






摘要
人工智能模型正在成为现代计算系统不可或缺的一部分。就像软件不可避免地存在缺陷一样,模型也存在缺陷,从而导致分类/预测准确性差。与软件缺陷不同,模型缺陷无法简单地通过直接修改模型来修复。现有解决方案是投入额外的训练输入。但是,由于缺乏对模型不当行为的理解,因此它们的效果有限,从而无法选择适当的输入。受软件调试的启发,我们提出了一种新颖的模型调试技术,该技术首先进行模型状态差分分析以识别导致模型错误的内部特征,然后执行与回归测试中程序的输入选择相似的训练输入选择测试。我们对 6 种不同应用程序中的 29 种不同模型的评估结果表明,我们的技术可以有效且高效地修复模型错误,同时不会引入新的错误。对于简单的应用程序(例如数字识别),MODE 将测试平均准确率从 75%提高到 93%,而最新技术只能将训练时间提高到 85%,并且需要 11 倍的额外训练时间。对于复杂的应用程序和模型(例如,对象识别),MODE 可以在数分钟至数小时内将准确性从 75%提高到 91%以上,而最新技术无法修复错误,甚至会降低测试精度。
关键字:深度神经网络,调试,差分分析
介绍
人工智能(AI)尤其是机器学习(ML)已成为日常生活的重要组成部分。就像软件不可避免地包含错误,AI/ML 模型也可能会出现非预期行为,我们将其称为模型缺陷,因此模型调试将是智能软件工程的必要步骤。尽管模型常常无法达到 100%的准确度,但已有研究表明准确性存在上升空间。
模型缺陷可分为两类。一种是由次优模型结构引起的,例如 NN 模型中的隐藏层数,每层中的神经元数和神经元连接方式。我们称它们为结构性缺陷。另一种类型是由不当训练方式造成的(例如,使用偏斜训练集)。我们称它们为训练缺陷。我们的论文着重研究训练缺陷问题,并简称为模型缺陷。机器学习算法假定训练数据集和现实世界数据遵循相同或相似的分布,以便训练后的模型在现实中可用,但事实并非如此。因此许多提取的特征是有问题的(例如,对于某些输入而言太具体或没有足够的区分能力)。问题是,模型的可解释性是数据工程中一个众所周知的难题,提取的特征是如此抽象,以至于人类无法理解它们。因此不能通过直接修改模型中的各个权重参数值来实现模型缺陷修复,唯一的方法是提供更多的训练样本,以尽量减少训练数据的偏差。现有的生成式机器学习模型(例如生成式对抗网络(GAN)),该模型可以得到类似于现实世界情况的输入样本,但效果有限。
受软件调试方法成功的启发,我们提出了一种用于神经网络模型的新型模型调试技术。神经网络模型可以看作是由矩阵连接的内部状态变量(称为神经元)层。在训练中获得的知识被编码在矩阵的参数值中。在应用过程中,给定输入,一系列矩阵乘法运算以及一些特殊设计的阈值函数将输入分类为输出标签之一。给定模型缺陷(如特定输出标签的分类准确性不佳),我们的技术将执行状态差分分析,以识别造成错误分类的神经元。然后使用与回归测试中的输入选择类似的输入选择算法,来选择可能对故障神经元产生重大影响的新输入样本以进行重新训练。特别地,我们的技术首先通过测量由该层表示的抽象是否会对分类准确性产生实质性影响,来识别对于修复模型错误至关重要的隐藏层。一旦确定了该层,我们的技术就可以进一步测量该层中各个神经元/特征对于有缺陷的输出标签的正确和错误分类结果的重要性。然后,我们选择针对性输入来修复缺陷。针对不同缺陷,我们开发了各种差异分析和输入选择策略。
我们的论文做出了以下贡献:
我们发现由于缺乏对模型错误的根本原因的了解或分析,现有的模型调试过程无效。
受状态差异分析和软件调试/回归测试中输入选择的启发,我们提出了一种新技术来评估特征对分类结果的重要性,定位故障神经元并选择用于修复模型缺陷的高质量训练样本。
我们基于上述想法开发了 MODE 原型,并在 29 种不同模型上进行了评估。结果表明,MODE 可以有效,高效地修复所有模型缺陷,且没有引入新的缺陷,平均准确率从 75%提高到 93%,而现有方法仅在某些情况下有效,可能会降低模型性能,并且需要 11 倍的处理时间。
背景与动机
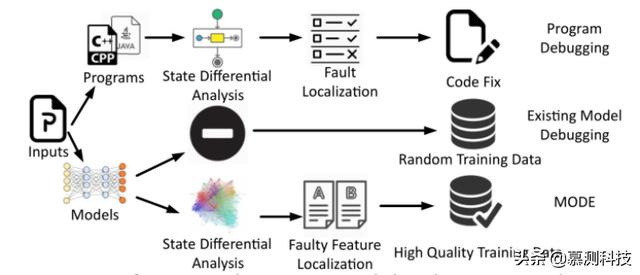
图 1 软件调试,模型调试和 MODE
软件调试 如图 1 所示,典型的软件调试过程如下。开发人员在失败输入下执行程序,检查执行状态并与理想状态进行比较,我们称其为状态差异分析阶段。图 3 还显示了现有模型调试的过程和我们的想法。现有模型调试依赖于输入越来越多的训练数据,希望以此纠正不良行为。而我们的方法与其不同。

