





在很多刚学习自动化的可能会认为我只需要会运用selenium,我只需要在一个编辑器中实用selenium +java编写了一些脚本那么就会自动化了,是真的吗?答案肯定是假的。自动化肯定是需要做到真的完全自动化,那如何实现呢?接着往下看。
首先我们需要准备的环境:
1、jdk环境配置好
2、maven环境配置
3、jenkins环境配置(jenkins.war的包)
4、在eclipse中创建一个maven工程(不是java工程,为什么?因为java工程还需要自己去下载selenium等等包然后引入,但是maven工程只需要在pom文件中将各种包的配置添加进去就行)
5、在maven工程中的pom.xml文件中将selenium、testng包引入,其他的都不要。
环境准备好之后就准备创建包,写代码吧。
我这里拿pageobject做为例子,首先看一下我工程的一个目录结构:
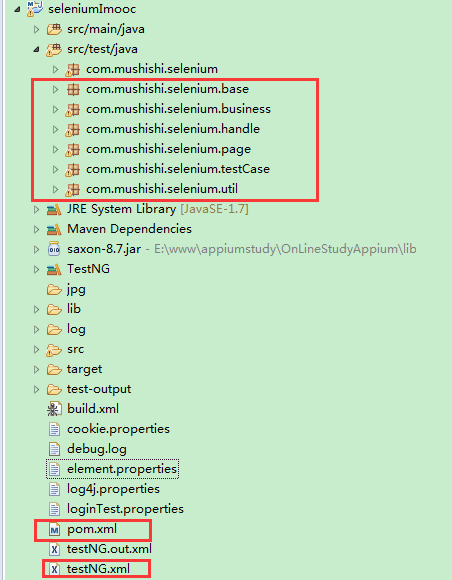
在这个结构中会拿部分来讲:
base:主要是放driver的基类,他主要是对webdriver进行了第二次封装
business、handle、page这三个类主要是pageobject模型中实用的页面分离,page里面放的全是页面元素,handle放的是该页面元素的操作、business放的是该页面的操作元素之间的一些业务。
testcase:顾名思义就是放我们case的地方
util:一些工具类的存放地方
下面的testNG.xml就是我们testng的一个配置文件,如果我们需要用testng运行那么就直接右键运行。
pom.xml:是我们maven的文件,我们所有的依赖文件都添加在里面,当我们使用jenkins来集成时,jenkins里面配置的就是这个pom文件
首先来看我们的DriverBase的代码:
public class DriverBase {
public WebDriver driver;
public DriverBase(String browser){
SelectDriver selectDriver =new SelectDriver();
this.driver = selectDriver.driverName(browser);
}
/**
* get封装
* */
public void get(String url){
driver.get(url);
}
/*
* 返回
* **/
public void back(){
driver.navigate().back();
}
/**
* 点击
* */
public void click(WebElement element){
