





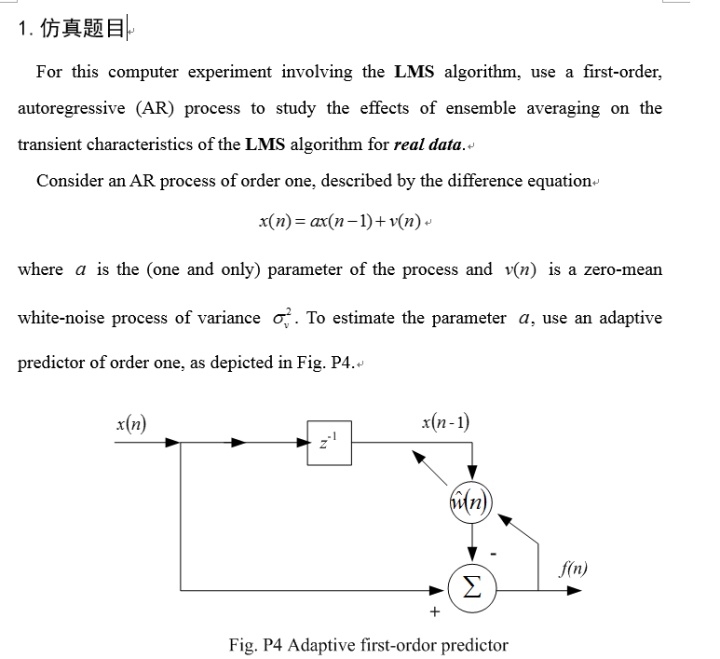






图1 一阶自适应预测器权值的瞬态特性( =0.04)
图一中,显示了平均的 学习曲线及一个实现,其中实线所示为某一单独实验中的得到的权值瞬态特性曲线,虚线表示的是在100次实验后得到的一个平均结果。观察两条曲线发现,虚线较实线平滑。这是因为集平均实现采用的是100次试验的平均处理,平滑了单一处理中梯度噪声的影响。
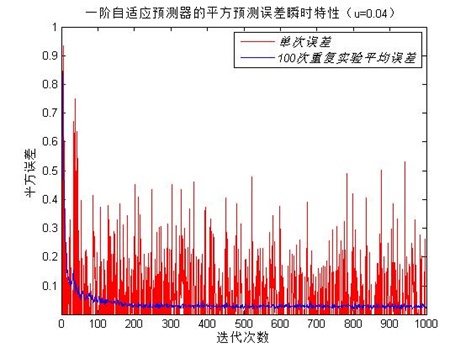
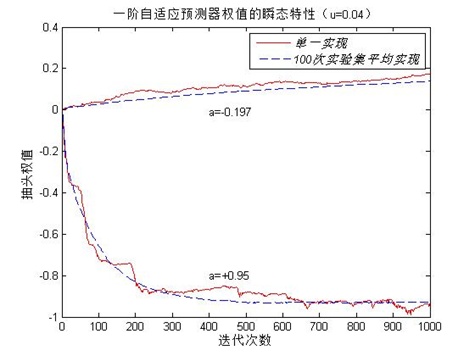
图2一阶自适应预测器的平方预测误差瞬时特性( =0.04)
图二中,是相应的一阶自适应预测器的平方预测误差与迭代次数的关系图,可见,LMS算法单一实现的学习曲线呈现出严重的噪声的形式,但经总体平均后得到了一条较稳定的曲线,即 =0.04时的一阶自适应预测器的学习曲线。
图3 一阶自适应预测器的学习曲线(变步长 )
在图三中,我们可以看到当步长参数分别取0.01、0.04和0.08时均方误差的学习曲线。图中显示, 影响收敛速度,也影响稳态值。当 时算法大约在100次迭代收敛,而当 时大约需要250次迭代才收敛,而前者的稳态值要比后者的高。当 时需要700次的迭代。综上所述随着步长因子的减小,LMS算法就需要进行更多的迭代才能收敛,即到达最优点的时间越长。
6.结论
由以上实验结果分析可归纳为:
(1)单一实现的轨迹和学习曲线明显是随机的或是“有噪声的”,而随着实验次数的增多,其平均结果趋于平滑。即总体平均有一个平滑的作用。
(2)LMS算法的收敛速度依赖于步长 u 。在允许的范围内 值取得越大,收敛速度越快,反之步长越小,收敛速度就越慢。
LMS算法是一种相对简单而性能又十分优越的自适应算法。在对LMS算法进行应用或设计的时候,我们可以用变步长方法来缩短其自适应收敛过程,为了达到快速收敛的目的,必须选择合适的步长因子 的值,一个可能的策略是尽可能多的减少瞬时平方误差,即用瞬时平方误差作为均方误差的简单估计。LMS算法的上述特点使得LMS滤波器越来越多的应用于更广泛的领域。
附 录:
clc
clear
N=1000;
M=100;
w=zeros(M,N,3,2); f=zeros(M,N,3,2);
for l=1:2,
if l==1 a=0.95;
else a=-0.197;
end;
for d=1:3,
if d==1 u=0.01;
else u=0.04*(d-1);
end;
for k=1:M,
v=0.169*randn(1,N);
x(1)=1;
for n=2:N,
x(n)=-a*x(n-1)+v(n);
f(k,n,d,l)=x(n)-w(k,n,d,l)*x(n-1);
w(k,n+1,d,l)=w(k,n,d,l)+u*x(n-1)*f(k,n,d,l);
end
end
end
end
for l=1:2
for d=1:3
for n=1:N,
fea(n,d,l)=0;
wea(n,d,l)=0;
for m=1:M
fea(n,d,l)=fea(n,d,l)+f(m,n,d,l)^2;
wea(n,d,l)=wea(n,d,l)+w(m,n,d,l);
end
fea(n,d,l)=fea(n,d,l)/M;
wea(n,d,l)=wea(n,d,l)/M;
end
end
end
n=1:N;
figure(1)
plot(n,w(1,n,2,1),'r-',n,wea(n,2,1),'b--',n,w(1,n,2,2),'r-',n,wea(n,2,2),'b--');
title('一阶自适应预测器权值的瞬态特性(u=0.04)')
xlabel('迭代次数'),ylabel('抽头权值')
legend('it单一实现','it100次实验集平均实现')
text(400,-0.01,'a=-0.197')
text(400,-0.8,'a=+0.95')
figure(2)
plot(n,f(1,n,2,1),'r-',n,fea(n,2,1),'b-');
title('一阶自适应预测器的平方预测误差瞬时特性(u=0.04)')
axis([0 1000 0.001 1]);
xlabel('迭代次数'),ylabel('平方误差')
legend('it单次误差','it100次重复实验平均误差')
figure(3)
semilogy(n,fea(n,1,1),'b-',n,fea(n,2,1),'g-',n,fea(n,3,1),'r-');
axis([0 1000 0.01 1]);
title('一阶自适应预测器的学习曲线(变步长u)')
xlabel('迭代次数'),ylabel('均方误差')
legend('itu=0.01','itu=0.04','itu=0.0















 2981
2981











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









