






在本系列的最后一篇文章中,我们讨论了多元线性回归模型。费尔南多创建了一个模型,根据五个输入参数估算汽车价格。
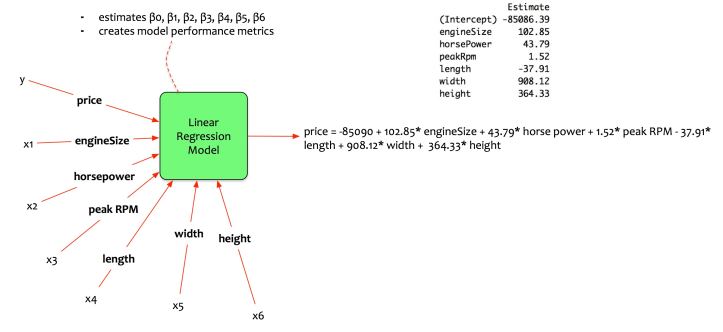
费尔南多的确获得了一个比较好的模型,然而,费尔南多想要获得最好的输入变量集
本文将详细介绍模型选择方法
一、概念
模型选择方法的想法很直观。它回答了以下问题:
如何为最佳模型选择正确的输入变量?
如何定义最佳模型?
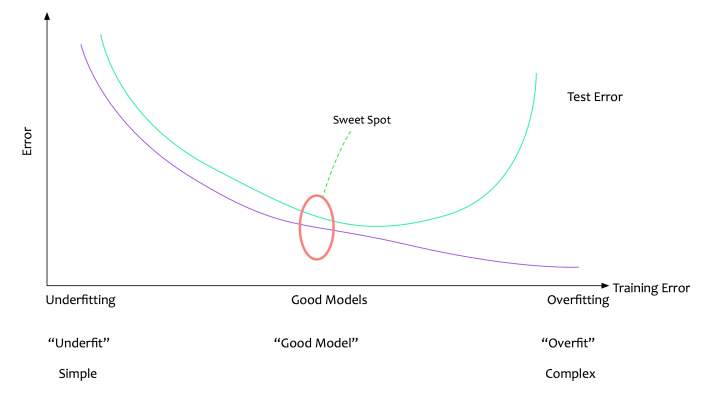
最优模型是使数据与评估指标的最佳值相匹配的模型。
可以有很多评估指标。调整后的r平方是多元线性回归模型的选择评估指标。
有三种方法可以选择最佳变量集。他们是:
- Best Subset
- Forward Stepwise
- Backward Stepwise
1、Best Subset
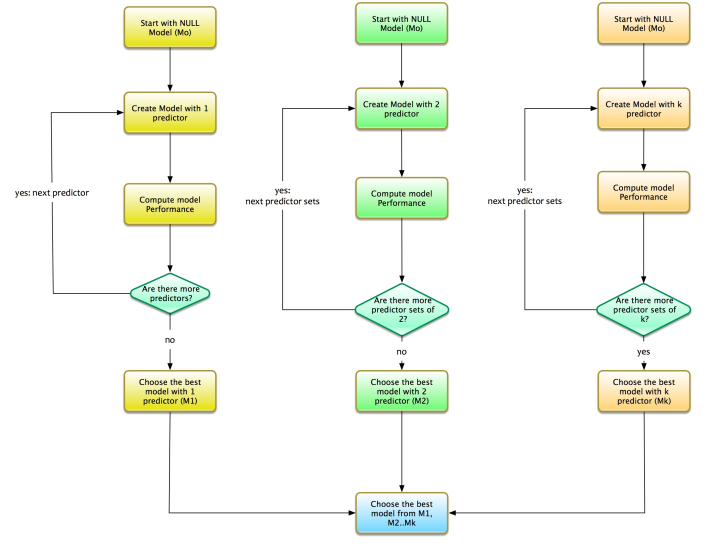
让我们说我们有k个变量。最佳子集方法的过程如下:
- 从NULL模型开始,即没有预测变量的模型。我们称这个模型为M0。
- 找到1个变量的最优模型。这意味着该模型是一个简单的回归量,只有一个自变量。我们称这个模型为M1。
- 找到包含2个变量的最优模型。这意味着该模型是一个只有两个独立变量的回归量。我们称这个模型为M2。
- 找到包含3个变量的最优模型。这意味着该模型是一个只有三个独立变量的回归量。我们称这个模型为M3。
- 等等...我们得到了演练。重复这个过程。测试最佳模型的所有预测变量组合。
对于k变量,我们需要从以下模型集中选择最佳模型:
- M1:具有1个预测变量的最优模型。
- M2:具有2个预测变量的最优模型。
- M3:具有3个预测变量的最佳模型。
- Mk:具有k个预测变量的最优模型。
选择M1 ... Mk中的最佳模型,即最适合的模型
最好的子集是一个精心设计的过程。它梳理了整个预测变量列表。它选择了最好的组合。但是,它有自己的挑战。
最佳子集为每个预测变量及其组合创建模型。这意味着我们正在为每个变量组合创建模型。模型的数量可以是非常大的数量。
