





前言
由于经常需要用到Excel,让我对Excel有了更深的认识,以至于不得不感叹Excel实在是强大,我知道现在还有更高级的数据处理工具,如Python、R,但对于生活中的大多数计算问题,Excel完全胜任并能处理得很好(不过我还没接触过R,也说不定哪天就真香了),哪怕仅仅是用于加减乘除运算,也比计算器要直观方便些,配合各种函数可以达到编程的效果,我觉得Excel的优势之一就是计算过程非常直观。再加上VBA(当然现在还没有深入到这个地步,大学里教的落伍的VB语言没想到能在这里派上用场),就完全可以用于编程了。
在一个月前,我碰到了一个需求,这个需求由于我的脑洞变得更加具体:我想知道Excel能不能随机模拟。比如我现在有一个刻了ABCDEFGH八种字母的骰子,投掷100次,并记下每次出现的字母,由此获得一串由八个字母组成的随机排列,要求每种字母出现的频率保持一定规律,即每种字母在投掷时具有特定的概率。当投掷的次数趋于无穷时,字母出现的频率就无限接近于概率。
在一般情况下,骰子每个字母出现的概率相同,即1/8,这种模拟非常简单,只需要使用 =RANDBETWEEN(1,6)函数重复100次即可。
但 =RANDBETWEEN(A,B)函数只能表示在[A,B]区间内的随机整数,另一种随机函数 =RAND()表示大于或等于0且小于1的随机数字。我们现在要求每种字母出现的概率不同,如何实现?
可以借用几何的思想。假设有一条长度10的线段, 取a的长度的2,b的长度为3,c的长度为4,d的长度为5,如下图:

由此获得五个分段点,在后文中我称为阈值:

我们随机在线段上取一个点E,取点的过程完全随机,即在任意位置的概率都相同,当E的值在[0,2)区间时,表示选中a,当E的值在[2,5)区间时,表示选中b,当E的值在[5,9)区间时,表示选中c,当E的值在[9,10)区间时,表示选中d。
且得到E落在各区间段上的概率:

E的取值完全随机,由此即可用一个[0,10)之间的随机(整)数实现了a, b, c, d 的非等概率随机过程。
同样的思路,即可用在上述需求中。
Excel实现
在了解这种方法后,我们开始在Excel上动手实现。
首先请容许我给大家看一下最终的实现效果:

更进一步用区域编号说明:

A区表示随机变量分布的模拟,B区用于设定变量及其概率,C区用于设定随机数的区间,D区用于统计生成的随机变量分布,E区用图表表示随机变量分布的实际频率与变量设定出现概率之间的差异。
开始制作吧
C区
为模拟上述线段的效果,我们需要先设计一个区间,如C区表示,由于隐藏了不必要显示的单元格,我们先取消隐藏,看看实际的C区样子。

