



笔记:介绍cdn是什么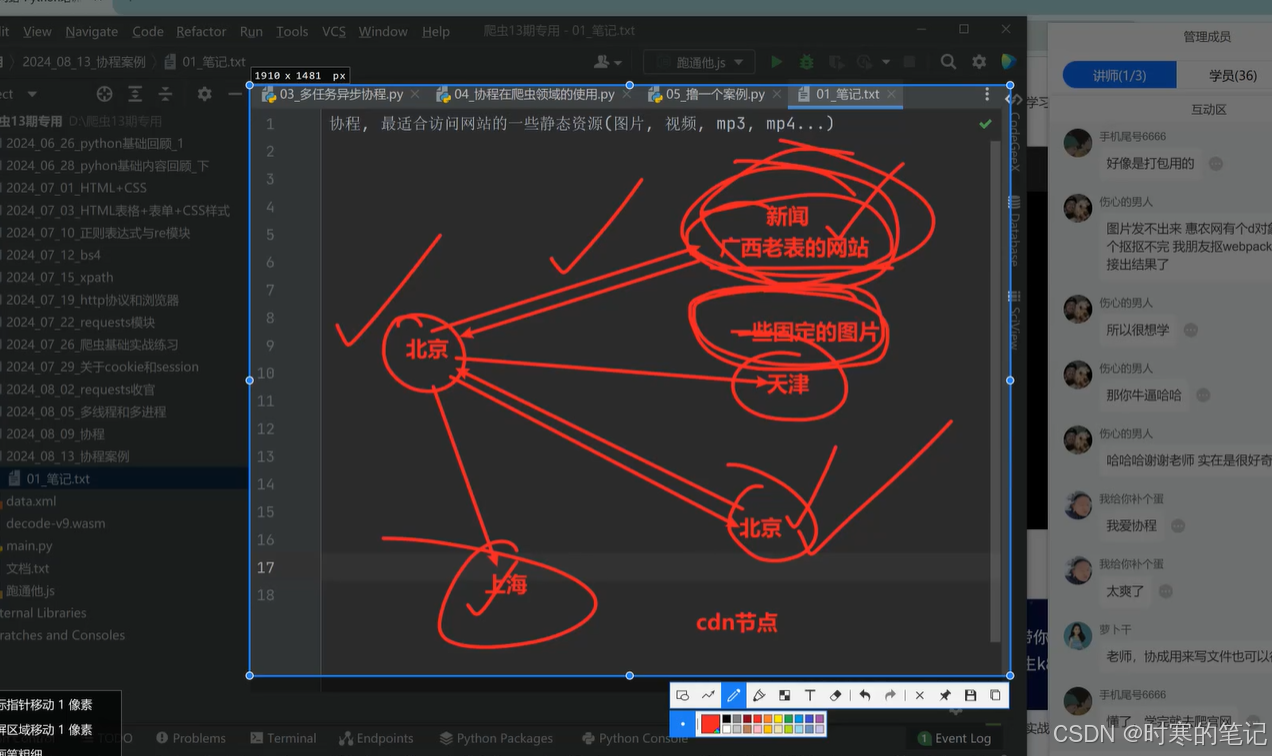
笔记2:什么时候用协程?大批量任务的时候
import requests
import re
from urllib.parse import urljoin
import asyncio
import aiohttp
import aiofiles
# 本次作为练习,代码还需要填参数,整理
# 建议将网页看一遍截图,方便下次回顾一下为什么re来正则匹配更方便啥的
session = requests.session()
head = {...}
session.headers = head
def get_m3u8_url(url):
resp = session.get(url)
obj = re.compile(r'"link_pre":"","url":"(?P<m3u8_url>.*?)",', re.S)
m3u8_url = obj.search(resp.text).group("m3u8_url")
m3u8_url = m3u8_url.replace("\\", "") # 去掉\
# 问题分析(为什么re匹配不到)
# 1、页面源代码不对
# 2、正则写的不对
""""
<script type="text/javascript">
var player_aaaa = {
"flag": "play",
"encrypt": 0,
"trysee": 0,
"points": 0,
"link": "\/vodplay\/37759-1-1.html",
"link_next": "\/vodplay\/37759-1-2.html",
"link_pre":"","url":?????????????????????????????????????????????????????"https:\/\/v7.tlkqc.com\/wjv7\/202309\/12\/tQe5up7W5v1\/video\/index.m3u8",
"url_next": "https:\/\/v7.tlkqc.com\/wjv7\/202309\/12\/gNjMb1dMF91\/video\/index.m3u8",
"from": "wjm3u8",
"server": "no",
"note": "",
"id": "37759",
"sid": 1,
"nid": 1
}
</script>
"""
return m3u8_url
# 加快速度
# return "https://v7.tlkqc.com/wjv7/202309/12/tQe5up7W5v1/video/index.m3u8"
def download_m3u8(url):
resp = session.get(url)
with open('index.m3u8', mode='wb') as f:
f.write(resp.content)
def has_next_m3u8():
with open('index.m3u8', mode='r', encoding="utf-8") as f:
for line in f:
if line.startwith("EXT-X-STREAM-INF"):
return f.readline().strip() # 读取下一行,作为下一层M3U8的地址
return False # ???? A:也就是读的到东西就有,没有读到就没有
# 下载单独一个ts
async def download_one(ts_url, file_name, sem):
print(file_name, "开始下载")
async with sem: # 控制并发量的, 你的windows是有上限的..
