






背景
酷家乐是从 16 年初开始进行服务化改造的,因为一些特殊原因,无法直接使用主流的dubbo 或 spring cloud,因此酷家乐研发团队在开源的基础上做了二次开发,迅速上线了一套定制型的微服务框架。
和其他微服务框架类似,酷家乐自己定制的微服务框架也有专门的服务网关,今天要讨论的就是服务网关中存在的一些问题。
何为服务网关?服务网关封装了系统内部架构,为每个客户端提供一个定制的 API。此外,服务网关还会提供如身份验证,限流,熔断,安全等功能。
所有的客户端都通过统一的网关接入微服务,在网关层处理所有的非业务功能。通常,网关也是提供 REST/HTTP 的访问 API。服务网关会将客户端的请求转发到能够正常处理该请求的微服务当中。
下图简单阐述了服务网关在常见系统中所处的位置和作用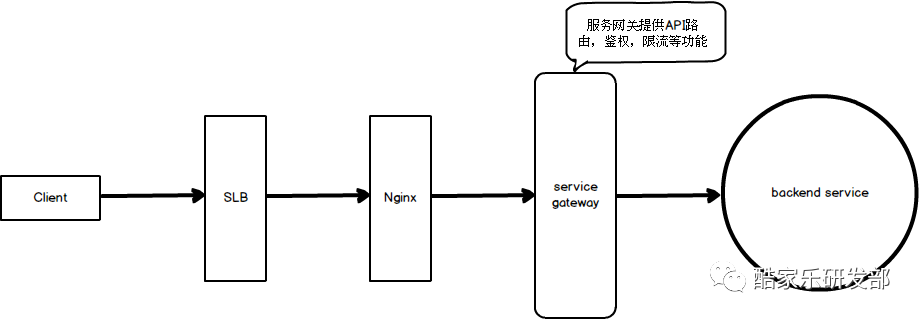
下面会逐步介绍酷家乐在不断迭代微服务框架过程中,在服务网关处踩的各种坑。
故障回顾
高CPU占用
16 年某日,服务网关持续 CPU 报警,排查定位过程比较简单,随意挑选了一台服务器并获取其 thread dump,观察到大量的线程都在做以下操作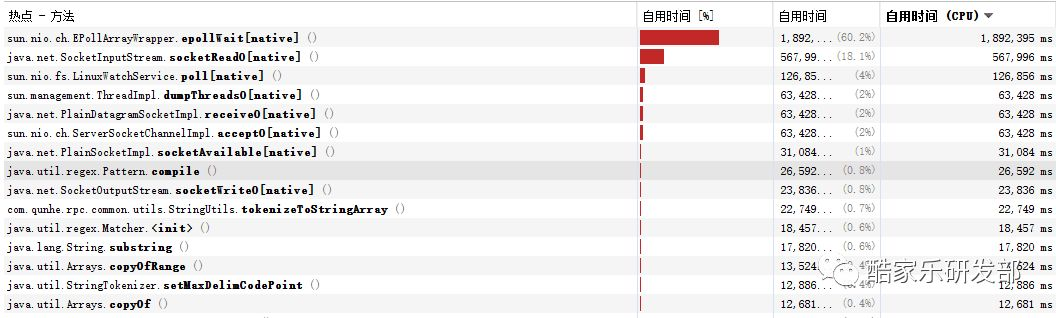
上图中,除了 IO 操作之外,主要就是字符串操作占用 CPU 时间。
最初期的服务网关基本就是根据 Spring MVC 的 Request Mapping 流程来模拟,对请求进行路由,查找匹配的服务并转发。
这里存在的问题也很明显,因为要遍历所有的 API Pattern,效率比较低,此外,由于有大量的 API 使用了 Restful 风格,包含 PathVariable 的 API 数量比较多,因此正则匹配次数也特别多,所以 CPU 占用率居高不下。
随着系统不断庞大,这个问题会越来越明显。
研究了前面所述的 Pattern 格式,我们发现在 REST 风格的 API URL 中,存在以下规律:
URL 基本都以“静态字符串”开头,形成了用于区别不同 service 的“名字空间”,动态部分一般都在URL Pattern的尾部。
