





一、分析背景:
1,为什么要选择虎嗅
「关于虎嗅」虎嗅网创办于 2012 年 5 月,是一个聚合优质创新信息与人群的新媒体平台。
2,分析内容
分析虎嗅网 5 万篇文章的基本情况,包括收藏数、评论数等;
发掘最受欢迎和最不受欢迎的文章及作者;
分析文章标题形式(长度、句式)与受欢迎程度之间的关系;
展现近些年科技互联网行业的热门词汇
3,分析工具:
python3.6
scrapy
MongoDB
Matplotlib
WordCloud
Jieba
数据抓取
使用scrapy抓取了虎嗅网的主页文章,文章抓取时间为2012年建站至2018年12月7日共计约5 万篇文章。抓取 了 8 个字段信息:文章标题、作者、发文时间、评论数、收藏数、摘要,文章链接和文章内容。
1.目标网站分析
这是要爬取的 网页界面,可以看到是通过 AJAX 加载的。
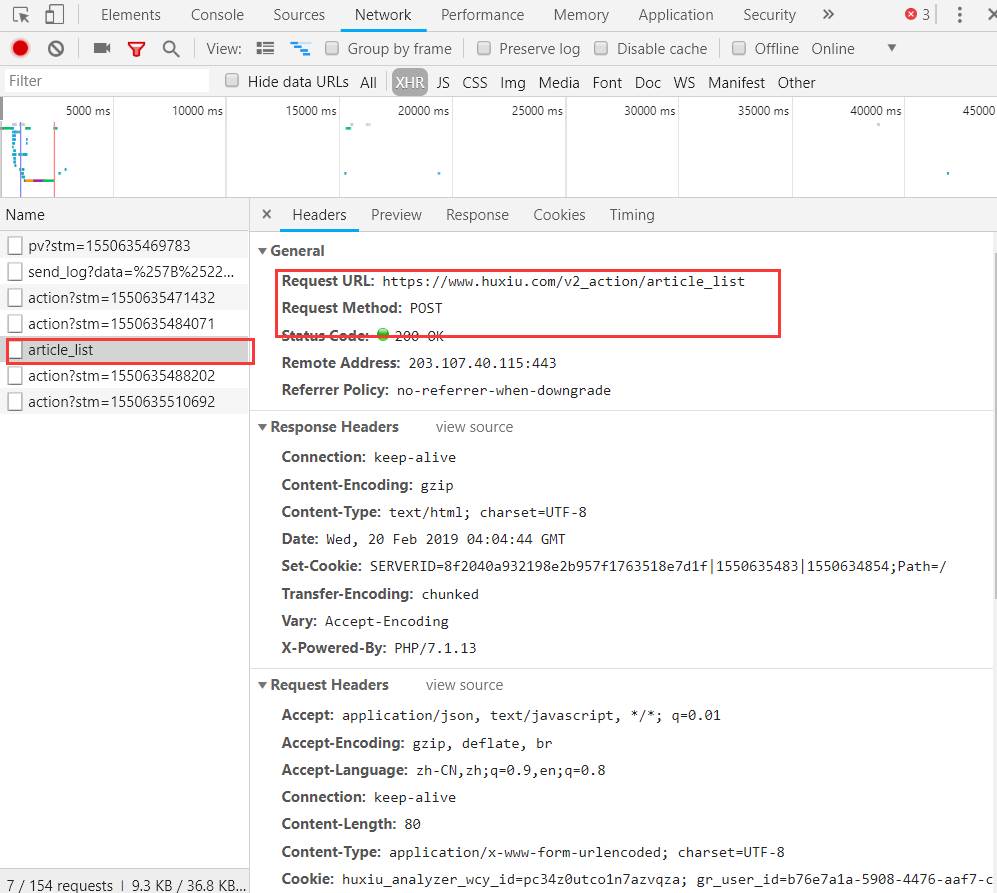
F12打开开发者工具,可以看到 URL 请求是 POST 类型,下拉到底部查看 Form Data,表单需提交参数只有 3 项。经尝试, 只提交 page 参数就能成功获取页面的信息,其他两项参数无关紧要,所以构造分页爬取非常简单。
