






上一篇文章只介绍了抖音的爬取过程,还有最后一步,那就是把目标视频下载下来。这里来系统的讲下媒体文件的下载技巧,媒体文件主要是 文字,图片,视频等。这篇文章的目标就是把 文本,图片, 视频保存到本地,还有 多视频并发下载的方式。
文本保存到本地
import json
import requests
from requests.exceptions import RequestException
from pyquery import PyQuery as pq
def get_response(url):
try:
response = requests.get(url)
if response.status_code == 200:
return response.text
return None
except RequestException as e:
print('err: %s' % e)
def write_to_file(content):
with open('result.txt','a',encoding='utf-8') as f:
f.write(json.dumps(content, ensure_ascii=False) + 'n')
f.close()
def read_file():
with open("./result.txt", encoding='UTF-8') as file:
data = file.read()
return data
f.close()
def parse(html):
doc = pq(html)
lis = doc('.col-md-8 .quote')
for item in lis:
text = pq(item).find('.text').text()
author = pq(item).find('.author').text()
tags = pq(item).find('.tags .tag').text()
yield {
'text': text,
'author': author,
'tags': tags
}
def write():
html = get_response('http://quotes.toscrape.com/')
content = [item for item in parse(html)]
write_to_file(content)
def read():
res = json.loads(read_file())
for item in res:
print(item)
if __name__ == '__main__':
write()
# read()我这里爬取Quotes to Scrape这个网站,简单解析下,然后把json保存到本地的result.txt文件 ,因为有中文字符,需要指定encoding='utf-8'
def write_to_file(content):
with open('result.txt','a',encoding='utf-8') as f:
f.write(json.dumps(content, ensure_ascii=False) + 'n')
f.close()a-打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。json.dumps序列化时对中文默认使用的ascii编码.想输出真正的中文需要指定ensure_ascii=False
然后是读取部分,
def read_file():
with open("./result.txt", encoding='UTF-8') as file:
data = file.read()
return data
f.close()读取也要指定encoding='UTF-8',不然会报错 'gbk' codec can't decode byte,json.loads可以把读取下来的字符转换成字典格式
图片下载
import requests
from requests.exceptions import RequestException
from hashlib import md5
import os
# 保存文件到本地
def save_image(content):
file_path = '{0}/{1}.{2}'.format(os.getcwd() + 'image',md5(content).hexdigest(),'jpg')
if not os.path.exists(file_path):
with open(file_path,'wb') as f:
f.write(content)
f.close()
# 下载图片
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/27.0.1453.94 Safari/537.36'
}
def download_image(url):
try:
response = requests.get(url,headers=headers)
if response.status_code == 200:
# 返回二进制内容
save_image(response.content)
return None
except RequestException:
print("请求失败~")
return None
url = 'https://ss0.baidu.com/6ONWsjip0QIZ8tyhnq/it/u=4033011597,599836400&fm=173&app=25&f=JPEG?w=218&h=146&s=2D548B4F5B630486C865491303001092'
os.system('mkdir image')
download_image(url)图片下载是从返回的二进制码中保存到本地,需要确定图片的格式,在下载之前先用系统命令在当前位置创建一个空文件,然后把图片下到这个文件里面,用md5算出一个唯一的字符作为图片的文件名
视频下载
关于视频的下载,这里不涉及任何加密的视频,流处理切片视频等,这里只介绍可以直接在浏览器打开并播放的视频。那视频的方式能不能像图片那样下载二进制流呢?我们先来测试下,
import requests
from requests.exceptions import RequestException
from hashlib import md5
import os
# 保存文件到本地
def save_image(content):
file_path = '{0}/{1}.{2}'.format(os.getcwd() + '/video',md5(content).hexdigest(),'mp4')
if not os.path.exists(file_path):
with open(file_path,'wb') as f:
f.write(content)
f.close()
# 下载图片
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/27.0.1453.94 Safari/537.36'
}
def download_video(url):
try:
response = requests.get(url,headers=headers)
print(response)
if response.status_code == 200:
# 返回二进制内容
save_image(response.content)
return None
except RequestException:
print("请求失败~")
return None
url = 'https://f.us.sinaimg.cn/0023l0JOlx07poxa2nSo01040200BiHS0k010.mp4?label=mp4_ld&template=640x360.28.0&Expires=1550723065&ssig=eh6SSz1inx&KID=unistore,video'
os.system('mkdir video')
download_video(url)我找了个视频,实测成功!当然了,短视频这么下载没问题。 单文件下载我已介绍完毕,接下来是重头戏-就是如何进行多视频并发下载,多视频下载如果循环单文件下载的方式,很容易造成io阻塞,我们需要更高效的解决方案, 解决这个之前我们需要来学习下aiohttp。
使用协程的异步请求以其低时消耗和对硬件的高利用而著称,协程在进行爬虫以及高频网络请求时的耗时比单多进程和单多线程还要好 。 aiohttp是一个为Python提供异步HTTP 客户端/服务端编程,基于asyncio(Python用于支持异步编程的标准库)的异步库。当然啦,aiohttp用来爬取也是很优秀的
我们下载主要用到的是基于客户端的请求发送,先来几个例子熟悉下
import 这段代码是aiohttp跟asyncio配合的例子,我们也分这2块来理解
首先是main函数里面的aiohttp,现在有了一个会话(session)对象,由ClientSession对象赋值而来,还有一个变量resp,它其实是ClientResponse对象。我们可以从这个响应对象中获取我们任何想要的信息。协程方法 ClientSession.get()的主要参数接受一个HTTP URL。
aiohttp发起的这个异步请求由asyncio这个库来进行调用。asyncio是Python 3.4版本引入的标准库,直接内置了对异步IO的支持。关于asyncio的用法,以后在专栏里会详细讲解,现在先来个具体例子体会下,
import asyncio
@asyncio.coroutine
def hello():
print("Hello world!")