C区的随机区间(单元格G13)设定会对全局产生影响,包括A区生成随机数的范围和B区的阈值。
为方便的用一个单元格实现对所有随机数范围和阈值的设置,可以将单元格的值带入随机函数中,单元格G12的“0-1000”表示在[0,1000)内生成随机整数(以 RANDBETWEEN(0,1000)函数)或[0,1000)内生成随机有理数(以 RAND()*1000函数时)。“0-1000”是一段文本,0表示下限,1000表示上限,Excel无法直接处理这段文本,因此就有了函数组合来处理。
在Excel中常用的文本截取函数(以字符截取)有三种:
=LEFT(text, [num_chars])=RIGHT(text, [num_chars])=MID(text, start_num, num_chars)想要精确的截取字符串“0-1000”中的0和1000,就需要知道各自字符的长度和位置,在该例中,可以直接看出0和1000各自的长度和位置,用 =LEFT(G13,1)截取0,用 =RIGHT(G13,4)截取1000可太容易了,但如果文本换成其他长度的呢?比如改成“0-10000”或“250-500000”,就需要重新调整函数条件,有些繁琐了。一般情况下,用正则表达式可以很方便地匹配字符串,但Excel并不支持正则表达式(不过可以使用插件或自己在VBA里写个函数支持实现),我们可以另辟蹊径,实现同样的效果。
Excel中有两个函数 SEARCH()和 FIND()可以用于返回字符串中特定字符的位置,在这个例子中两个函数功能相同。从文本格式可以看到通过字符“-”可以定位0和1000的位置。单元格H12表示的即为字符“-”在文本中的位置,具体写法为:
H12 =SEARCH("-",G13)知道了“-”的位置就知道了下限的长度,即 =H12-1,因此H13表示的就是下限的长度,即可截取出下限数值“1”来,为避免出现问题,在结果外面套上VALUE()函数将文本转为数字,写法如下:
H13 =VALUE(LEFT(G13,H12-1))想要获得上限的长度稍显麻烦些,因为我们本身是无法直接通过字符“-”的位置判断上限长度的。我们需要用到字符长度计算函数 LEN()得出完整文本的字符长度,减去字符“-”的位置即可得到上限字符长度 =LEN(G13)-H12,用单元格H14表示:
H14 =VALUE(RIGHT(G13,LEN(G13)-H12))因此,单元格H13和H14分别表示随机区间下限和上限的数值,使用
=RANDBETWEEN($H$13,$H$14-1)或者
=RAND()*$H$14即可生成我们需要的区间内随机数,公式中的 $表示绝对位置,这在大量单元格填充时可以避免引用数据发生位移。
B区
接下来使用B区设定非等概率随机产生的变量和各自概率,以及生成阈值,由于隐藏了不必要显示的单元格,因此也先取消隐藏一下。
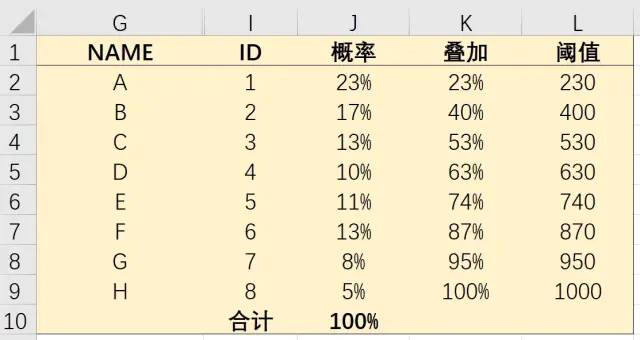
这是一个概率表,让我具体说明各自意义。
NAME
NAME一栏,用于设定表示的随机变量,在这里设定的随机变量对全局产生影响,你也可以写成苹果、桃子、李子、西瓜、葡萄、香蕉、荔枝、猕猴桃、blablabla。
ID
ID一栏表示随机变量在概率表中的行位置,比如A是第一个,就是1,C是第三个,就是3,可以按标序号的方式自动填充,也可以闲着没事用公式 =MATCH(G2,$G$2:$G$9)算出来,往下自动填充就是了。需要注意ID值必须以升序排列。ID起到很重要的作用,之后会讲到。
概率
概率一栏是我们自己设定的概率,大于0小于1内可以随便设置,所有变量概率之和为100%。
叠加
叠加一栏是为了方便而做的一个中间步骤,用于生成阈值,使用时可以隐藏这列,不太懂这一步可以往前看一下阈值的说明。写法如下:
第一行:K2=J2第二行及以后:K3=K2+J3...(往下自动填充)
阈值
阈值一栏用于确定随机变量的边界,求值方式为叠加值乘以随机区间宽度并加下限值。Excel计算时将生成的随机数与阈值比较,并判断出具体表示为哪一个随机变量。接下来马上详细说明,写法为:
L2=K2*($H$14-$H$13)+$H$13...(往下填充)A区