根据这个规律,我们发现用字典树的结构来组织 URL Pattern 可以大大降低 URL 匹配所花费的 CPU 时间:
对于每个 URL Pattern,我们截取第一个动态表达式之前的“静态前缀”,形成一颗字典树。根节点代表的 token 为空,其余每个节点中包含两个集合:private static class Node {
Map children;// 子节点
List patterns;// 当前 URL 前缀所匹配的 Patterns
}
用该规则构建的一个字典树例子如下: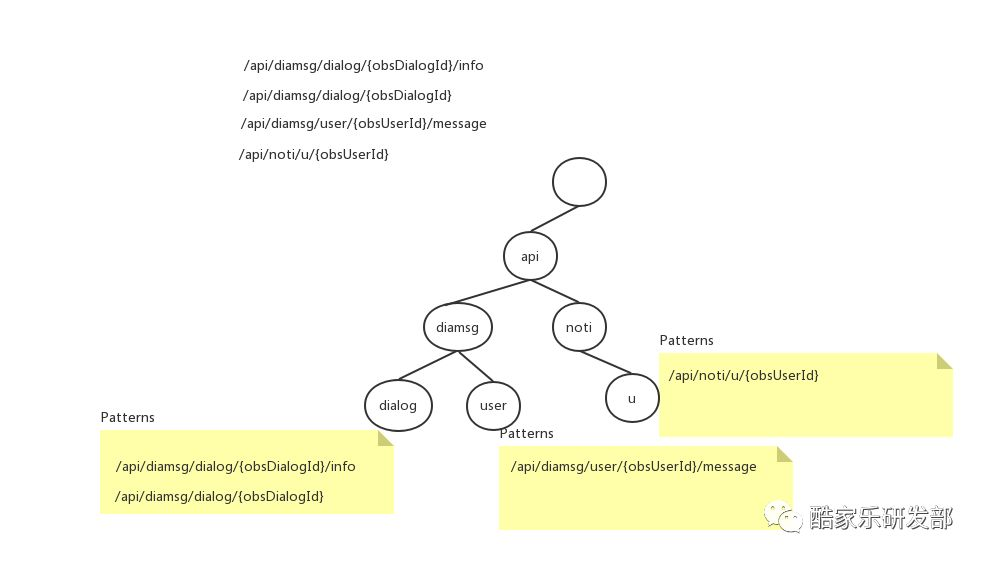
对于每个请求,我们进行以下操作:用“/”切分 URL,得到多个 token
从字典树的根开始,从上往下寻找匹配的最长路径
取出最后匹配的 Node 节点中的 patterns 集合,遍历该 patterns 集合,找出最终匹配的 URL Pattern
用字典树结构重写了整个 URL Route 逻辑之后,CPU 占用时间明显下降,达到了优化的目的。
FullGC
17年某个周四下午开始,服务网关开始间接性 FullGC,每次 FullGC 时间持续大概 2-3 秒,服务网关负载瞬时飙高后马上恢复。
当时出现这个报警有点不可理解,那一周因为峰会原因暂停了部署,所以所有服务的代码都是没有改变的,并且根据监控的数据来看,当时的访问量也没有增加太多,和之前几天的差不多。究竟为何产生 FullGC,还得看客观数据。
为其中一台服务器添加了 HeapDumpBeforeFullGC 和 HeapDumpAfterFullGC 后继续观察,获取到两份 dump 文件对比后发现,被 GC 掉的主要是 int[] 和 SimpleScalar 两类对象。
这里的 int 数组和 SimpleScalar 大量都是 unreachable,SimpleScalar 是 freemarker渲染产生的,因为历史原因,还有少部分页面渲染是在服务网关处理的,观察监控中 GC 时段的页面请求,没有发现异常。并且 SimpleScalar 不是最主要成员,因此排除相应可能性。
那么这些 int 数组到底是哪里来的?