# 异步调用asyncio.sleep(1):
r = yield from asyncio.sleep(1)
print("Hello again!")
# 获取EventLoop:
loop = asyncio.get_event_loop()
# 执行coroutine
loop.run_until_complete(hello())
loop.close()理解这段代码,先来介绍几个概念
event_loop: 事件循环,相当于一个无限循环,我们可以把一些函数注册到这个事件循环上,
当满足条件发生的时候,就会调用对应的处理方法。
coroutine:中文翻译叫协程,在 Python 中常指代为协程对象类型,我们可以将协程对象注册到时间循环中
,它会被事件循环调用。我们可以使用 async 关键字来定义一个方法,这个方法在调用时不会立即被执行,
而是返回一个协程对象。
由此我们来解释上面的代码,@asyncio.coroutine把一个generator标记为coroutine类型,然后,
我们就把这个coroutine扔到EventLoop中执行。把asyncio.sleep(1)看成是一个耗时1秒的IO操作,
在此期间,主线程并未等待,而是去执行EventLoop中其他可以执行的coroutine了,因此可以实现并发执行。可能很多人不熟悉异步的写法,这里只有牢记一点,就是在 await的地方外面的函数加上async的关键字,意思是函数体存在需要异步执行的代码。
aiohttp简单理解就是一个协程对象,通过asyncio的事件循环来进行调用,从而实现多个请求异步发出,不需要等待其中一个请求完成再进行下一个请求。我们先用这种方式来实现单视频文件的下载
import re
import time
import aiohttp, asyncio
import random
# 单视频下载
async def get_video(url):
async with aiohttp.ClientSession() as session:
async with session.get(url) as resp:
filename = str(random.randint(1,100)) + str(int(time.time()))
video_info = resp.headers['Content-Type']
pattern = re.compile('video/(.*)', re.S)
results = re.findall(pattern,video_info)
nail = results[0]
with open('{}.{}'.format(filename,nail), 'wb') as f:
while True:
chunk = await resp.content.read()
if not chunk:
break
f.write(chunk)
def main():
url = 'https://f.us.sinaimg.cn/000ITAJPlx07ryepM28U010412006mQc0E010.mp4?label=mp4_ld&template=640x360.28.0&Expires=1550735642&ssig=MuOMIEqeLh&KID=unistore,video'
loop = asyncio.get_event_loop()
loop.run_until_complete(get_video(url))
if __name__ == '__main__':
main()注意的地方是 获取二进制响应内容 是 await resp.read() wb的方式的含义是: 只写方式打开或新建一个二进制文件,只允许写数据。这里的文件后缀名是通过headers['Content-Type']来获取的
单文件下载完之后我们来看看多文件下载怎么搞,我们将会用到asyncio的Semaphore来实现并发处理。
import time
import re
import aiohttp, asyncio
from utils import *
mongoCls_ins = mongoCls()
res = mongoCls_ins.read_one({'uid': '101209612312'})
lis = res['video_list']
async def fn(item,sem):
async with sem:
async with aiohttp.ClientSession() as session:
async with session.get(item['url']) as resp:
filename = item['aweme_id']
# 获取视频后缀
video_info = resp.headers['Content-Type']
pattern = re.compile('video/(.*)', re.S)
results = re.findall(pattern,video_info)
nail = results[0]
with open('{}.{}'.format(filename,nail), 'wb') as fd:
while True:
chunk = await resp.content.read()
if not chunk:
break
fd.write(chunk)
def main():
loop = asyncio.get_event_loop()
sem = asyncio.Semaphore(10)
tasks = [ asyncio.ensure_future(fn(item,sem)) for item in lis]