由于A区往下的行内容几乎都是重复填充,因此只以第一行数据说明
“随机1”采用的 =RANDBETWEEN()函数生成随机整数,区间引用之前的H13和H14,写法为:
=RANDBETWEEN($H$13,$H$14-1)“随机2”采用的 =RAND()函数生成随机有理数,区间引用之前的H14,写法为:
=RAND()*$H$14若用随机1的方法生成随机变量,随机区间的范围越大,表示的变量概率精度越高,若用随机2的方法生成随机变量,一般情况下只要设定的区间大于1,对表示的变量概率精度几乎没有影响。
ID值一栏用于计算出生成的随机数所比较的阈值位置,即随机变量在B区概率表中的位置,也即ID值,该列的单元格公式是整个方法的核心,写法为:
=IF(ISNA(MATCH(C2,L$2:L$9,1)),0,MATCH(C2,L$2:L$9,1))+1请容我慢慢解释,首先选择合适的 MATCH()函数,该函数在官网中的解释为:
使用 MATCH 函数在 范围 单元格中搜索特定的项,然后返回该项在此区域中的相对位置。例如,如果 A1:A3 区域中包含值 5、25 和 38,那么公式 =MATCH(25,A1:A3,0) 返回数字 2,因为 25 是该区域中的第二项。
具体语法说明我直接复制官网内容:
MATCH(lookupvalue, lookuparray, [match_type])
MATCH 函数语法具有下列参数:
- lookupvalue 必需。要在 lookuparray 中匹配的值。例如,如果要在电话簿中查找某人的电话号码,则应该将姓名作为查找值,但实际上需要的是电话号码。
- lookup_value 参数可以为值(数字、文本或逻辑值)或对数字、文本或逻辑值的单元格引用。
- lookup_array 必需。要搜索的单元格区域。
- matchtype 可选。数字 -1、0 或 1。 *matchtype* 参数指定 Excel 如何将 lookupvalue 与 lookuparray 中的值匹配。此参数的默认值为 1。下表介绍该函数如何根据 match_type 参数的设置查找值。
Match_type | 行为 |
| 1 或省略 | MATCH 查找小于或等于 lookupvalue 的最大值。 lookuparray 参数中的值必须以升序排序,例如:...-2, -1, 0, 1, 2, ..., A-Z, FALSE, TRUE。 |
| 0 | MATCH 查找完全等于 lookupvalue 的第一个值。 lookuparray 参数中的值可按任何顺序排列。 |