如果有2个变量,则有4种可能的模型。如果有3个变量,则有8种可能的模型。一般来说,如果有p个变量,则有2 ^ p个可能的模型。这是很多可供选择的型号。想象一下,有100个变量(很常见)。想象一下,有100个变量(很常见)。将有2 ^ 100个可能的模型。令人难以置信的数字。
在费尔南多的情况下,只有5个变量,他将不得不创建和选择2 ^ 5个模型,即32个不同的模型。
2、逐步向前法
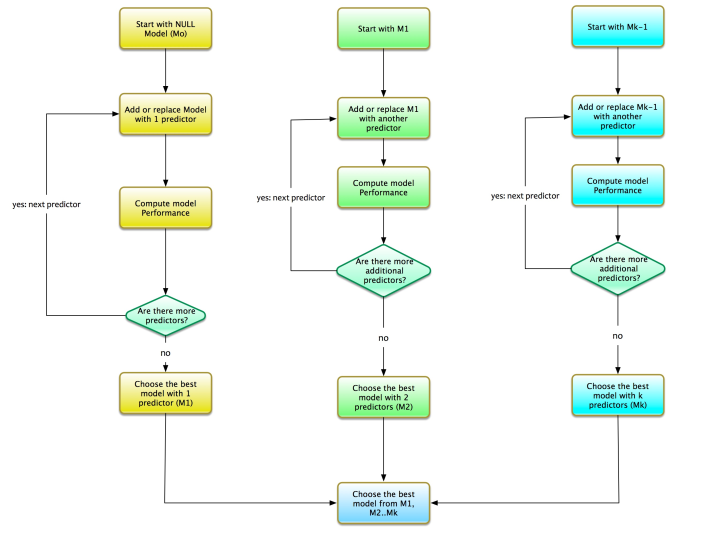
尽管最佳子集是详尽的,但它需要大量的计算能力。这可能非常耗时。逐步向前试图缓解这种痛苦。
让我们说我们有k个变量。前进逐步的过程如下:
- 从NULL模型开始,即没有预测变量的模型。我们称之为M0。将预测变量添加到模型中。一次一个。
- 找到1个变量的最优模型。这意味着该模型是一个简单的回归量,只有一个自变量。我们将此模型称为M1。
- 再向M1添加一个变量。找到包含2个变量的最优模型。请注意,附加变量已添加到M1。我们将此模型称为M2。
- 再向M2添加一个变量。找到包含3个变量的最优模型。请注意,附加变量已添加到M2。我们将此模型称为M3。
- 等等......我们得到了演练。重复此过程直到Mk即只有k变量的模型。
对于k变量,我们需要从以下模型集中选择最佳模型:
- M1:具有1个预测变量的最优模型。
- M2:具有2个预测变量的最优模型。这个模型是M1 +一个额外的变量。
- M3:具有3个预测变量的最佳模型。这个模型是M2 +一个额外的变量。
- Mk:具有k个预测变量的最优模型。这个模型是Mk-1 +一个额外的变量。
再次,选择M1 ... Mk中的最佳模型,即具有最佳拟合的模型
与最佳子集方法相比,前向逐步选择创建的模型更少。如果有p个变量,则会有大约p(p + 1)/ 2 + 1个模型可供选择。远低于最佳子集方法的模型选择。想象一下,有100个变量; 基于前向逐步方法创建的模型数量为100 * 101/2 + 1即5051模型。
在费尔南多的情况下,只有5个变量,他将不得不创建和选择5 * 6/2 + 1模型,即16种不同的模型。
3、逐步向后
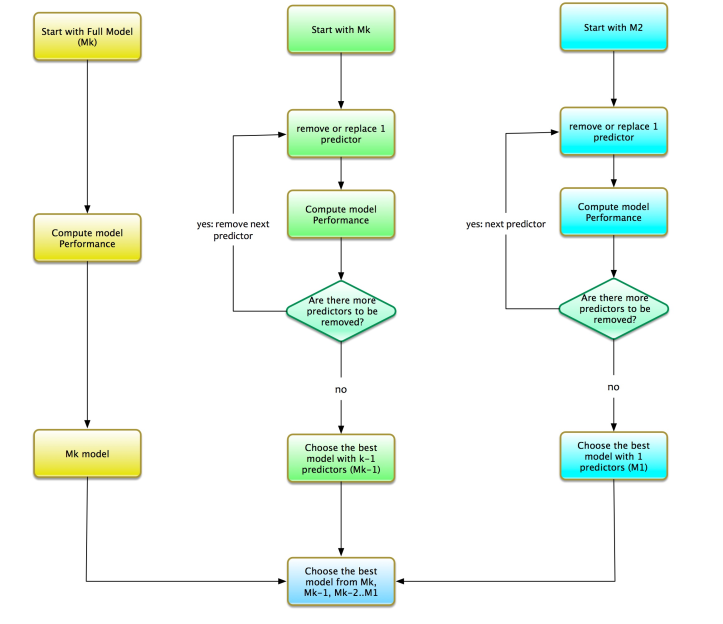