element.click();
}
/**
* 获取当前url
* */
public String getUrl(){
return driver.getCurrentUrl();
}
/**
* 获取title
* */
public String getTitle(){
return driver.getTitle();
}
/**
* 关闭浏览器
* */
public void close(){
driver.close();
}
}
在这个里面我们对webdriver常用的一些方法进行了一个第二次封装。
当我们把基础的封装了后,我们再次看我们整个框架的结构:
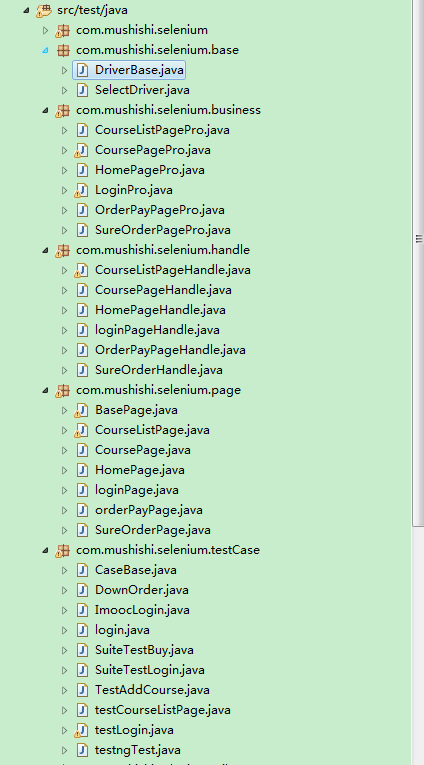
在page里面我们需要再次封装一个BasePage的类,这个是主要封装我们页面一些公用的方法,一些常用的方法我们只需要在这个类里面写一次就好,其他的page页面继承这个类。
来看我们base类里面的部分方法:
public class BasePage {
public DriverBase driver;
public BasePage(DriverBase driver){
this.driver = driver;
}
/**
* 定位Element
* @param By by
* */
public WebElement element(By by){
WebElement element = driver.findElement(by);
return element;
}
/**
* 层级定位,通过父节点定位到子节点
* 需要传入父节点和子节点的by
* */
public WebElement nodeElement(By by,By nodeby){
WebElement el = this.element(by);
return el.findElement(nodeby);
}
}
我们封装了一些常用的方法,然后我们的page页面都可以拿过去运用,这样减少了我们后期写这些方法的成本,下面来看我们loginpage。
在我们loginpage里面存放的全是登陆页面获取元素的方法,首先看我们我们的登陆页面:
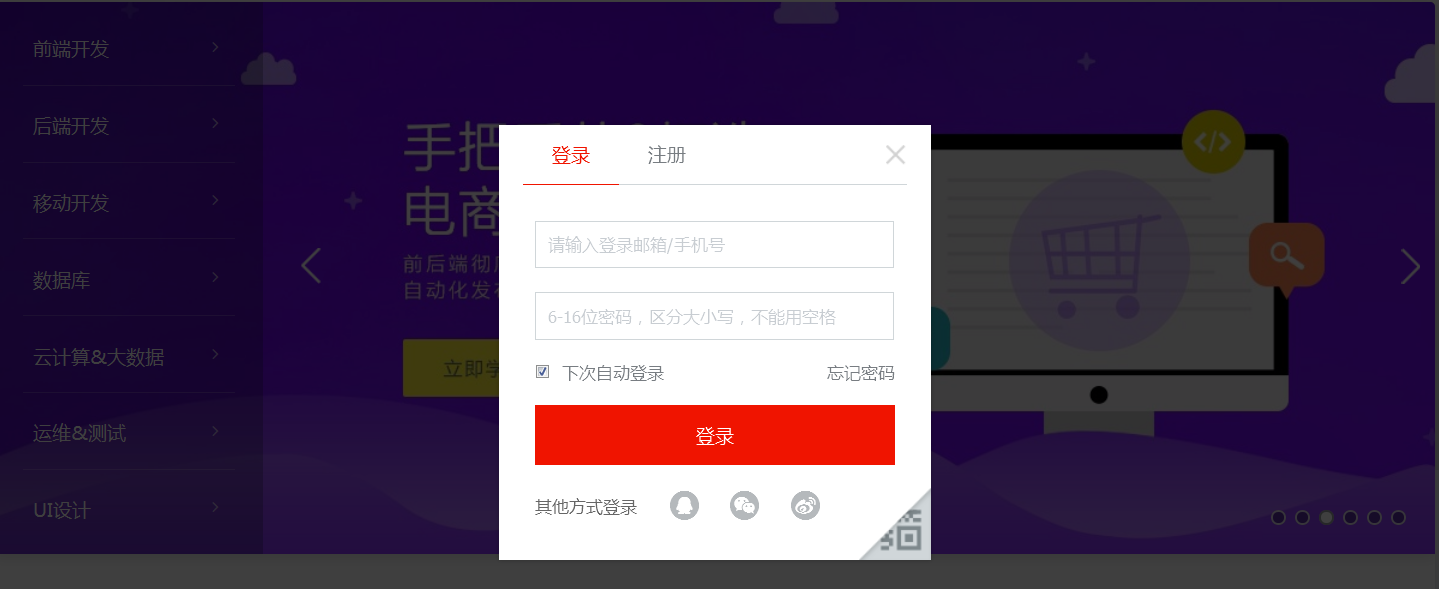
这个是我们的登陆页面,登陆页面中我们常用的就用户名、密码、记住登陆、登陆按钮几个元素,那么我们只需要把这几个元素都封装在我们的loginpage页面就好,看下面代码:
public class loginPage extends BasePage{
public loginPage(DriverBase driver){