| -1 | MATCH 查找大于或等于 lookupvalue的最小值。lookuparray参数中的值必须按降序排列,例如:TRUE, FALSE, Z-A, ...2, 1, 0, -1, -2, ... 等等。 |
- MATCH 返回匹配值在 lookup_array 中的位置,而非其值本身。例如,MATCH("b",{"a","b","c"},0)返回 2,即“b”在数组 {"a","b","c"} 中的相对位置。
- 匹配文本值时,MATCH 函数不区分大小写字母。
- 如果 MATCH 函数查找匹配项不成功,它会返回错误值 #N/A。
- 如果 matchtype 为 0 且 lookupvalue 为文本字符串,您可在 lookup_value 参数中使用通配符 - 问号 (?) 和星号 (*) 。问号匹配任意单个字符;星号匹配任意一串字符。如果要查找实际的问号或星号,请在字符前键入波形符 (~)。
MATCH()函数需要设置一个匹配值,一块搜索区域,以及匹配方式。匹配方式有小于(1)、等于(0)、大于(-1),以下图序号为1的行为例。
 随机数生成为635,即匹配值为635,搜索区域即为概率表的L列。
随机数生成为635,即匹配值为635,搜索区域即为概率表的L列。
MATCH()函数的匹配规则为从上到下或从左到右匹配,因此为获得唯一有效的ID值,我们使用匹配方式
小于(1),表示查找搜索区域中小于匹配值的最大值的位置,其中搜索区域已满足升序排列。首先从阈值中的230开始匹配,230小于635,匹配,继续往下搜索查找是否还有更大值的小于635,最后发现400、530、630都匹配,从740开始不匹配,因此得到返回值4,但这不是我们想要得结果,因为635实际落在[630,740)区间内,而[630,740)区间内的随机数表示为E,其ID值为5,因此需要对返回值加1,得到5,即为正确结果。但有时我们会遇到小于最小阈值的随机数,即[0,230)内的随机数,如229,根据匹配规则,发现搜索区域内没有匹配到小于229的最小阈值,返回值
#N/A,显然这不是我们想要的结果,因为实际上229在[0,230)区间内,表示为变量A,其ID为1,对于
#N/A的情况我们可以加上无效值判断函数
ISNA(),判断
MATCH(C2,L$2:L$9,1)的返回值是否为无效值,根据判断的结果
FALSE或者
TRUE,进行选择运算,因此我们还需要用到
IF()函数,当
MATCH(C2,L$2:L$9,1)返回值不是无效值,说明匹配到单元格,则
ISNA(MATCH(C2,L$2:L$9,1))返回值为
FALSE,根据设定的
IF()函数规则为