现在我们已经理解了模型选择的前向逐步过程。让我们讨论后向逐步过程。它与前向逐步过程相反。前进逐步从没有变量的模型开始,即NULL模型。在对比度上,向后逐步从所有变量开始。向后逐步的过程如下:
- 让我们说有k个预测因子。从完整模型开始,即包含所有预测变量的模型。我们称这个模型为Mk。从完整模型中删除预测变量。一次一个。
- 找到k-1变量的最优模型。从Mk中删除一个变量。为所有可能的组合计算模型的性能。选择具有k-1变量的最佳模型。我们将此模型称为Mk-1。
- 找到k-2变量的最优模型。从Mk-1中删除一个变量。为所有可能的组合计算模型的性能。选择具有k-2变量的最佳模型。我们称这个模型为Mk-2。
- 等等......我们得到了演练。重复此过程,直到M1即只有1个变量的模型。
对于k变量,我们需要从以下模型集中选择最佳模型:
- Mk:具有k个预测变量的最优模型。
- Mk-1:具有k-1个预测因子的最优模型。这个模型是Mk - 一个额外的变量。
- Mk-2:具有k-2个预测变量的最优模型。这个模型是Mk - 另外两个变量。
- M1:具有1个预测变量的最优模型。
二、Model Building
既然模型选择的概念很明确,那么让我们回到费尔南多。回想一下本系列的前一篇文章。费尔南多有六个变量发动机尺寸,马力,峰值转速,长度,宽度和高度。他希望通过创建多元回归模型来估算汽车价格。他想保持平衡并选择最佳模特。
他选择应用前向逐步模型选择方法。统计包计算所有可能的模型并输出M1到M6。
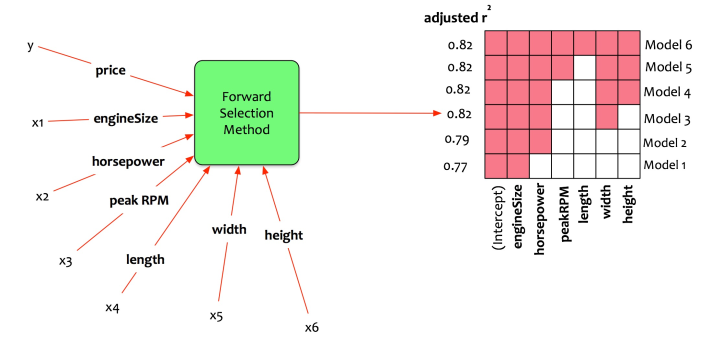
让我们解释输出。
- 模型1:它应该只有一个预测器。最佳拟合模型仅使用引擎大小作为预测器。调整后的R平方为0.77。
- 模型2:它应该只有两个预测变量。最佳拟合模型仅使用发动机尺寸和马力作为预测器。调整后的R平方为0.79。
- 模型3:它应该只有三个预测变量。最佳拟合模型仅使用发动机尺寸,马力和宽度作为预测器。调整后的R平方为0.82。
- 模型4:它应该只有四个预测变量。最佳拟合模型仅使用发动机尺寸,马力,宽度和高度作为预测器。调整后的R平方为0.82。