图 2 热图
我们的想法。受软件调试的启发,我们提出了一种新颖的神经网络模型调试技术,其工作原理如下。如图 2 所示,给定与具有错误行为的输出标签相关的输入(例如,错误编号为 5 的数字 5),执行模型状态差分分析以识别对于不良行为至关重要的特征,并采用热图对重要性进行标识。其中红色表示相对重要,蓝色表示相对不重要。为了便于进行差异分析,我们为某一输出标签l生成了两个热图。一个被称为良性热图,根据正确分类的所有输入计算得出,另一种称为故障热图,由被错误分类的所有输入计算得出。对于特定缺陷,例如标签l的识别效果差,利用差异分析对故障神经元定位。例如,图 2(a)和图 2(b)分别显示了标签l的良性热图和故障热图。观察到良性热图的红色区域大致显示了数字的总体形状,而蓝色区域是不属于数字的区域。如图 2(c)所示,我们记录存在于有缺陷的热图中而不存在于良性热图中的神经元,称为差分热图。直观上,在此差异热图中突出显示的红色是导致错误分类的神经元。确定问题来源后,我们使用 GAN 生成新的输入,或基于差分热图从其余未使用的训练输入中选择输入。图 2(e)显示了具有较高优先级并且更可能被选择进行进一步训练的图像,而图 2(f)显示了具有较低优先级并且不太可能被选择的图像,后者具有我们的差异分析所识别的故障特征。
设计
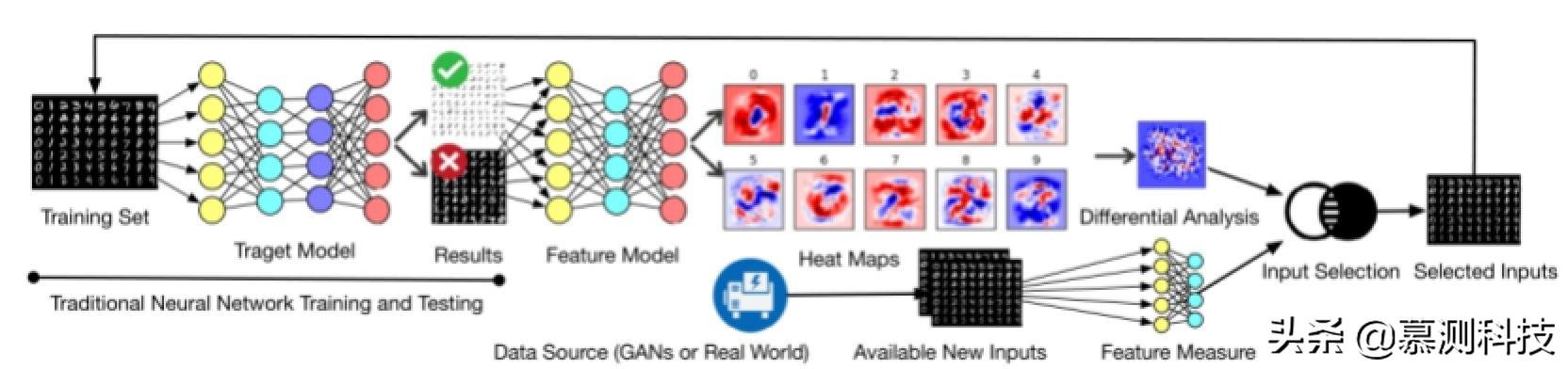
图 3 MODE 示意图
图 3 给出了 MODE 的概述。给定一个缺陷模型,即它对标签有过度拟合或不足的问题,MODE 首先使用标签的分类结果执行模型状态差异分析,并生成良性和故障热图。由于 NN 具有许多隐藏层,这些隐藏层表示特征选择中的各种抽象级别,因此我们需要选择一个对修复缺陷影响最大的层。选择太原始或太抽象的图层可能会导致次优结果,为此我们开发了一种算法来基于错误类型进行选择。根据所选层生成的良热和故障热图,MODE 执行多种差异分析(根据错误类型)以生成差异热图,从而突出了要重新训练的目标特征。差分热图用作选择现有或新输入(由 GAN 生成或从现实世界收集的)的指南,以形成新的训练数据集,然后将其用于重新训练模型并修复错误
MODE 将缺陷分为两类,如果训练集和测试集上准确率均低于预设值(根据实际任务和模型结构决定),称为欠拟合缺陷。如果训练集上的准确率远高于测试集上的准确率,称为过拟合缺陷。
模型状态差异分析首先进行目标层选择,MODE 优先选择临近饱和点的层,分析准确性转折位置的特殊性。对于欠拟合的 bug,MODE 使用从输入层到输出层的方向执行正向分析,而对于过拟合的 bug,MODE 使用从输出层到输入层的方向进行向后分析。然后 MODE 对目标层中不同神经元对决策结果的影响程度进行评估,利用重新训练的特征模型,将从待测神经元到输出层的矩阵权重绝对值作为依据。影响程度结果最终被反映为热图。
接着 MODE 对热图进行差异对比,并对正确归类和错误归类的两种情况(将类l误判为其他类或将其他类误判为l)进行分析,得到三种差分热图。
最后采用差分热图进行输入选择。对于每个新输入首先利用特征模型获取特征值向量,然后结合差分热图得到差异得分。MODE 根据差异得分进行输入选择,同时为了避免过拟合,选择的输入集中将会被额外添加随机样本。
结论
受软件调试和回归测试技术的启发,我们提出并开发了 MODE,这是一种基于状态差分分析和输入选择的自动神经网络调试技术。它可以帮助识别缺陷神经元并衡量其重要性,以指导新的输入样本选择。 MODE 可以构建高质量的训练数据集,这些数据集可以有效地修复模型缺陷,而不会引入新的缺陷。
致谢
本文由南京大学软件学院 2019 级硕士曹可凡翻译转述。















 4194
4194











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









