






Numpy和Pandas的关系:
- 二者都是Python的三方库
- Numpy是基本的数值计算库
- Pandas是处理不同变量的表格计算的库
- Pandas有两个核心数据结构series 和 dataFrame 一个dataframe可以包含多个series
- 两者相辅相成,pandas一些数据处理库是建立在numpy基础上的。
Numpy
为什么需要用到它?
因为Python中的array模块,不支持多维和运算模块,不适合做数值计算;
Numpy提供两种基本对象:
- ndarray N维数组对象,是存储单一数据类型的多维数组;
- ufunc,是对数组进行处理的函数。
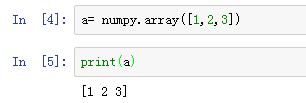
输入数组并打印:
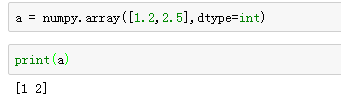
指定数组类型:
查看这个数组的类别:
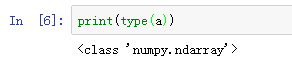
可以看到数组是ndarray。
查看到它其实是一个序列:
索引数组中的元素:
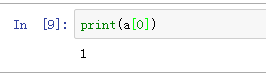
这个数组中第0个元素是1。
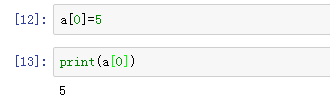
重新给第0个元素赋值,并打印:
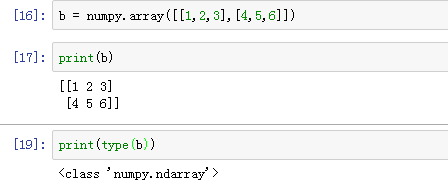
建立数组,打印,并查看数组类型:
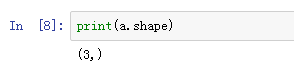
查看shape:

2行3列。
二维数组索引 a[行号,列号]:

特殊数组:
Numpy.zeros()
分别生成一维序列,和二维(2行4列)

D = numpy.zeros([2,4]) 和D = numpy.zeros((2,4))一样
Numpy.ones()
全1数组:

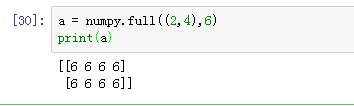
Numpy.full():
生成全是某个值的数组
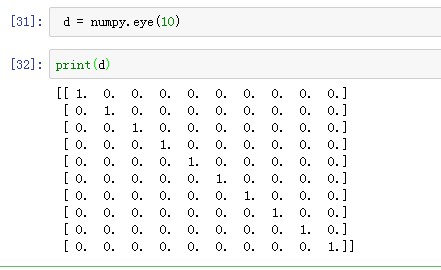
Numpy.eye():
单位矩阵,由于单位矩阵行列相同,所以只需要输入一个数字:
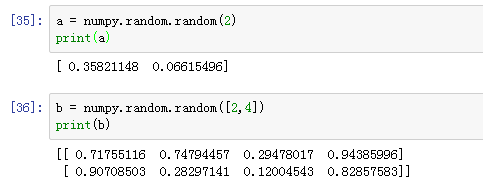
numpy.random.random():
随机数组:
切片和索引:
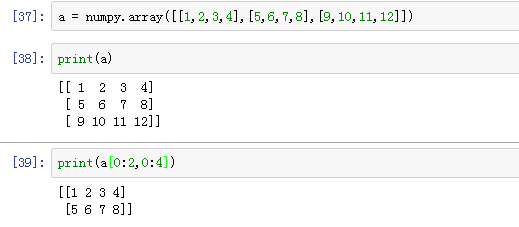
a[0:2,0:4],意思是索引从第0行到第1行,第0列到第3列。
间隔提取:

第一个冒号前后表示开始和结束位置,第二个冒号后面表示间隔的大小。
使用其他序列来索引:

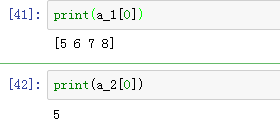
冒号写法不同的区别:

可以看到上面一种方式,输出的是2维数组,下面一种却是1维序列。
分别输出第0个元素:
四种读取多维数组元素的方式:


总结这4种方法,原则就是定义清楚行列号。
Bool索引:

创建数组函数:
Numpy.arange(start , stop, step, dtype)
生成序列:

numpy.linspace(start,stop,num,endpoint,retstep,dtype):

numpy.logspace(start,stop,num,endpoint,base,dtype):

Pandas:
pandas的数据类型主要是:Series和DataFrame:
Series:
可以和pandas生成的序列对比查看:

DataFrame:
生成一个3行4列dataframe
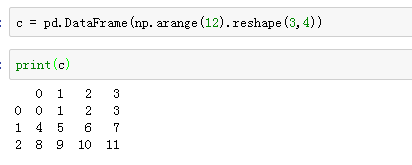
取第0列两种方法:
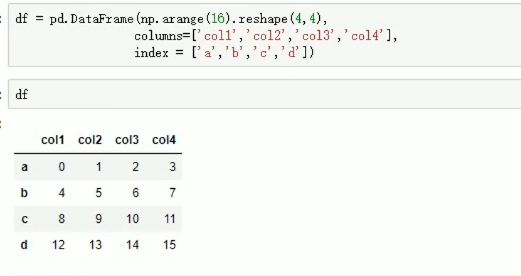
生成数据时制定列名和index:
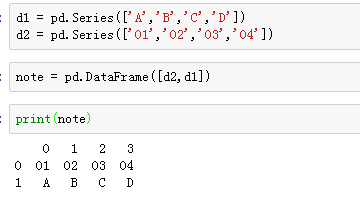
拼接序列:
给dataframe添加列:

查看列名、index和值:

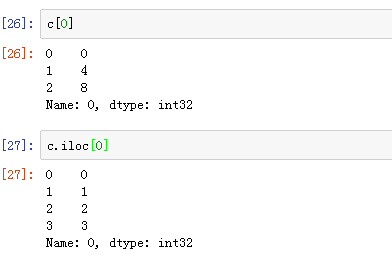
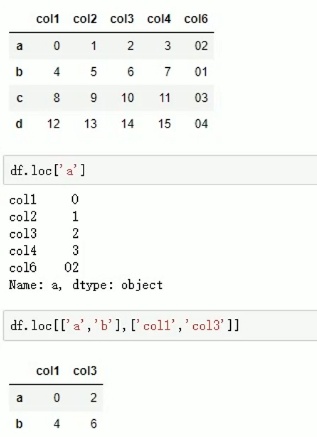
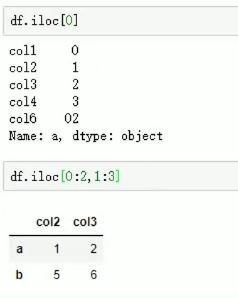
Loc和iloc的区别:loc通过索引访问,iloc通过行和列标访问:
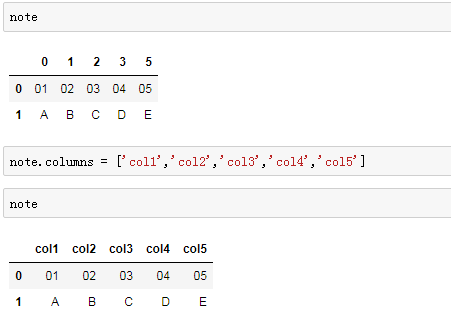
重命名列名:
dropna(axis=1,how=’all’):这个意思是,删除列,当这列所有为空时才删除。当how=’any’,表示只要有空就删除,且注意,dropna并不是删除原数据,只是新生成了一个dataframe。
fillna(0):表示用0去替换。
fillna(note[‘5’.mean()]):用这列的均值去填充空值。
以上即为pandas和numpy的数据结构总结,再花点时间学习一下各自的计算函数,这两个包就熟悉得差不多了。















 6万+
6万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









