





 本文深入探讨Spring容器启动过程,从构造方法入手,详细解析BeanFactory初始化、条件处理器实例化及后置处理器注册等内容。
本文深入探讨Spring容器启动过程,从构造方法入手,详细解析BeanFactory初始化、条件处理器实例化及后置处理器注册等内容。
一. 前言
Spring家族特别庞大,对于开发人员而言,要想全面征服Spring家族,得花费不少的力气。俗话说,打蛇打七寸,那么Spring家族的“七寸”是什么呢?我心目中的答案一直都是 Spring Framework!
本篇文章记录我自己在学习Spring Framework的过程中的一小部分源码解读和梳理,以@Configuration为主题来谈一谈Spring 容器在启动过程中是如何扫描Bean的。
二. 学习方法论
我相信每个想变成优秀的开发人员都想弄懂Spring源码,我亦如此。于是通过很多途径来找Spring源码的学习资料、买书、看视频等等。到头来发现只有自己静下心来一步一步跟着源码调试,一行一行的深入理解,才能深入理解Spring的奥妙!这个过程很枯燥,但优秀的猎手最能耐得住寂寞和浮躁!
我们知道,Spring容器的启动方式有多种:XML文件、注解、Java Config。在实际的使用中并不是选择其中某一种,而是相互搭配。其底层的容器启动过程是一样的,只是入口变了而已。另外,学习Spring的最佳方式就是自己将源码工程构建出来,这样便于源码阅读、备注、修改。 构建出来的工程长这样:
三. 代码入口
话不多说直接开干!代码入口如下:
@Configuration
在构造方法中,总共做了3件事情。这三件事情包括了整个Spring容器启动的所有过程!啃碎他们,便成功了一半!
public 四. 解析之前
在解析之前,先将容器和BeanFactory的UML类图放出。原因在于它们担任的角色、具备的功能太多太强大了,同时这也增加了源码理解的难度。因此这里先放出UML类图作为手册查看,便于理解源码。
4.1 容器UML类图
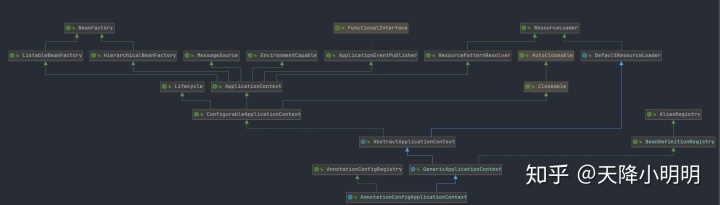
4.2 BeanFactoryUML类图

五. 源码解析
5.1 构造方法解析
5.1.1 初始化容器中的BeanFactory
在构造方法中,显式的调用了this(),既无参构造方法:
public 乍看一眼,这个无参构造方法做了两件事情,其实不然。它实际上等同于:
public 这一点很关键, 如果没有意识到这里隐形调用了父类构造方法的话, 那么接下来的路没法走, 因为在父类构造器中做了一件大事情:
// 在父类的构造方法中, 创建了容器中的BeanFactory.至此,容器中有了第一个程序创建的属性:beanFactory
BeanFactory 和 FacotryBean的区别, 请点击这里
5.1.2 实例化容器中的Reader
reader最主要的目的是用于辅助注册BeanDefinition,其具体的使用后文在介绍,这里我们只需知道它包含了哪些东西。
// 入参registry就是容器本身。因为通过上面的UML类图可以发现,容器间接继承了BeanDefinitionRegistry
这里通过this() 调用了reader内部另一个构造方法:
public 这个构造方法很重要, 因为它涉及到spring容器当中的两个重要成员:条件解析器和后置处理器!
5.1.2.1 实例化条件处理器
相信熟悉Spring的人一定都知道或用过@ConditionalOnBean / @ConditionalOnClass 等条件注解.而这些条件注解的解析就是ConditionEvaluator.
public 后面在解析BeanDefinition时我们还会遇到ConditionEvaluator, 其具体源码解析会用专门的文章来解析,本篇文章我们只需要知道它的作用即可.
5.1.2.2 注册一部分后置处理器
ConditionEvaluator初始化完成之后,接下来就特别重要了,因为在这里将提前注入一些后置处理器:
public 重载的方法如下(高能预警):
public 这个方法首次出现了BeanDefinition这个类. Spring的BeanDefinition相当于Java的Class
通过该方法之后, beanFactory中就存在了以上6个bd:
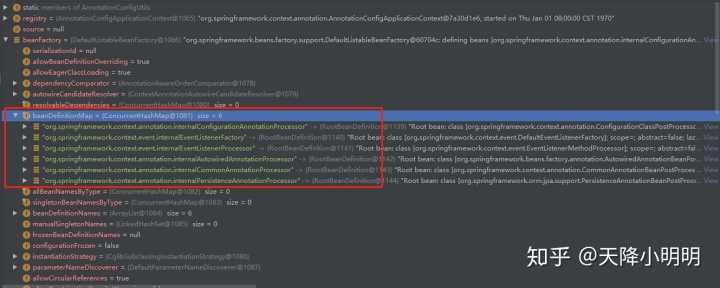
曾经有人跟我说, 掌握了Spring的后置处理器, 那么整个Spring就掌握了10%! 可见其重要性.
但是在这里先不展开后置处理器(太多了),本篇文章的主线是容器启动过程。
5.1.2.3 reader初始化过程小结
到这里reader部分的初始化终于完成了。总结一下,reader的初始化主要干了这些事情:
1.创建并设置容器当中的Environment属性。即默认为StandardEnvironment类。
2.创建并设置容器当中的条件解析器,即ConditionEvaluator,其内部实际委托给内部类ConditionContextImpl。
3.注册6个后置处理器到容器当中。注意这里仅是生成了后置处理器的BeanDefinition。还并没有进行bean解析和后置处理的执行。
5.1.3 实例化容器中的Scanner
解析完reader之后,继续解析scanner。这里的scanner的实际类型是ClassPathBeanDefinitionScanner。它最主要的目的就是扫描类路径下所有的class文件能否解析为bd。 其最终调用的构造方法如下:
public 5.1.3.1 registerDefaultFilters()方法
从最终的构造方法我们知道, Scanner在扫描的过程中,会使用过滤策略,并且使用了默认的过滤策略.默认策略就是以下这个方法解析.
protected 这里的一个知识点: @ManageBean和@Named的作用和@Component是一样的。只是我们通常习惯使用@Component。
为什么这里没有添加默认扫描@Service、@Repository、@Controller呢?原因很简单,这些注解都间接继承了@Component了。
到这里,scanner解析完毕,它做的最主要的事情就是添加默认的过滤器策略以便在后续中可以扫描出@Component注解的类。
六 默认构造方法小结
现在我们再来看一下构造方法:
public 从入口看, 就只有这三行代码, 但其中的第一行,调用默认构造方法就做了这么多准备工作,其中也牵扯出了一些Spring整个体系中最重要的几个组件,比如BeanFactory / BeanDefinition / BeanDefinitionReader / BeanDefinitionScanner / Environment / ConditionEveluator / PostProcessor等等.随便拿一个出来都够喝一壶! 这些点会各个击破, 但不是本篇文章的重点,本篇文章的重点是先梳理整个启动过程的第一步: 构造方法的执行过程.


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