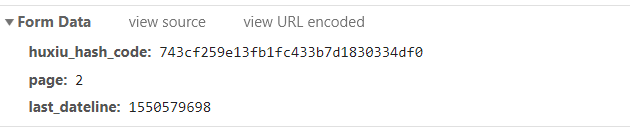
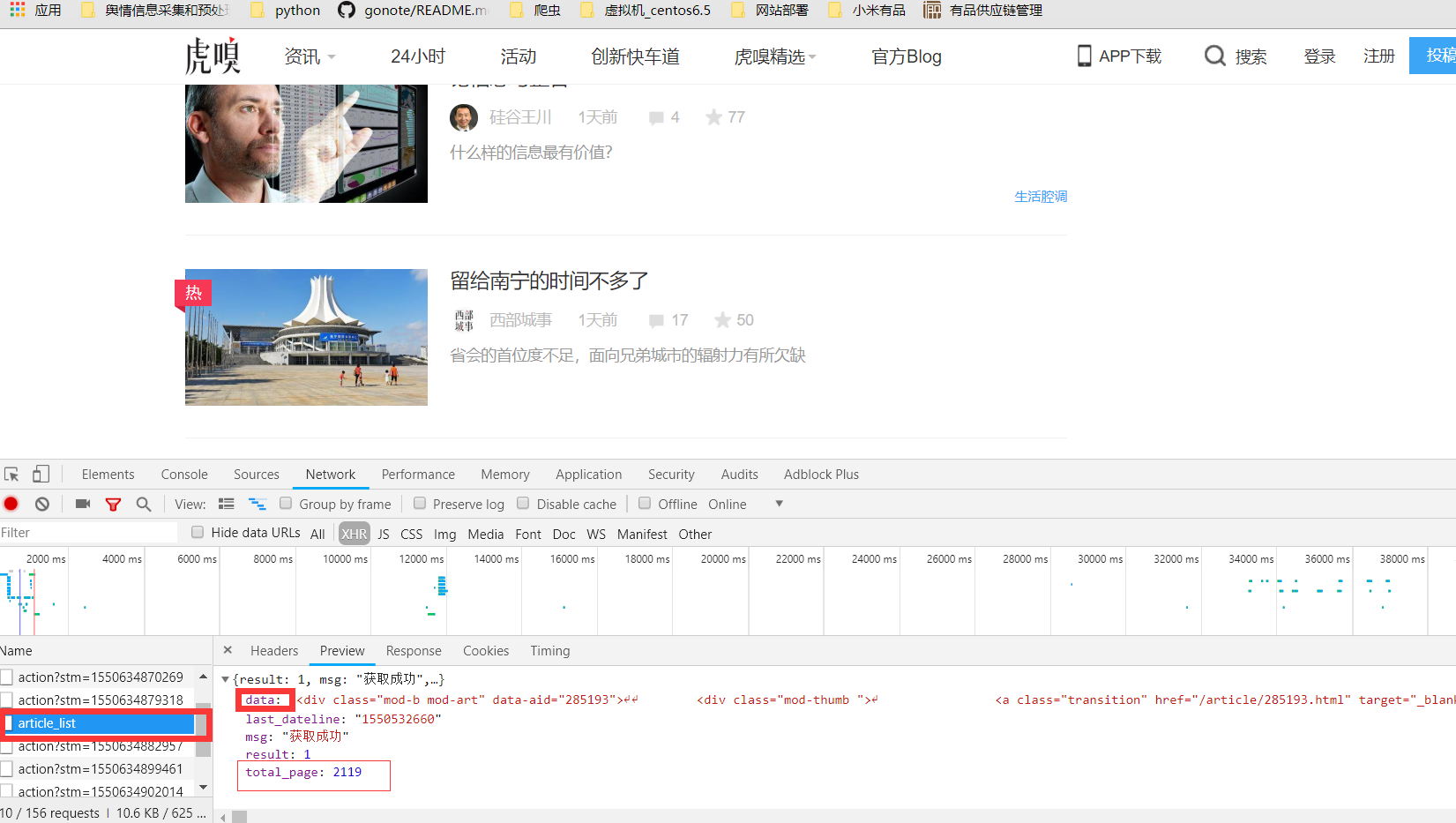
接着,切换选项卡到 Preview 和 Response 查看网页内容,可以看到数据都位于 data 字段里。total_page 为 2119,表示一共有 2119 页的文章内容,每一页有 25 篇文章,总共约 5 万篇,也就是我们要爬取的数量。
Scrapy介绍
Scrapy 是用纯 Python 实现一个为了爬取网站数据、提取结构性数据而编写的应用框架,用途非常广泛。框架的力量,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各种图片,非常之方便。Scrapy 使用了 Twisted['twɪstɪd](其主要对手是 Tornado)异步网络框架来处理网络通讯,可以加快我们的下载速度,不用自己去实现异步框架,并且包含了各种中间件接口,可以灵活的完成各种需求。
scrapy是如何帮助我们抓取数据的呢?