while 1:
try:
# 下载
# 不能所有的任务都傻等这,不知道什么时候才能回得来
tm = aiohttp.ClientTimeout(total=10) # 设置10秒的等到时间,超过了就报错
async with aiohttp.ClientSession(headers=head, timeout=tm) as sess:
async with sess.get(ts_url) as resp:
content = await resp.content.read()
async with aiofiles.open(f"source/{file_name}", mode="wb") as f:
await f.write(content)
break
except Exception as e:
print(file_name, "下载失败,即将重新下载")
print(file_name, "下载完毕")
async def download_all_ts(m3u8_url):
tasks = []
# 信号量,控制并发量
sem = asyncio.Semaphore(100)
f2 = open("new_index.m3u8", mode="w", encoding="utf-8")
with open("index_m3u8", mode='r', encoding="utf-8") as f:
for line in f:
line = line.strip() # 一定要有,否则文件下载地址是不对的
if line.startwith("#"):
f2.write(line)
f2.write("\n")
continue
if not line.startwith("http"):
line = urljoin(m3u8_url, line)
# line就是ts下载地址了
# 这里取文件名字
file_name = line.split("/")[-1]
f2.write(file_name)
f2.write("\n")
# 去下载就可以了,每一个line就是一个协程任务
t = asyncio.create_task(download_one(line, file_name, sem))
tasks.append(t)
await asyncio.wait(tasks)
f2.flush()
f2.close()
def merge():
# 1. 可以直接用py代码合并... 参考4期的协程案例
# 2. 用ffmpeg第三方工具来合并
# 2.1 安装
# github已经开源的工具. 需要自己去编译. 很麻烦
# 直接用樵夫提供的安装包即可
# 1. 下载, 解压缩到硬盘的任何为止
# 2. 复制bin路径
# 3. 丢到环境变量的Path变量中.
# 4. 重启黑窗口. 输入ffmpeg. 有反应就成功了.
# 5. pycharm的terminal可以充当黑窗口的角色, 但是需要
# 更换terminal的引擎
# files -> settings -> tools -> terminal-> 把powershell更换成cmd
# 2.2 使用
# ffmpeg -i xxx.m3u8 -c copy xxx.MP4
# 在合并之前, 把所有的jpeg, 更换成ts. 重新生成一个新的m3u8文件
print("开始合并, 第一件事儿, 处理M3U8")
print("正常情况下, 你应该先去判断是否是jpeg, 如果不是jpeg, 直接合并就可以了")
with open("new_index.m3u8", mode="r", encoding="utf-8") as f1, \
open("ok/new_new_index.m3u8", mode="w", encoding="utf-8") as f2:
for line in f1:
# 生成新的m3u8
f2.write(line.replace(".jpeg", ".ts"))
# 处理文件
# 所有的jpeg, 需要把前面4个字节更换成\xff
if line.startswith("#"):
continue
line = line.strip()
# jpeg文件
with open("source/" + line, mode="rb") as f3,\
open("ok/" + line.replace(".jpeg", ".ts"), mode="wb") as f4: # ts文件
f4.write(f3.read())
f4.seek(0) # 鼠标光标重新回到起点的意思
f4.write(b"\xff\xff\xff\xff")
print("jpeg处理完毕")
# 执行合并命令
# 进入到ok文件夹
import os
os.chdir("ok") # 让程序进入ok文件夹
# 执行合并命令
rt = os.popen("ffmpeg -i new_new_index.m3u8 -c copy xxx.mp4").read()
print(rt)
# 回到原来的文件夹
os.chdir("../")
print("合并成功")
def main():
url = "https://www.nangua2025.com/vodplay/37759-1-1.html"
# 访问url获取m3u8下载地址
m3u8_url = get_m3u8_url(url)
print("m3u8地址为:", m3u8_url)
# 2、 下载m3u8文件
download_m3u8(m3u8_url)
print("下载m3u8成功", m3u8_url)
