





将一个工作簿里的各个sheet工作表,快速拆分成单个工作簿,并统一放入某个文件夹中。
文件路径为:C:\Users\12869\Desktop\test_data\canyindata.xlsx,
在canyindata的工作簿里有如下各个sheet工作表:
 本次需导入以下模块:
本次需导入以下模块:
# _*_ coding: utf-8 _*_import xlrdimport pandas as pdimport os关于#_*_ coding: utf-8 _*_,解释大概是防止代码中出现中文报错,为了解决这个问题就需要把文件的编码格式改成utf-8,输入这个代码就可以让py的源码有中文。注意:python3已经默认支持中文。

# 拆分工作表为单个工作簿path = r"C:\Users\12869\Desktop\test_data\canyindata.xlsx" #工作簿路径workbook = xlrd.open_workbook(path) # 打开工作簿sheetnames = workbook.sheet_names() # 获取工作簿内sheet名称setdir = os.path.dirname(path) # 获取工作簿所在路径newdir = setdir + "\csv/" os.mkdir(newdir) # 结合上一行,在工作簿路径下,新建CSV文件夹for i in sheetnames: # 遍历工作簿内各个sheet getdata = pd.read_excel(path,i) # 读取各个sheet内的内容 getdata.to_csv(newdir+i+".csv",encoding = 'utf-8-sig') # 将读取到的内容导出成单个以sheet名称命名的CSV文件,encoding防止表格内容的中文乱码以上代码需要注意的点是,
1、path = r"C:\Users\12869\Desktop\test_data\canyindata.xlsx"
python读文件需要输入的目录参数,列出以下例子:
path1= r"C:\Users\12869\Desktop\test_data\canyindata.xlsx"
path2 =r"C:\\Users\\12869\\Desktop\\test_data\\canyindata.xlsx"
path3 =r"C:/Users/12869/Desktop/test_data/canyindata.xlsx"
打开文件函数open()中的参数可以是path也可以是path1、path2、path3。
path1:"\"为字符串中的特殊字符,加上r后变为原始字符串,则不会对字符串中的类似"\t"、"\r" 等的字符串进行转义。
path2:用一个"\"取消第二个"\"的特殊转义作用,即为"\\"。
path3:用正斜杠做目录分隔符同样可以获取路径信息。
2、newdir = setdir + "\csv/",新建CSV文件夹,注意后加上"/",因为你要在该文件夹内放入得到的工作簿。类似在上面path2、path3那样子,文件夹路径与具体文件之间的“\\”或是“/”,发挥同种作用。因此这里改为 newdir = getdir + "\csv\\" 也可。
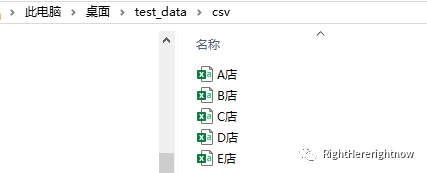
最终得到拆分结果如下:














 4894
4894











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









