变化。原因在于,roc曲线的横纵坐标fp rate, tp rate分别在标签为负类、正类中计算,正负样本比例发生变化,对应tp、fp也会发生相应的变化,tp_rate/fp_rate可能会保持不变。
ROC曲线绘制方法

roc曲线的绘制主要就是需要找到图像中的各个坐标点,所以这个算法的主要目的就是找到ROC的各个坐标点。
输入:测试集L,f(i)表示分类器对样本i的预估分数;P,N分别表示正类、负类的样本数。
输出:R,ROC曲线的坐标点,通过fp_rate进行排序。
步骤:
- 将测试集L根据分类器的得分f进行降序排序,得到
- 初始化FP、TP为0
- 声明返回结果列表R
- 设定 [给定一个不会重复的初始值即可]
- i = 1[逐步进行循环]
- 遍历
- ,将点加入到R列表中
- 更新
- 如果, 说明找到一个新的坐标点,计算坐标
- 更新TP、FP
- 如果为正类:TP = TP + 1;
- 如果为负类:FP = FP + 1
- i += 1
- 计算最后一个坐标
得到坐标列表R后,可以根据坐标点得到最终的ROC曲线。
AUC计算伪代码

AUC的计算过程和ROC曲线的绘制算法相似,不同之处在于每次不再是向列表中添加坐标点,而是计算一个梯形面积,通过面积的不断叠加,从而得到最终的AUC指标。
AUC表示的ROC曲线包围的面积,AUC的取值范围[0,1]之间。计算这个面积,理论上可以使用积分法,但是也可以通过叠加各个小梯形的面积来得到。
AUC是ROC曲线包围的面积,也继承了ROC本身的特点,是一种衡量模型排序能力的指标,等效于--对于任意一对正负例样本,模型将正样本预测为正例的可能性大于 将负例预测为正例的可能性的概率。
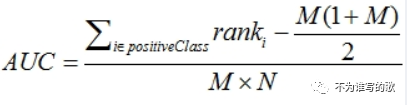
还是推荐第一种计算方法。顺便给出一个Python代码:
def scoreAUC(num_clicks, num_shows, predicted_ctr): # 降序排序 i_sorted = sorted(range(len(predicted_ctr)),key=lambda i: predicted_ctr[i],reverse=True) auc_temp = 0.0 click_sum = 0.0 old_click_sum = 0.0 no_click = 0.0 no_click_sum = 0.0 last_ctr = predicted_ctr[i_sorted[0]] + 1.0 for i in range(len(predicted_ctr)): if last_ctr != predicted_ctr[i_sorted[i]]: # 累加小梯形面积 auc_temp += (click_sum+old_click_sum) * no_click / 2.0 old_click_sum = click_sum no_click = 0.0 last_ctr = predicted_ctr[i_sorted[i]] # 小梯形的高 no_click += num_shows[i_sorted[i]] - num_clicks[i_sorted[i]] # N no_click_sum += num_shows[i_sorted[i]] - num_clicks[i_sorted[i]] # P click_sum += num_clicks[i_sorted[i]] # 最后一个小梯形 auc_temp += (click_sum+old_click_sum) * no_click / 2.0 # 归一化,分母 total_area = click_sum * no_click_sum if total_area == 0: auc = 1 else: auc = auc_temp / total_area return aucReference
?An introduction to ROC analysis