loop.run_until_complete(asyncio.wait(tasks))
if __name__ == '__main__':
main()asyncio.Semaphore(3)将并发数控制在3个,ensure_future 可以将 coroutine 封装成 Task。任务列表的基本格式是
tasks = [
asyncio.ensure_future(func1()),
asyncio.ensure_future(func2())
]
loop.run_until_complete(asyncio.wait(tasks))然后将任务列表交给run_until_complete来完成。
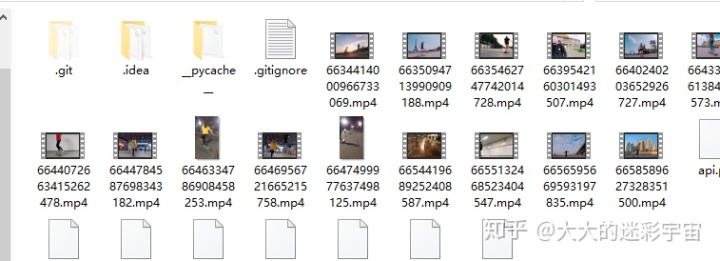
程序一执行,马上就进行下载了!我们来优化下, 增加一个进度条来看清楚我们的下载进度。用到的库是tqdm
import time
from tqdm import tqdm,trange
with tqdm(total=50) as pbar:
for i in range(5):
time.sleep(0.5)
pbar.update(10)total是进度总量, update() 是更新幅度
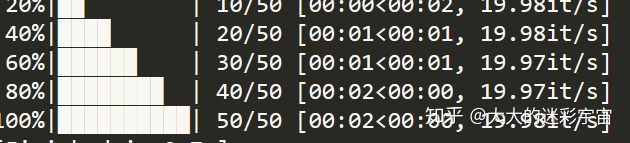
稍微再难点
from tqdm import tqdm
import asyncio
import random
import datetime
import time
urls=['www.baidu.com','www.qq.com','www.douyu.com']
@asyncio.coroutine
def crawl(url):
io_time = random.random()*3
yield from asyncio.sleep(io_time)
loop = asyncio.get_event_loop()
tasks = [ asyncio.ensure_future(crawl(item)) for item in urls ]
with tqdm(total=len(urls)) as pbar:
for task in tasks:
task.add_done_callback(lambda _: pbar.update(1))
loop.run_until_complete(asyncio.wait(tasks))
loop.close()这里用随机时间等待来模拟请求, task封装协程对象,并且有一个add_done_callback回调函数,刚好可以让我们在回调的时候更新tqdm进度。
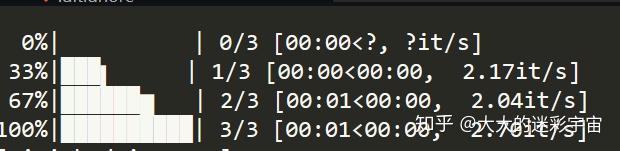
3个请求分别完成进度条的更新。
最后来实现多视频并发下载下的进度条。
import time
import re
import aiohttp, asyncio
from utils import *
from tqdm import tqdm
mongoCls_ins = mongoCls()
res = mongoCls_ins.read_one({'uid': '91703324824'})
lis = res['video_list']
async def fn(item,sem):
async with sem:
async with aiohttp.ClientSession() as session:
async with session.get(item['url'][0]) as resp:
filename = item['aweme_id']
# 获取视频后缀
video_info = resp.headers['Content-Type']
pattern = re.compile('video/(.*)', re.S)
results = re.findall(pattern,video_info)
nail = results[0]
with open('{}.{}'.format(filename,nail), 'wb') as fd:
while True:
chunk = await resp.content.read()
if not chunk:
break
fd.write(chunk)
def main():
loop = asyncio.get_event_loop()
sem = asyncio.Semaphore(3)
tasks = [asyncio.ensure_future(fn(item,sem)) for item in lis]
with tqdm(total=len(lis)) as pbar:
for task in tasks:
task.add_done_callback(lambda _: pbar.update(1))
loop.run_until_complete(asyncio.wait(tasks))
if __name__ == '__main__':
main()视频自己先进行抓取到数据库中,我这里已成功下载
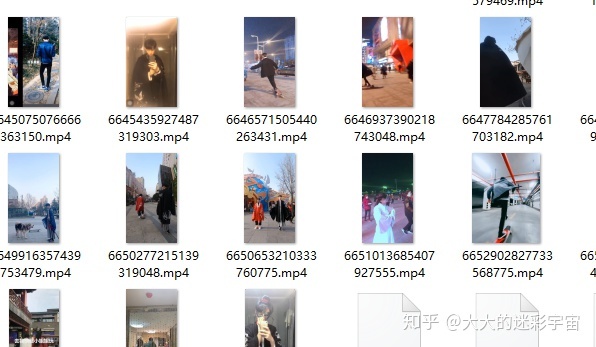
进度条正常运行
源代码请参考
wuzhenbin/douyin-spidergithub.com
里面的download文件,视频地址需要自行爬取~















 2271
2271

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