- 模型5:它应该只有五个预测变量。最佳拟合模型仅使用发动机尺寸,马力,峰值转速,宽度和高度作为预测器。调整后的R平方为0.82。
- 模型6:它应该只有六个预测变量。最佳拟合模型仅使用所有六个预测变量。调整后的R平方为0.82。
回想一下关于创建最简单但有效的模型的讨论。
“所有型号都应尽可能简单,但不能简单。”
费尔南多选择了最简单的模型,以提供最佳性能。在这种情况下,它是模型3.该模型使用发动机尺寸,马力和宽度作为预测器。该模型能够得到调整后的0.82的R平方,即模型可以解释82%的训练数据变化。
统计包提供以下系数。
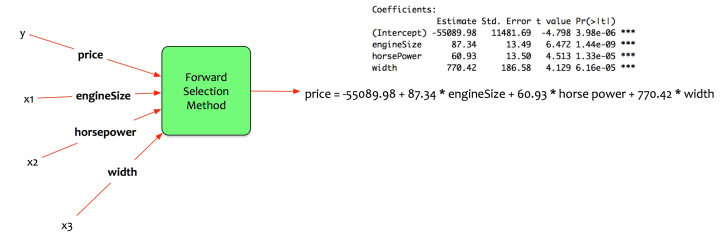
根据发动机尺寸,马力和宽度估算价格。
价格= -55089.98 + 87.34 engineSize + 60.93 马力+ 770.42 宽度
模型评估
费尔南多选择了最好的模特。该模型将使用发动机尺寸,马力和汽车宽度估算价格。他希望在训练和测试数据上评估模型的性能。
回想一下,他已将数据分成训练和测试集。费尔南多使用训练数据训练模型。测试数据是看不见的数据。Fernando评估模型在测试数据上的性能。这才是真正的考验。
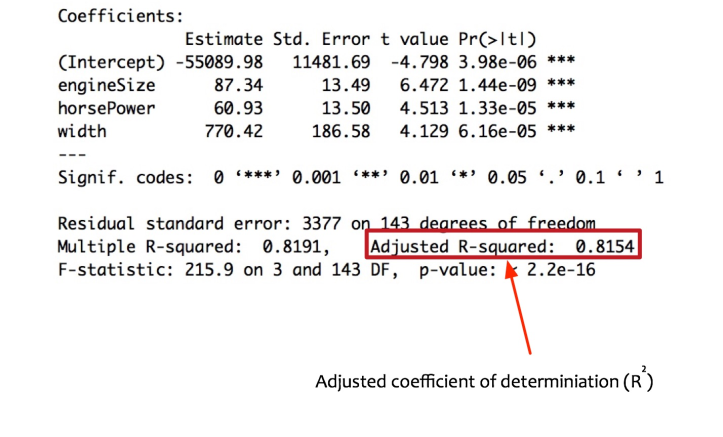
在训练数据上,该模型表现良好。调整后的R平方为0.815 =>模型可以解释训练数据的81%变化。但是,为了使模型可以接受,它还需要在测试数据上表现良好。
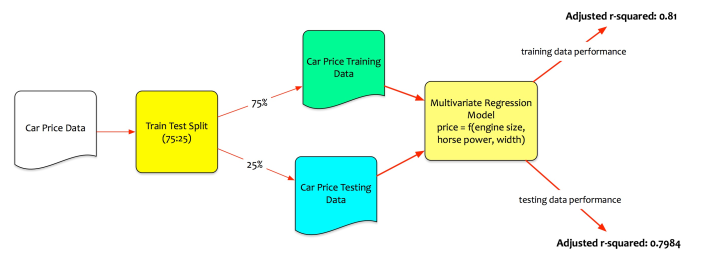
Fernando在测试数据集上测试模型性能。该模型计算出测试数据的调整后的R平方为0.7984。这意味着即使在看不见的数据上,模型也可以解释79.84%的变化。
结论
费尔南多现在有一个简单而有效的模型来预测汽车价格。但是,发动机尺寸,马力和宽度的单位是不同的。他考虑着。
- 如何使用通用的比较单位估算价格变化?
- 发动机尺寸,马力和宽度的价格有多大?
该系列的下一篇文章即将发布。它将讨论将多元回归模型转换为计算弹性的方法。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