AUC、ROC详解:原理、特点&算法
前言
接收者操作特征曲线(ROC)可以用来对分类器的表现可视化,可以依据分类器在ROC上的表现来选择最终的模型。
分类性能TP、FP、TN、FN
以二分类问题为例,每个实例I将会被映射到正例和负例上{p,n}。模型会将每个实例一个预测结果,结果可能是连续的,也可能是离散的;对于连续的结果,需要根据阈值再进行分类。为了和分类标签区分,我们使用{Y,N}表示每个样本的预测结果。
给定一个分类器和一个样本,会有4个输出。如果样本是正例而且被预测为正例,则归为TP;如果被预测为负例,则归为FN;如果样本是负例而且被预测为正例,则归为FP;如果被预测为负例,则归为TN。给定一个分类器以及一个测试集,我们可以根据这4种情况,将预测结果进行分类,得到一个混淆矩阵:
真阳率,又称为recall,召回率(查全率)
表示在预测的正例中真正的正例TP占所有正例P的比例,是一个覆盖面的度量。eg:分类器可以将所有测试集都预测为正例,这样tp rate(recall)=1,表示所有的正例都预测出来了,虽然会有误报FP的存在。
假阳率:
表示被错误归为正例的负例即FP占所有负例的比例。
precision,查准率,预测为正例中真正正例所占的比例。
ROC空间
ROC曲线图有两个维度,横轴表示fp rate,纵轴表示tp rate。ROC表示了在收益(true positives)和成本(false positives)之间的权衡关系。
在ROC曲线中,需要注意几个点。左下角的(0, 0)表示分类器将所有测试集都预测为负例,从不做正类预测,所以tp rate、fp rate均为0;另一个极端是右上角的(1,1),表示分类器将所有的测试集都预测为正例,因此tp rate、fp rate均为1。最佳的分类点是(0,1),表示分类器将所有的正例、负例都准确地预测,TP=P, FP=0,TN=N, FN=0。在上图中分类器D的表现最好接近(0,1)点。
一般来说,在ROC空间中一个点越接近西北方即(0,1)点表现会越好(tp rate更高,fp rate更低)。
出现在ROC图中左侧的分类器,离X轴越近的分类时越保守,只有当证据非常充足时才会预测为正例(以逻辑回归来说,分类阈值越大,越保守-只有当f(x) > 0.9时才会归为正类),因此假阳率也会很低,false postive很少。在ROC图中越靠近右上方,分类器越激进,只有满足很松的条件就被归为正例,因此tp rate会很高;相应的,被错误归为正例的负例false positiv也会很高。在上图中分类器A比B更保守。在实际的很多问题中,负例的数量远远大于正例,因此,ROC左侧的分类器会更加受关注。
上图中的直线y=x表示采取随机猜测的分类器,类似于抛硬币。比如点(0.5, 0.5)表示预测过程中对样本一般时间预测为正例、一般时间预测为负例。(0.9,0.9)表示预测过程中90%的时间将样本预测为正例。最后得到y=x这样的曲线。点C接近于(0.7,0.7)表示在预测过程70%预测为正例。
假设对于包含M个样本的测试集中有P个正样本、N个负样本;如果测试集是随机抽样的话,正负样本的比例是不变的。如果分类器在分类过程中90%的时间都将测试集中样本预测为正例,那预测为正例的样本有0.9M个,预测负例有0.1M个;从tp_rate, fp_rate的计算公式我们可以知道,两者分别是在所有正例P、所有负例N空间上计算的,两个分子之和等于预测为正例的样本数0.9M。无论分类器对测试集如何预测,改变的总是分子,而不同的预测方式,改变的是tp、fp,但两者的比例一般不变;所以,如果分类器90%时间都将结果预测为正例tp、fp都扩大相应的比例,tp_rate=0.9, fp_rate=0.9。
在ROC曲线中处于y=x直线下的分类器表现比随机猜测还要差。一般情况下,ROC曲线由y=x构成的下三角形是空的。如果分类器处于右下方,接近x轴,我们可以将模型的预测结果反着来[取反],就可以将roc的点搬到y=x左上方去。反着来,原来预测的正类变为负类,负类变正类;TP变FN,FP变TN。上图中分类器E比随机猜测效果还要差,实际上这个分类器是分类器B的取反结果。
处于y=x上的分类器没有利用到样本的信息;处于y=x下方的分类器利用到了样本的信息,不过没有准确的使用。
ROC曲线
很多分类器,如决策树、关联规则,在分类时直接给出分类结果,或者说模型输出是离散的,{Y,N}。当这样的模型对于测试集进行预测时,根据结果我们可以得到一个混淆矩阵,进而得到ROC空间上的一个点。
对于输出是连续值的分类器,如朴素贝叶斯、神经网络模型,对每个样本能给出一个概率值,或者一个得分score,表示样本属于某个分类的可信度。如果结果是概率值,表示样本属于正类的概率;如果为score,没有经过归一化,这种情况socore越高表示属于正例的概率越大。
对于这类排序、打分的分类器,通过设置一个threshold,可以得到分类结果:如果高于阈值,归为正类Y;低于阈值,归为负类N。设置每个不同的阈值,我们可以得到不同的混淆矩阵,进而在ROC空间中能得到不同的点,连接之后可以得到ROC曲线。比如,我们可以将阈值在(, +)间取值。
给定包含10个正类、10个负类的测试集;根据分类器预测的得分对20个样本进行降序排序(排序即可,无所谓降序、升序),然后采用不同的阈值即可得到上述的ROC曲线。从图中我们可以看到这个曲线实际上更像是一个阶跃函数折线图,这是因为测试集样本太少导致的,当测试样本增加时,ROC曲线会更加平滑。当阈值设置为正无穷时,得到点(0,0);阈值为负无穷时,可以得到(1,1);阈值为0.9时,可以得到(0,0.1)。当分类阈值不断降低时,对应模型在ROC空间中从保守区域逐渐移动到激进区域。