FALSE的情况进行正常计算获取
MATCH(C2,L$2:L$9,1)返回值。若
MATCH(C2,L$2:L$9,1)返回值是无效值,说明没有匹配到单元格,则
ISNA(MATCH(C2,L$2:L$9,1))返回值为
TRUE,根据设定的
IF()函数规则为
TRUE的情况计算返回值为0,最后在最外围将
IF()函数的返回值加1即获得正确的ID值。完整公式再写一遍:
=IF(ISNA(MATCH(C5,L$2:L$9,1)),0,MATCH(C5,L$2:L$9,1))+1INDEX()函数。
INDEX() 函数返回表格或区域中的值或值的引用。
INDEX(array, rownum, [columnnum])首先选定序列
G2:G9,即B区概率表的NAME区域,设定行位置为上述计算出的ID值,即可获得具体的变量,写法为:
=INDEX($G$2:$G$9,D2)...(往下自动填充)验证
根据A区建立一个 数据透视表,放置在D区,其中统计出每一个变量的出现次数以及实际频率。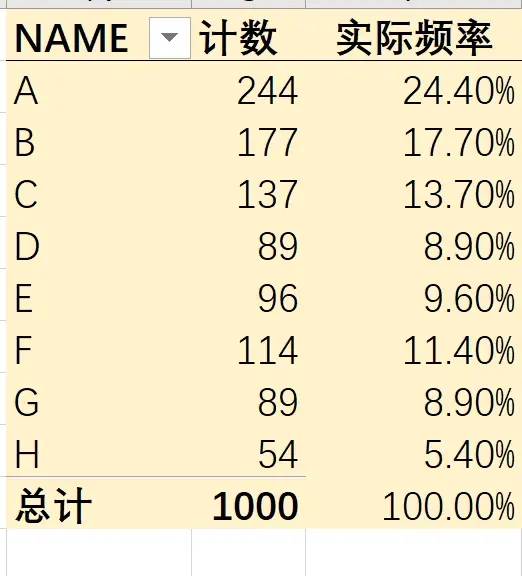 为方便比较设定概率与实际频率之间的差异,我们在E区插入一个图表,并选定概率值与实际值为两个系列值,用折线图表现出来。
为方便比较设定概率与实际频率之间的差异,我们在E区插入一个图表,并选定概率值与实际值为两个系列值,用折线图表现出来。
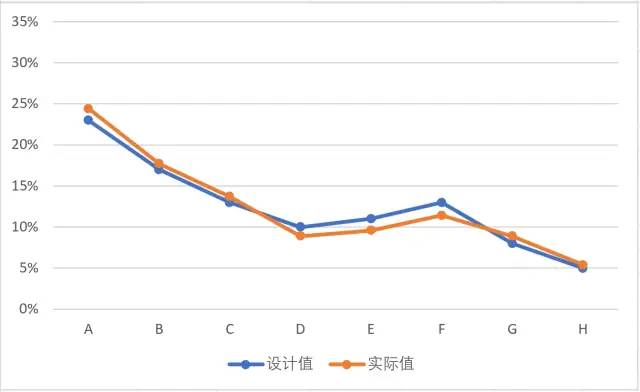 在A区已经有2000个随机数生成,我们可以通过调整数据透视表的数据源区域改变测试的随机数“计数”。首先以重复计数200为例,刷新3次:
在A区已经有2000个随机数生成,我们可以通过调整数据透视表的数据源区域改变测试的随机数“计数”。首先以重复计数200为例,刷新3次:
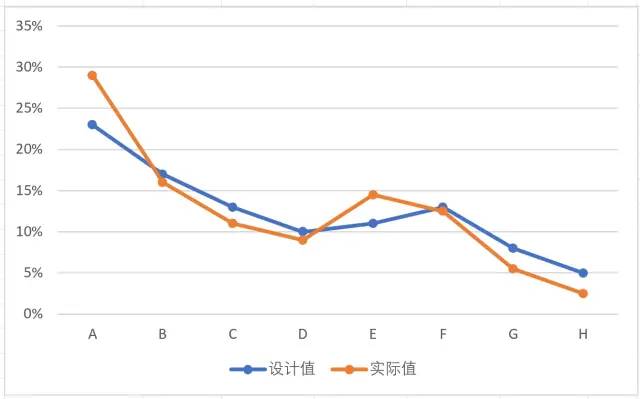
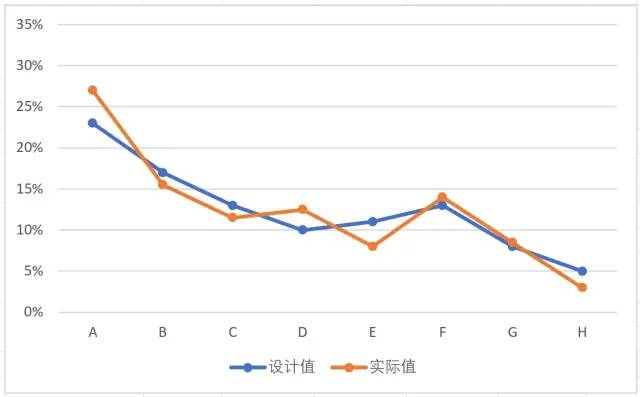
 然后以重复计数2000为例,刷新3次:
然后以重复计数2000为例,刷新3次:
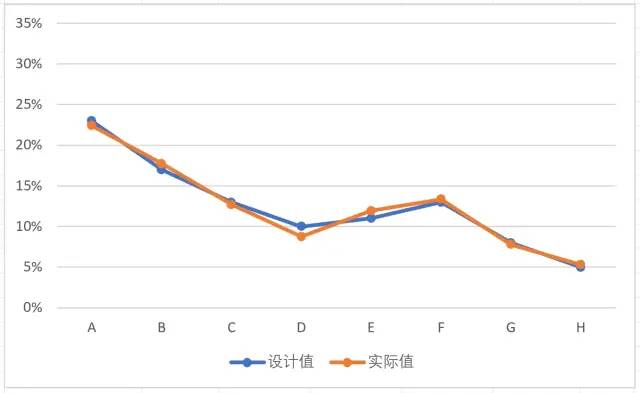

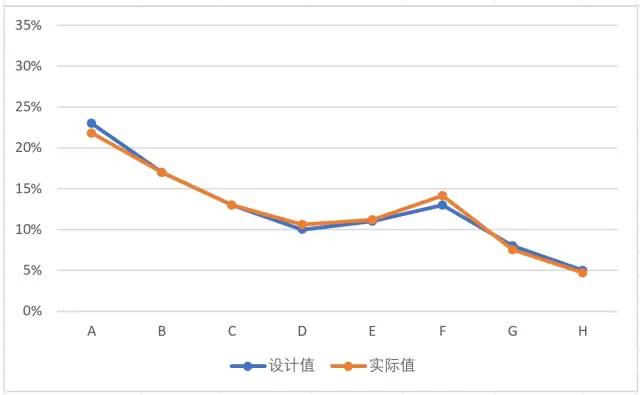 可以看到,计数次数从200到2000,频率与概率之间的拟合程度有了明显提高。
可以看到,计数次数从200到2000,频率与概率之间的拟合程度有了明显提高。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