super(driver);
}
/**
* 获取用户名输入框
* */
public WebElement getUserElement(){
return element(getByLocator.getLocator("username"));
}
/**
* 获取密码输入框Element
* */
public WebElement getPasswordElement(){
return element(getByLocator.getLocator("userpass"));
}
/**
* 获取登陆按钮element
* */
public WebElement getLoginButtonElement(){
return element(getByLocator.getLocator("loginbutton"));
}
}
在这里我们看不到任何的元素,我们所有的定位元素都进行了二次封装,在我们的BasePage里面有相应的封装,但是他也会去调用其他的一些定位类。当我们有了所有的元素之后我们是不是就需要再次对这些元素操作呢?接下来看我们的操作类:
public class loginPageHandle {
public DriverBase driver;
public loginPage lp;
public loginPageHandle(DriverBase driver){
this.driver = driver;
lp = new loginPage(driver);
}
/**
* 输入用户名
* */
public void sendKeysUser(String username){
lp.sendkeys(lp.getUserElement(), username);
}
/**
* 输入密码
* */
public void sendKeysPassword(String password){
lp.sendkeys(lp.getPasswordElement(), password);
}
/**
* 点击登陆
* */
public void clickLoginButton(){
lp.click(lp.getLoginButtonElement());
}
}
在我们的操作类里面所有的方法都是对单一的一个元素进行操作,这里并不是很全,并没有把所有元素都罗列进去,我们可以自行思考。在一些po模型中一些人是把这个放在了page里面,其实这个看个人,没有对错,只需要记住一个思想就行,我们的目的是把所有的元素、操作、数据都分离开就好。有操作后我们可以对业务或者一些人认为是case来看了:
public class LoginPro {
public loginPageHandle lph;
public DriverBase driver;
public LoginPro(DriverBase driver){
this.driver = driver;
lph = new loginPageHandle(driver);
}
public void login(String username,String password){
if(lph.assertLoginPage()){
lph.sendKeysUser(username);
lph.sendKeysPassword(password);
lph.clickLoginButton();
}else{
System.out.println("页面不存在或者状态不正确。");
}
}
}
在这个类如果放在case里面也是合适的,只是那样会有一点儿长,所以我单独拿出来了,我们可以看到我首先判断的是我处于的页面是否在我们的登陆页面,如果字我才会进行下面的操作。当完成这个之后我们就可以单独的写case了:
public class SuiteTestLogin extends CaseBase{
public DriverBase driver;
public LoginPro loginpro;
public HomePagePro homepagepro;
public ProUtil pro;
public HandleCookie handcookie;
@BeforeClass
public void beforeClass(){
this.driver = InitDriver("chrome");
pro = new ProUtil("loginTest.properties");
driver.driver.manage().timeouts().implicitlyWait(10, TimeUnit.SECONDS);
loginpro = new LoginPro(driver);
handcookie = new HandleCookie(driver);
homepagepro = new HomePagePro(driver);
driver.get(pro.getPro("url"));
}
@Test
public void testLogin(){
String username = pro.getPro("username");
String password = pro.getPro("passwd");
loginpro.login(username, password);