# 3、判断是否有下一层 ??????
m3u8_url_2 = has_next_m3u8()
while m3u8_url_2:
# 有下一层
m3u8_url = urljoin(m3u8_url, m3u8_url_2)
# 下载文件
download_m3u8(m3u8_url)
print("下载m3u8成功", m3u8_url)
# 判断是否还有下一层
m3u8_url_2 = has_next_m3u8()
print("是否有下一层")
# 4、下载所有的ts/???文件
loop = asyncio.get_event_loop()
loop.run_until_complete(download_all_ts(m3u8_url))
# 5、ts文件的合并
merge()
if __name__ == '__main__':
main()
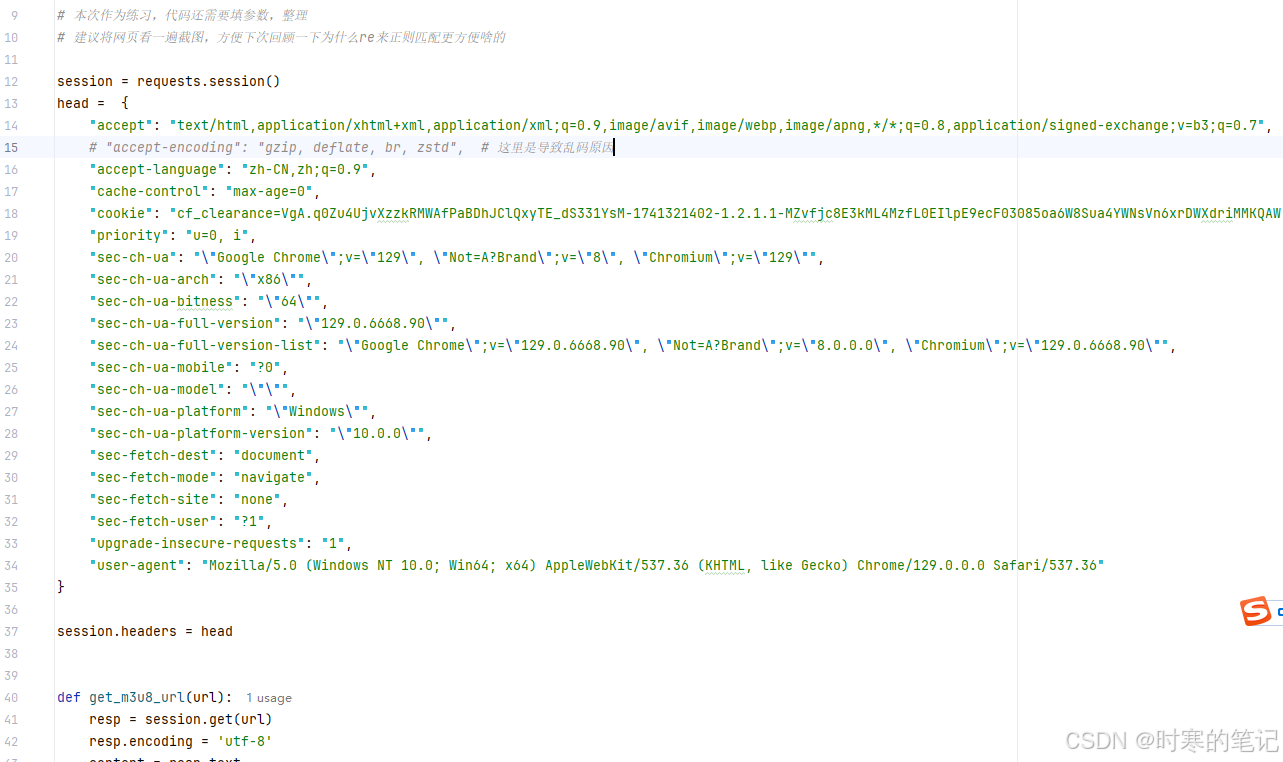
注意的点1:br压缩问题,导致这个返回内容乱码。
比如15行这一段(注释的这段,一定要小心!):
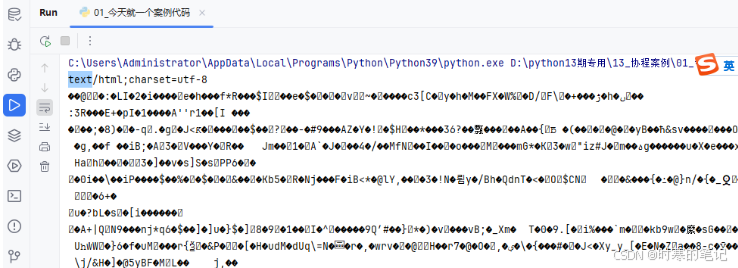
不然就会如下乱码:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