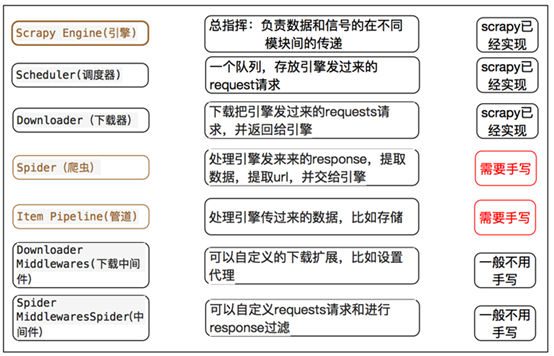
scrapy框架的工作流程:

1.首先Spiders(爬虫)将需要发送请求的url(requests)经ScrapyEngine(引擎)交给Scheduler(调度器)。
2.Scheduler(排序,入队)处理后,经ScrapyEngine,DownloaderMiddlewares(可选,主要有User_Agent, Proxy代理)交给Downloader。
3.Downloader向互联网发送请求,并接收下载响应(response)。将响应(response)经ScrapyEngine,SpiderMiddlewares(可选)交给Spiders。
4.Spiders处理response,提取数据并将数据经ScrapyEngine交给ItemPipeline保存(可以是本地,可以是数据库)。
5. 提取url重新经ScrapyEngine交给Scheduler进行下一个循环。直到无Url请求程序停止结束。
实现代码
创建项目
scrapy startproject 项目名
scrapy genspider 爬虫名 网址


这里,首先定义了一个 HuxiuV1Spider 主类,整个爬虫项目都主要在该类下完成。 接着,可以将爬虫基本的一些基本配置,比如:Headers、代理等设置写在下面的 headers 属性中。
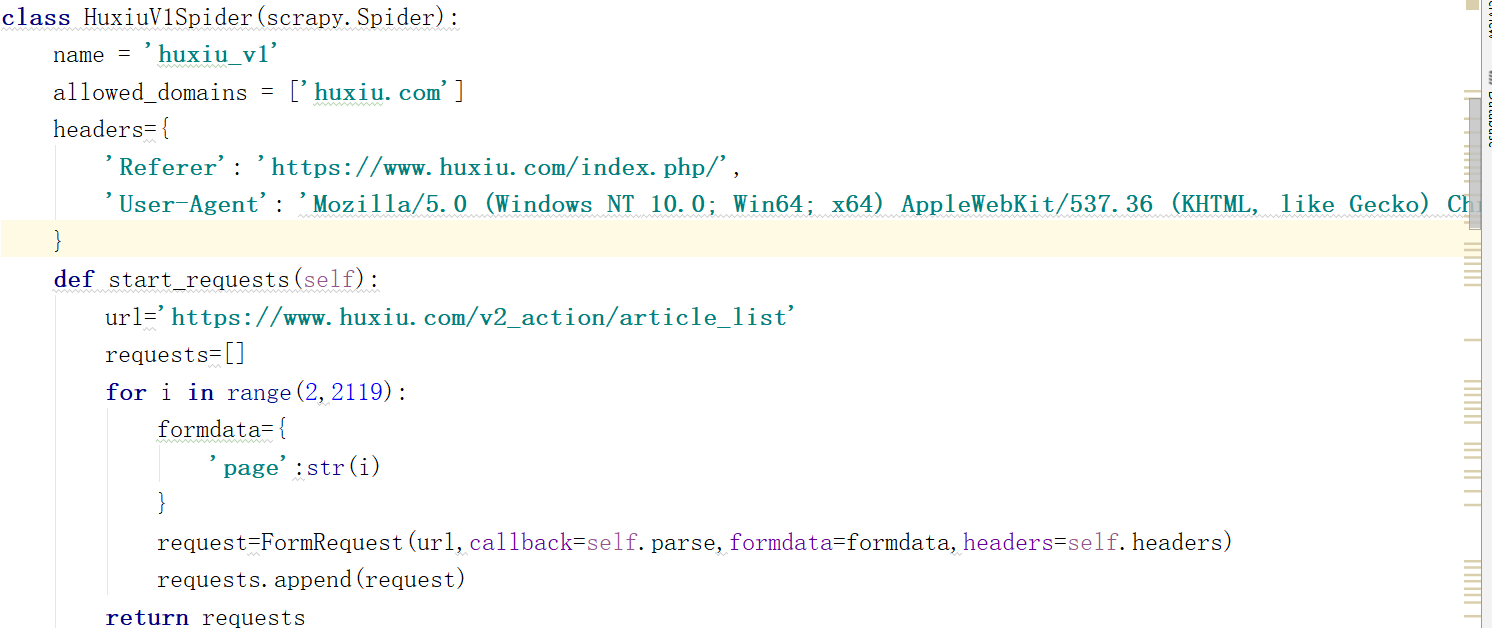
由于 URL 是 POST 请求,所以我们还需要使用formdata={'page':str(i)}来将FormData中的表单参数添加进去,这里我们需要设置为 POST;formdata 是 POST 请求表单参数,只需要添加一个 page 参数即可。接着,通过 callback 参数定义一个 parse() 方法,用来解析 URL 成功后返回的 Response 响应。在后面的 parse() 方法中,可以使用 re,xpath提取响应中的所需内容。


这里我们利用正则表达式提取出文章标题,链接,作者等所需信息,这里将数据保存为list数据,便于后续存储到mongo数据库中。
成功得到所需数据,然后就可以保存了,可以选择输出为csv,MySQL,mongoDB,这里我们选择mongoDB数据库

创建数据库文件的存放位置
因为启动 mongodb 服务之前需要必须创建数据库文件的存放文件夹,否则命令不会自 动创建,而且不能启动成功。
1. 在文件夹下,新建data文件夹,在data文件下新建db文件夹
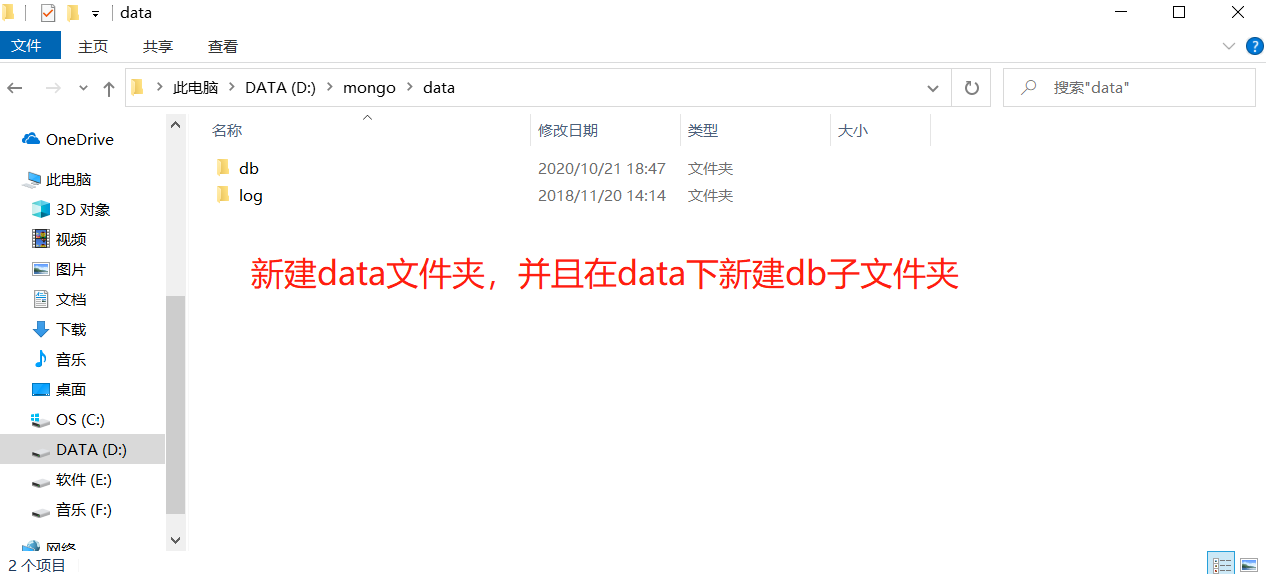
2.指定db 目录并启动
在命令行窗口中,首先来了 bin 路径,然后输入命令: mongod--dbpathD:\mongo\data\db



1 #-*- coding: utf-8 -*-
2 #from scrapy.spider import CrawlSpider
3 from selenium importwebdriver4 importtime5 from scrapy.linkextractors importLinkExtractor6 from scrapy.spiders importCrawlSpider, Rule7 #import json
8 from datetime importdatetime9 from ..items importHuxiuItem10 from scrapy.http importFormRequest11 importscrapy12 importjson,re13 classHuxiuV1Spider(scrapy.Spider):14 name = 'huxiu_v1'