try {
Thread.sleep(5000);
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
if(homepagepro.AssertLogin(pro.getPro("yq"))){
System.out.println("登陆成功"+username);
handcookie.writeCookie();
}
}
@AfterClass
public void afterClass(){
driver.close();
}
在case里面我们有一些基础的方法来至于case的基类,我们再这case里面只做一件事情那就是打开页面然后登陆,最后退出。
当处于当前页面时我们可以运行,但是这个不是我们的目的,我们的目的是要整个自动化起来,所以我们需要在testng.xml里面去配置
<?xml version="1.0" encoding="UTF-8"?>
我们这个配置有一个监听事件,这个监听是为了当遇见错误时实现截图的。这个配置弄好后你可以右键该xml直接运行,最后你会得到一个一样而又不一样的结果。
testng.xml配置完毕后我们接着需要在我们的pom.xml中接着进行配置编译插件:
org.apache.maven.plugins
maven-compiler-plugin
2.3.2
1.7
1.7
org.apache.maven.plugins
maven-surefire-plugin
2.12
true
testNG.xml
我们需要把这两个插件加入,加入后我们就可以直接右键运行该xml,得到的结果也是一样,可以运行刚我们的整个case。最后一步集成jenkins
在打开的jenkins页面只需要选择新建,然后进入到了创建工程页面,在这个页面你需要选择创建一个maven工程:
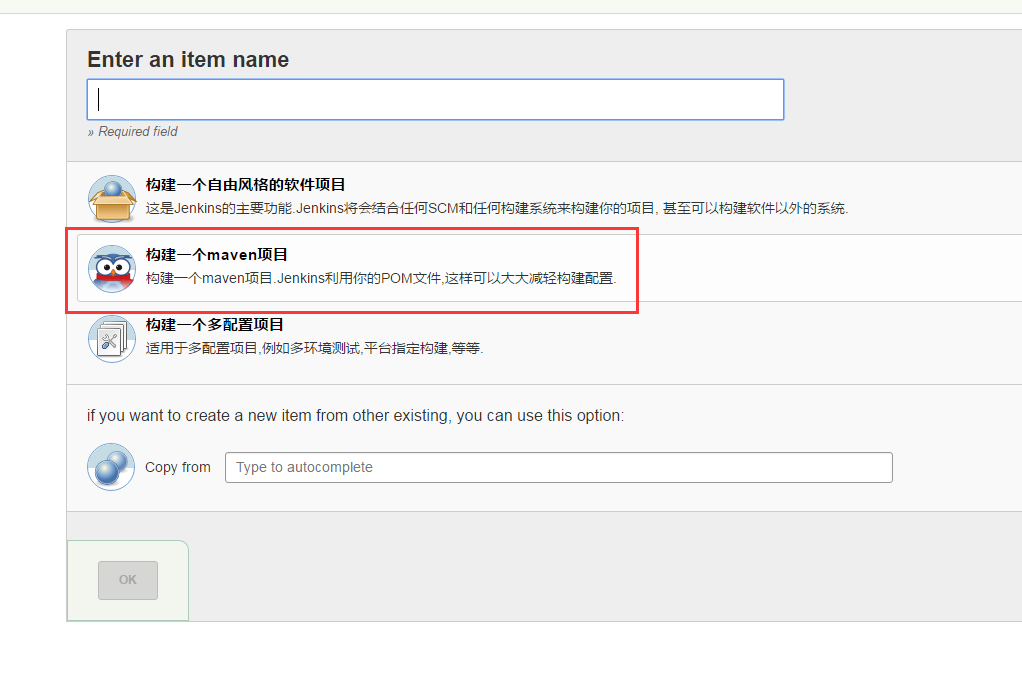
在创建完成后只需要在我们的build栏进行一个简单的配置,这里配置我们刚pom.xml文件的绝对路径:
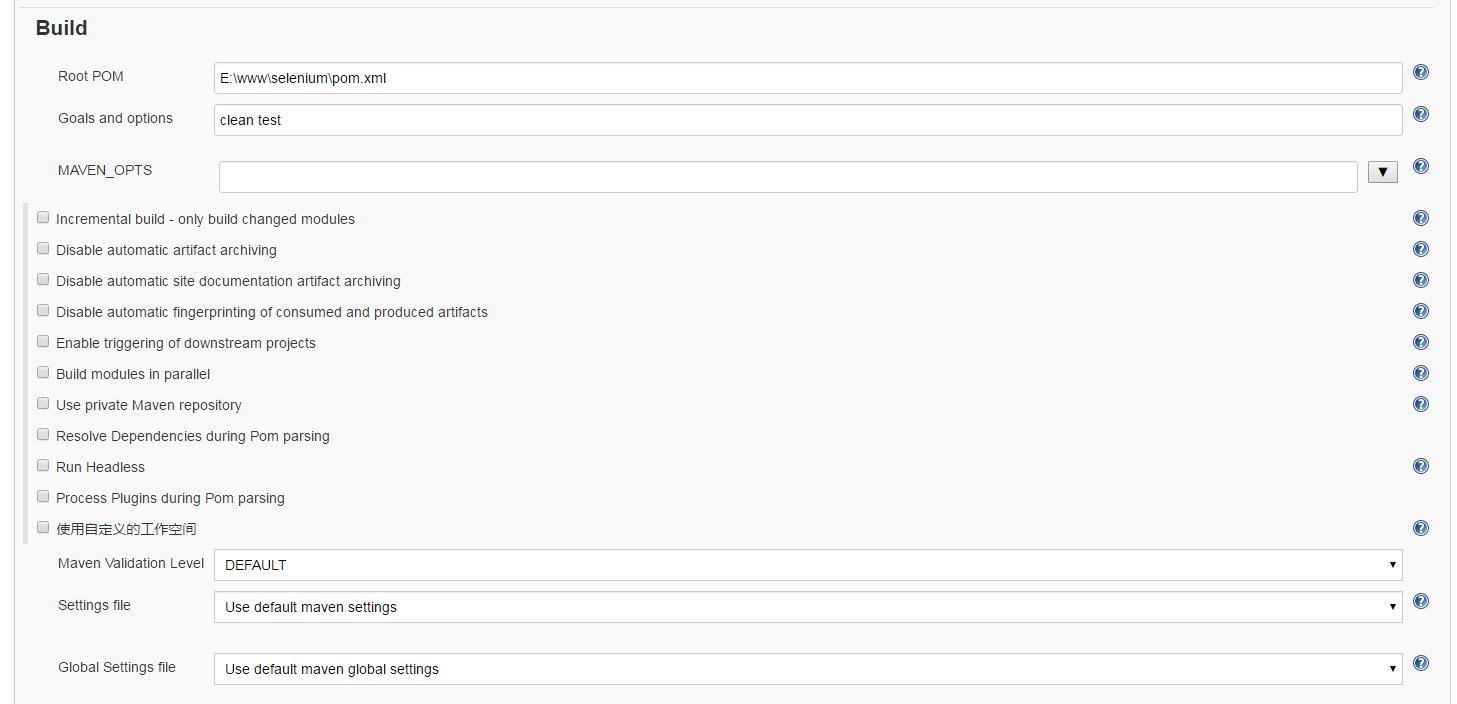
到目前为止你可以直接保存,然后去首页进行构建就可以了:
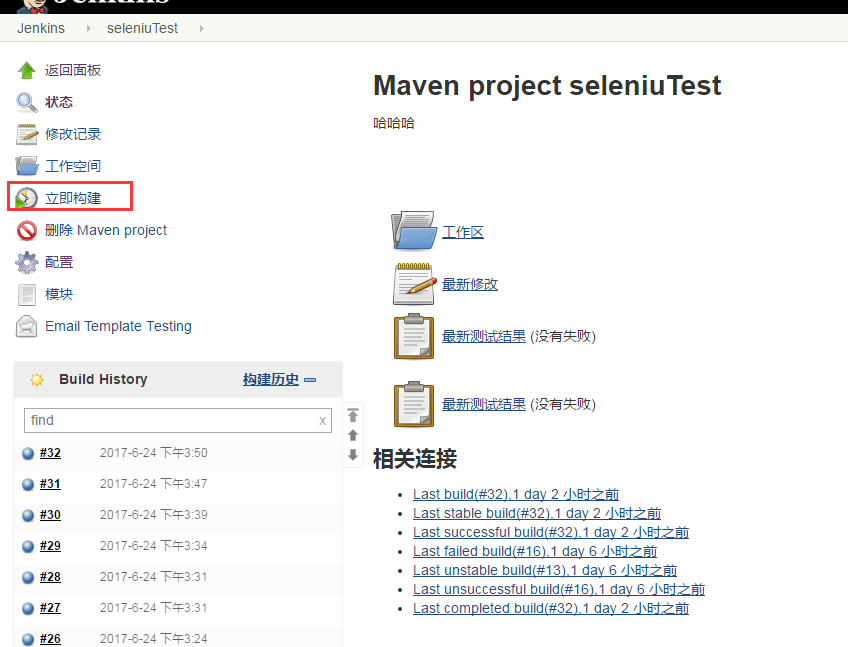
在jenkins这里我们还可以进行邮件的配置等等操作。哈哈,赶快去动手吧。
················
欢迎关注课程:
打开App,阅读手记















 513
513

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









