






 本文介绍了如何利用Python的Scrapy框架爬取京东网站上的所有手机数据,并将这些数据存储到MongoDB数据库中。文章详细分析了京东搜索页面的结构,包括如何处理分页和隐藏链接,以及如何构造请求参数。最后,通过设置Scrapy爬虫,成功实现了数据抓取和存储,并在MongoDB中检查了抓取的数据。
本文介绍了如何利用Python的Scrapy框架爬取京东网站上的所有手机数据,并将这些数据存储到MongoDB数据库中。文章详细分析了京东搜索页面的结构,包括如何处理分页和隐藏链接,以及如何构造请求参数。最后,通过设置Scrapy爬虫,成功实现了数据抓取和存储,并在MongoDB中检查了抓取的数据。
本文目的是使用scrapy爬取京东上所有的手机数据,并将数据保存到MongoDB中。
一、项目介绍
主要目标
1、使用scrapy爬取京东上所有的手机数据
2、将爬取的数据存储到MongoDB
环境
win7、python2、pycharm
技术
1、数据采集:scrapy
2、数据存储:MongoDB
难点分析
和其他的电商网站相比,京东的搜索类爬取主要有以下几个难点:
1、搜索一个商品时,一开始显示的商品数量为30个,当下拉这一页 时,又会出现30个商品,这就是60个商品了,前30个可以直接 从原网页上拿到,后30个却在另一个隐藏链接中,要访问这两个 链接,才能拿到一页的所有数据。
2、隐藏链接的构造,发现最后的那个show_items字段其实是前30个商品的id。
3、直接反问隐藏链接被拒绝访问,京东的服务器会检查链接的来源, 只有来自当前页的链接他才会允许访问。
4、前30个商品的那一页的链接page字段的自增是1、3、5。。。这 样的,而后30个的自增是2、4、6。。。这样的。
下面看具体的分析。
二、网页分析
首先打开京东的首页搜索“手机”:
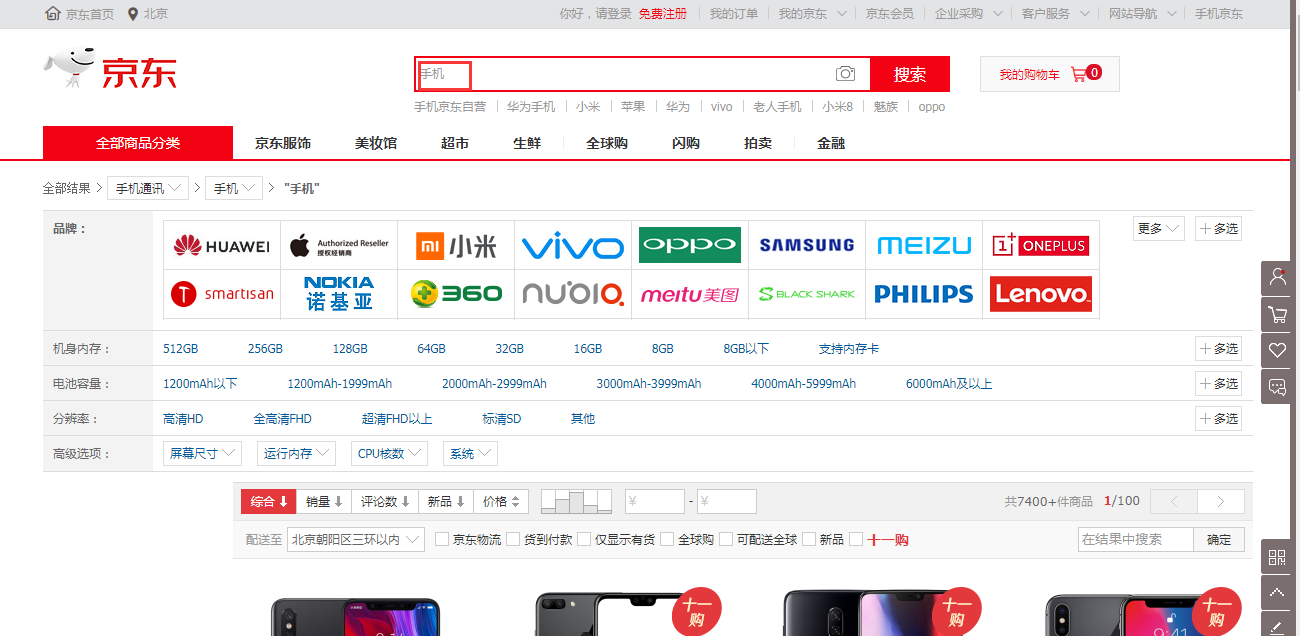
一开始他的地址是这样的:

转到第2页,会看到,他的地址变成这样子了:

后面的字段全变了,那么第2页的url明显更容易看出信息,主要修改的字段其实就是keyword,page,其实还有一个wq字段,这个得值和keyword是一样的。
那么我们就可以使用第二页的url来抓取数据,可以看出第2页的url中page字段为3。
但是查看原网页的时候却只有30条数据,还有30条数据隐藏在一个网页中:

从这里面可以看到他的Request url。
再看一下他的response:

里面正好就是我们需要的信息。
看一下他的参数请求:
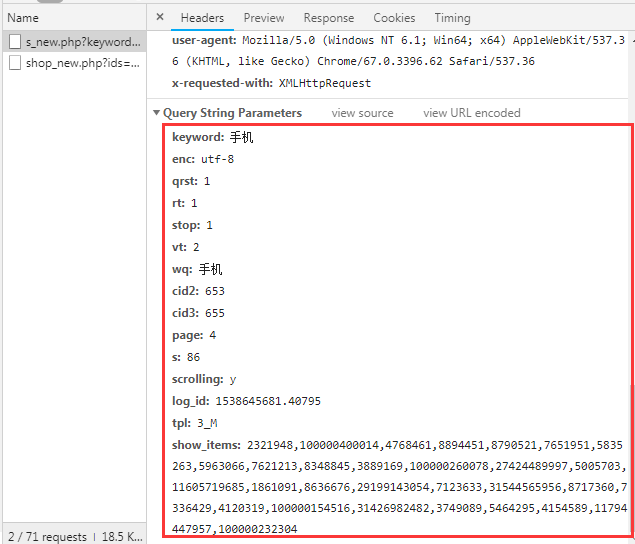
这些参数不难以构造,一些未知的参数可以删掉,而那个show_items参数,其实
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2265
2265











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









