





2.14情人节,对单身狗来说就是折磨的日子,本着对自己的身心健康着想,我一天没出门,默默的爬取心目中的女神的微博记录。。。。。。。当然,女神不够,男的来凑,
OK。开始正题。
准备:python,request(请求url),re(正则), time(时间), tqdm(漂亮的动态加载),wordcloud(词云),jieba(分词), mayplotlib(画图展示),PIL(图像读取),numpy
因为只有登陆微博才可以爬取数据,否则用python得到的url页面不是原来的页面信息。而我没有这方面的高级姿势水平,所以我在网上搜索了一下。得出的结论是:首先手机端的微博数据比pc端的数据好怕,其次,需要得到一段微博服务器发过来的cookies,带着这个cookies才能畅通无阻。
好吧,手机端的问题很好解决,https://m.weibo.cn,打开就是手机端的微博了。
然后就是获取cookies。打开浏览器,这里我推荐firefox,在地址栏输入上面的网址,进入微博页面。按下F12,有些电脑则需要按Fn+F12, 或者在工具栏里点web开发者之类的,在点查看器。浏览器下方会弹出一个嗯....框框。。。,待会儿关注的是“网络”里的东西, 同时不要忘了吧“持续日志点上”,如果是英文的话应该是“。。。log”之类的。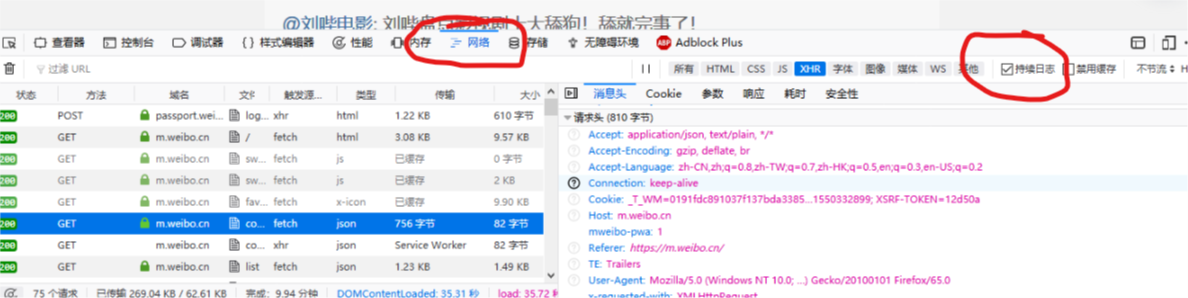
登陆你的微博账号,可以看到下面的框框里的数据变化,找到m.weibo.cn,点击,然后在右边的请求头里(header)找到cookie,复制下来,代码里会有用,注意要先全选,否则太长,中间会变成省略号。
看看想要爬取谁的微博了,刚才的页面,随便找一个人,点击他的主页,在地址栏中会看到有一个10位的数字,这个数字代表了账号在微博的代号。记录下来,代码里会用到。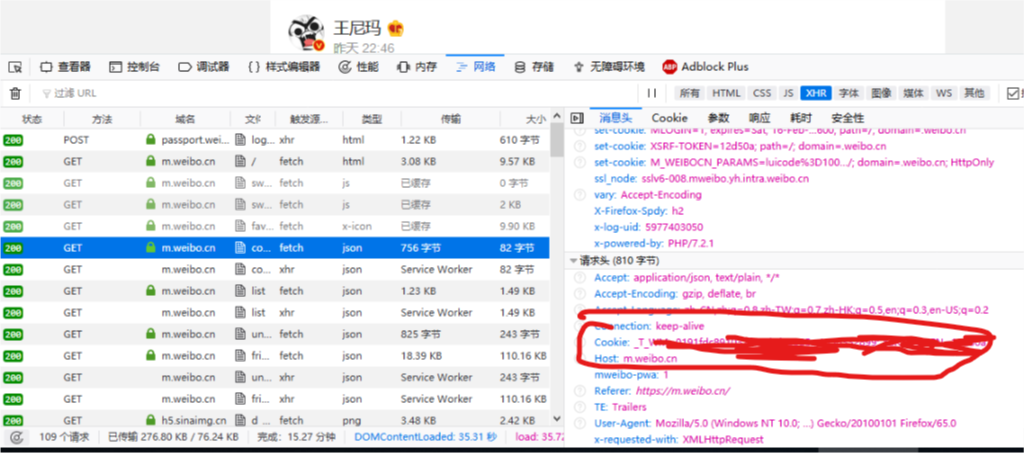
然后就是爬取了,简单的不多讲,,,,,,
具体的解析部分,我一开始用的xpath,但是一直找不到正确的内容,弄了很久,我很恼火,所以直接暴力的上了正则表达式,幸运的是成功解析,哈哈哈,真是的小天才~~~~~~,解析的代码就只有一行,嘻嘻。。。
微博爬取成功,文本分析我做的很少,简单做了个词云。这个东西很有用,大家可以从我的代码里分离出词云的代码,也可以从上期中下载移植到其它的文本啊,都是很漂亮的。
话不多说:代码附上!
链接: https://pan.baidu.com/s/1M7-0i4AyTikCTnMxHwlcEw 提取码: pcbk















 3261
3261











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