这里还有一个疑点,HeapdumpBeforeFullGC 获取到的 dump 文件居然只有 1.4G 的大小,远远小于堆大小,这并不符合正常逻辑。
查看了 FullGC 前的部分 gclog,发现这段时间有比较多的 mix-gc,并且看到有不少 G1 Humongous Allocation 等信息。
看到这些,便能联想到为何那份 FullGC 前的 dump 文件小那么多了。
服务网关使用的是 jdk8+G1GC,G1 的各代存储地址是不连续的,每一代都使用了 n 个不连续的大小相同的 Region,每个 Region 占有一块连续的虚拟内存地址。
humongous object 即大小大于等于 Region 一半的对象,有如下几个特征:
humongous object 直接分配到了老年代空间,防止了反复拷贝移动。
humongous object 在 global concurrent marking 阶段的 cleanup 和 Full GC 阶段回收。
在分配 humongous object 之前先检查是否超过 initiating heap occupancy percent 和the marking threshold, 如果超过的话,就启动 global concurrent marking,为的是提早回收,防止 evacuation failures 和 Full GC。
因此猜测之所以 dump 文件大小差那么多的原因就在于产生了大量的 humongous object,而这些对象在 dump 之前就先被回收了。
通过监控和 GC 日志可以看出这些对象是短时间内迅速产生的。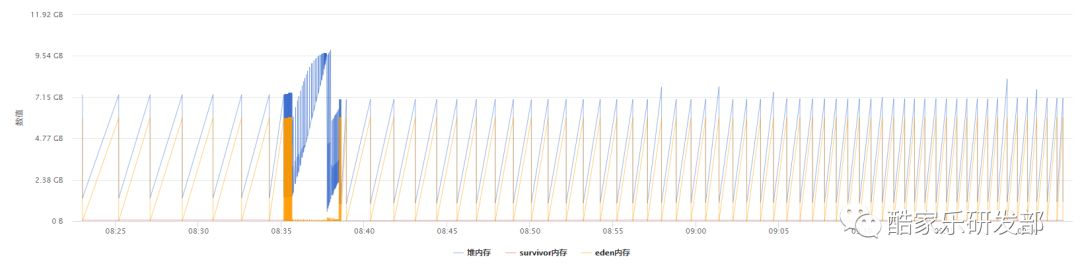
为了证实猜想,并且找到产生这些对象的来源,通过监控和报警的数据,将其中一台即将执行 FullGC 的服务器移出线上服务,并且对其执行 dump,此时获取到的内容和之前 1 个多 G 的截然不同。
以下是新的 dump 解析结果: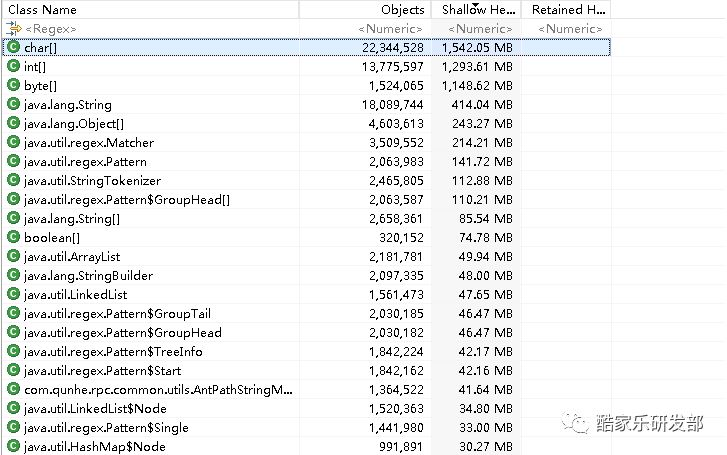
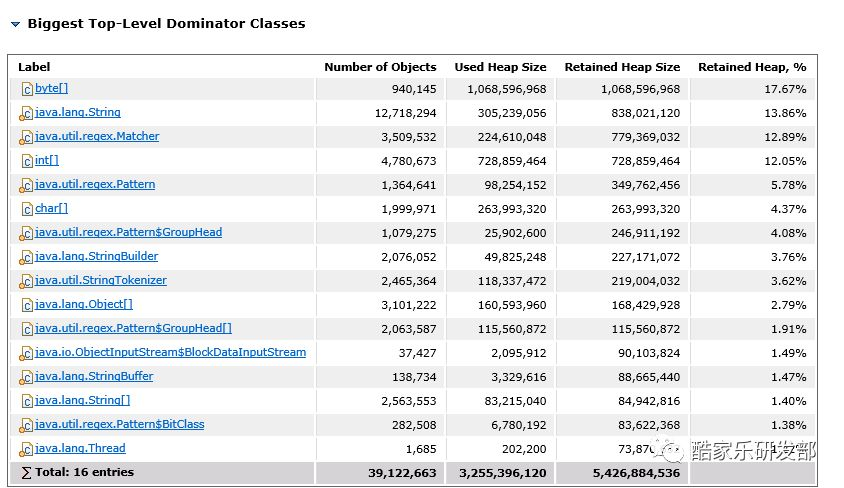
这就能够很清楚地看到,大量的 int 数组是 Matcher 和 Pattern 对象产生的,而这两个对象就直接能想到是路由匹配时的正则产生的。
Pattern Compile 十分消耗性能,且会产生大量临时对象,之前这里采用的是 spring3 中 PathMatcher 的实现,这里会在每次请求时都生成对应的 Pattern。
知道了原因以后就可以做对应的优化了,优化目标是减少 Pattern 的 Compile 和 Matcher 对象的创建。
spring在4.0 版本以后也对 AntPathMatcher 做了优化,AntPathMatcher 内部对 Pattern 和 Matcher 都进行了缓存,并且对缓存大小进行了设置,当缓存大小大于 CACHE_TURNOFF_THRESHOLD 时,该缓存功能会被关闭
CACHE_TURNOFF_THRESHOLD 默认为 65536
具体实现可以参照 spring4 中 AntPathMatcher 的 getStringMatcher 方法和 tokenizePattern 方法。
优化部署后 FullGC 不再发生,该问题得到解决。
进一步优化
然而这里的优化还可以更进一步