ROC曲线的最重要的特点是可以对分类模型产生的排序得分能力进行测量[排序得分,得分的准确性并不重要,关注的是不同类别得分之间的相对大小关系]。分类器不需要产生非常精准的、经过归一化的概率得分;只要保证产生的得分能准确地区分正例、负例即可。[正因为这个原因,AUC也只是衡量模型排序能力的指标,不能保证模型预测的精准性;比如在ctr预估中,不能保证pctr接近ctr,可以保证正例的pctr,高于负例的ctr。如果ctr,用于计算广告中,ctr直接参与竞价,并不能保证准确性,一般要经过calibration,保证与真实ctr不会偏离太多]。
The ROC curve shows the ability of the classifier to rank the positive instances relative to the negative instances, and it is indeed perfect in this ability.
ROC曲线对类别分布的变化不敏感。如果测试集中的正负样本比例发生改变,ROC曲线也不会变化。原因在于,roc曲线的横纵坐标fp rate, tp rate分别在标签为负类、正类中计算,正负样本比例发生变化,对应tp、fp也会发生相应的变化,tp_rate/fp_rate可能会保持不变。
ROC曲线绘制方法
roc曲线的绘制主要就是需要找到图像中的各个坐标点,所以这个算法的主要目的就是找到ROC的各个坐标点。
输入:测试集L,f(i)表示分类器对样本i的预估分数;P,N分别表示正类、负类的样本数。
输出:R,ROC曲线的坐标点,通过fp_rate进行排序。
步骤:
- 将测试集L根据分类器的得分f进行降序排序,得到
- 初始化FP、TP为0
- 声明返回结果列表R
- 设定 [给定一个不会重复的初始值即可]
- i = 1[逐步进行循环]
- 遍历
- ,将点加入到R列表中
- 更新
- 如果, 说明找到一个新的坐标点,计算坐标
- 更新TP、FP
- 如果为正类:TP = TP + 1;
- 如果为负类:FP = FP + 1
- i += 1
- 计算最后一个坐标
得到坐标列表R后,可以根据坐标点得到最终的ROC曲线。
AUC计算伪代码
AUC的计算过程和ROC曲线的绘制算法相似,不同之处在于每次不再是向列表中添加坐标点,而是计算一个梯形面积,通过面积的不断叠加,从而得到最终的AUC指标。
AUC表示的ROC曲线包围的面积,AUC的取值范围[0,1]之间。计算这个面积,理论上可以使用积分法,但是也可以通过叠加各个小梯形的面积来得到。
AUC是ROC曲线包围的面积,也继承了ROC本身的特点,是一种衡量模型排序能力的指标,等效于--对于任意一对正负例样本,模型将正样本预测为正例的可能性大于 将负例预测为正例的可能性的概率。
还是推荐第一种计算方法。顺便给出一个Python代码:
def scoreAUC(num_clicks, num_shows, predicted_ctr): # 降序排序 i_sorted = sorted(range(len(predicted_ctr)),key=lambda i: predicted_ctr[i],reverse=True) auc_temp = 0.0 click_sum = 0.0 old_click_sum = 0.0 no_click = 0.0 no_click_sum = 0.0 last_ctr = predicted_ctr[i_sorted[0]] + 1.0 for i in range(len(predicted_ctr)): if last_ctr != predicted_ctr[i_sorted[i]]: # 累加小梯形面积 auc_temp += (click_sum+old_click_sum) * no_click / 2.0 old_click_sum = click_sum no_click = 0.0 last_ctr = predicted_ctr[i_sorted[i]] # 小梯形的高 no_click += num_shows[i_sorted[i]] - num_clicks[i_sorted[i]] # N no_click_sum += num_shows[i_sorted[i]] - num_clicks[i_sorted[i]] # P click_sum += num_clicks[i_sorted[i]] # 最后一个小梯形 auc_temp += (click_sum+old_click_sum) * no_click / 2.0 # 归一化,分母 total_area = click_sum * no_click_sum if total_area == 0: auc = 1 else: auc = auc_temp / total_area return aucReference
?An introduction to ROC analysis














 3485
3485











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