15 allowed_domains = ['huxiu.com']16 headers={17 'Referer': 'https://www.huxiu.com/index.php/',18 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36'
19 }20 #post
21 #Form data
22 #page: 2
23 defstart_requests(self):24 url='https://www.huxiu.com/v2_action/article_list'
25 requests=[]26 for i in range(2,2119):27 formdata={28 'page':str(i)29 }30 request=FormRequest(url,callback=self.parse,formdata=formdata,headers=self.headers)31 requests.append(request)32 returnrequests33 defparse(self, response):34 js=json.loads(response.body.decode())35 #print(js)
36 req =str(js)37 idd = re.findall(r'data-aid="(.*?)">', req)#未处理的url(id)
38 title = re.findall(r'class="transition msubstr-row2" target="_blank">(.*?)', req)#标题
39 auth = re.findall(r'class="author-name">(.*?)', req)#作者
40 pinglun = re.findall(r'(.*?)', req)#评论
41 shoucang = re.findall(r'(.*?)', req)#收藏
42 zhaiyao = re.findall(r'
43 digect = []#摘要
44 for i inzhaiyao:45 s = i[34:-12]46 if 'span' ini:47 s = i[104:-12]48 digect.append(s)49 #print(digect)
50 #print(title)
51 detail_url=[]52 for i inidd:53 burl = 'https://www.huxiu.com/article/{}.html'.format(i)54 detail_url.append(burl)55 #print(detail_url)
56 for i inrange(len(idd)):57 item=HuxiuItem()58 item['title']=title[i]59 item["auth"]=auth[i]60 item['detail_url']=detail_url[i]61 item['pinglun']=pinglun[i]62 item['shoucang']=shoucang[i]63 item['zhaiyao']=digect[i]64 print(detail_url[i])65 #yield item
66 yield scrapy.Request(url=detail_url[i],meta={'meta1':item},callback=self.pasre_item)67 defpasre_item(self,response):68 meta1=response.meta['meta1']69 #print('hello')