spring的匹配实现还默认使用了 SuffixPaternMatch 和 TrailingSlashMatch,这些功能其实目前我们都没有用到,完全做了多余的判断,产生了多余的对象,这里可以都设置为 false。
上面提到的优化方式总结下来思路基本都是相同,减少正则匹配次数,但是这没有解决最根本的问题,无法很好地应对未来的扩容。
之前的网关效率最低之处在于,对于所有请求都需要进行遍历查找。那么如何解决这个问题呢?
其实对于这个问题,nginx 算是老司机了,nginx 的 location 基本都会基于前缀匹配来进行转发到对应的 upstream。
spring cloud 的 zuul 的实现也是类似,微服务场景下,后端微服务其实就对应了nginx 的 upstream。
因此,需要对微服务框架进行改造。
改进一:每个微服务可以设置自己的路由规则,服务网关优先根据路由规则进行匹配,直接将匹配到的请求转发到对应的服务。
例如 diyrenderservice 设置了路由规则namespace:drs
那么所有以/drs开头的请求就会直接转发到 diyrenderservice
但是如果这个路由规则没有命中,或者实际提供对应服务的微服务没有设置路由规则的话该怎么办呢?
这里只能退化为遍历查找,考虑到历史原因,还有很多 api 是以 /api 开头,并且后面几级的命名没有 namespace 可以区分,完全无规律,并且分布在多个服务中,这些都是服务拆分时的后遗症。
如果要把这些 API 都规范掉需要投入比较大的重构精力和时间,因此为了兼容,需要在路由配置没有匹配到的情况下,降级为遍历查找。
改进二:客户端请求指定服务名称,客户端请求每个 API 时都指定对应的服务名称,添加一个特殊的 header 存放该 API 对应的服务名称,服务网关先检查当前请求是否有这个特殊的 header,如果有,则直接转发到指定服务。
总结
虽然通过代码优化解决了 PathMatch 的问题,但是这类问题的产生和我们的 API 命名也有比较大的关系,部分 API 命名特别长,并且都是 PathVariable,对应的 PrefixTree 高度已经超过了8层,产生的 Pattern 数量也比较多,在路由的时候代价都比较高。
归根结底,路由部分最大的瓶颈在于正则匹配,而产生大量正则匹配的根源是 Restful 风格的 PathVariable。
反观一下互联网模式的数据库表结构设计,为了业务扩展和性能考虑,基本都是采用反范式的思路去设计,更多采用空间换时间的做法并保证最终一致性。这和学院派的范式设计截然相反。
回到这个问题上,API 命名似乎也走上了这条路,主流的 Restful 风格命名成了性能瓶颈的根源之一,人为将 PathVariable 都转换为 RequestParameter 可破。但是对于有 SEO 需求的页面来说,Restful 的写法还是需要的。当然我们也不能一棒子打死,就规定不能用 Restful 的写法了,只是从规范角度看,少写 Restful 风格的 API 可以提升性能。
关注我们
酷家乐质量效能团队热衷于技术的成长和分享,几乎每个月都会举办技术分享活动(海星日),每半年举办一次技术专题竞赛分享(火星日),并将优秀内容写成技术文章。
我们尽可能保障分享到社区的内容,是我们用心编写、精心挑选的优质文章。如果您想更全面地阅读我们的文章,请您关注我们的微信公众号"酷家乐技术质量"。















 502
502











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