70 time=response.xpath('//span[@class="article-time pull-left"]/text()|//span[@class="article-time"]/text()').extract()71 content=response.xpath('//div[@class="article-content-wrap"]/p/text()|//div[@class="article-content-wrap"]/div/text()|//div[@class="article-content-wrap"]/div/span/text()').extract()72 print(time)73 ssss=''
74 for i incontent:75 ssss+=i76 #num = response.xpath('//div[@class="author-article-pl"]/ul/li/a/text()')
77 #wnums=''
78 #for i in num:
79 #wnums = i[:-3]
80 #print(wnums)
81 for i inrange(len(time)):82 item =HuxiuItem()83 item['title']=meta1['title']84 item['auth']=meta1['auth']85 item['detail_url']=meta1['detail_url']86 item['pinglun']=meta1['pinglun']87 item['shoucang']=meta1['shoucang']88 item['zhaiyao']=meta1['zhaiyao']89 item['time']=time[i]90 #item['wnums']=num
91 item['content']=ssss92
93 yield item
spider
1 #-*- coding: utf-8 -*-
2
3 #Define here the models for your scraped items
4 #5 #See documentation in:
6 #https://doc.scrapy.org/en/latest/topics/items.html
7
8 importscrapy9
10
11 classHuxiuItem(scrapy.Item):12 #define the fields for your item here like:
13 #name = scrapy.Field()
14 title =scrapy.Field()15 auth =scrapy.Field()16 detail_url =scrapy.Field()17 pinglun =scrapy.Field()18 shoucang =scrapy.Field()19 zhaiyao =scrapy.Field()20 time =scrapy.Field()21 content=scrapy.Field()22 #wnums=scrapy.Field()
item
1 importpymongo2
3 classHuVPipeline(object):4 def __init__(self):5 self.client=pymongo.MongoClient()#链接Mongodb数据库
6 self.db=self.client['huxiuv3']#新建数据库
7 defprocess_item(self, item, spider):8 self.db['huxiu_v5'].insert(dict(item))#第一种方法 #将数据存放到插入到表中
9 return item
pipelines
setting
以上,就完成了数据的获取。有了数据我们就可以着手分析,不过这之前还需简单地进行一下数据的清洗、处理。
















 473
473











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









