






作者 | Marco Peixeiro
来源 | Medium
编辑 | 代码医生团队
介绍
本文试图成为理解和执行线性回归所需的参考。虽然算法很简单,但只有少数人真正理解了基本原理。
首先,将深入研究线性回归理论,以了解其内在运作。然后,将在Python中实现该算法来模拟业务问题。
理论

将如何研究线性回归
线性回归可能是统计学习的最简单方法。对于更先进的方法来说,这是一个很好的起点,事实上,许多花哨的统计学习技术可以看作是线性回归的扩展。因此理解这个简单的模型将为继续采用更复杂的方法奠定良好的基础。
线性回归非常适合回答以下问题:
2个变量之间是否存在关系?
关系有多强?
哪个变量贡献最大?
如何准确估计每个变量的影响?
能准确预测目标吗?
这种关系是线性的吗?(杜)
有互动效应吗?
估计系数
假设只有一个变量和一个目标。然后线性回归表示为:
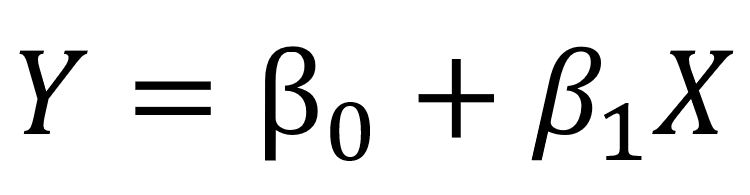
具有1个变量和1个目标的线性模型的方程
在上面的等式中,beta是系数。这些系数是需要的,以便用模型进行预测。
那么如何找到这些参数呢?
为了找到参数,需要最小化最小二乘或误差平方和。当然线性模型并不完美,它不能准确预测所有数据,这意味着实际值和预测之间存在差异。错误很容易通过以下方式计算:
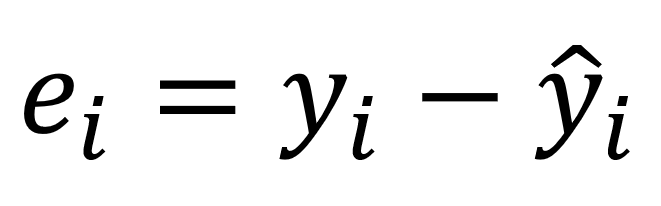
从真实值中减去预测
但为什么误差平方?
对误差进行平方,因为预测可以高于或低于真值,分别导致负差异或正差异。如果没有对误差进行平方,则由于负差异而导致的误差总和可能会减少,而不是因为模型非常适合。
此外平方误差会对较大的差异造成不利影响,因此最小化平方误差会“保证”更好的模型。
看一下图表以便更好地理解。
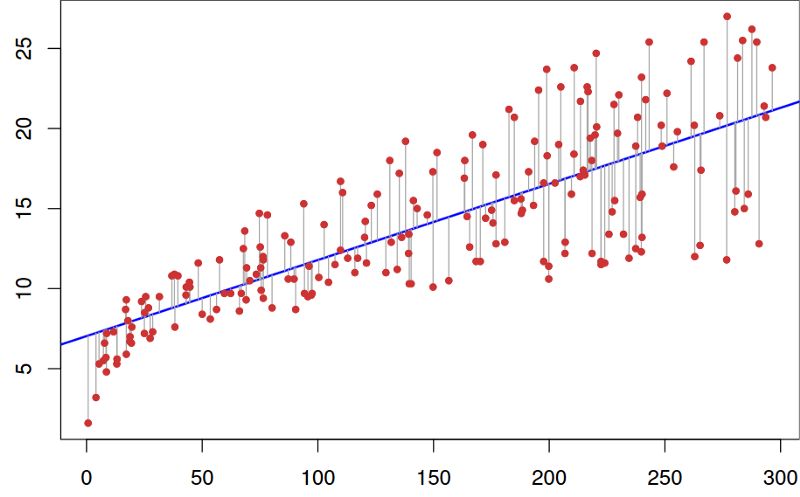
线性拟合数据集
在上图中,红点是真实数据,蓝线是线性模型。灰线表示预测值和真值之间的误差。因此蓝线是最小化灰线平方长度之和的线。
在对本文过于沉重的一些数学运算之后,最终可以使用以下等式估算系数:
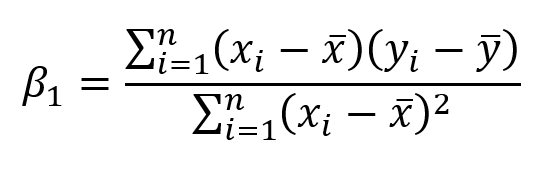
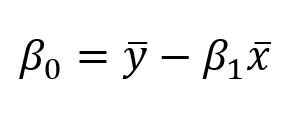
其中x bar和y bar代表平均值。
估计系数的相关性
既然有系数,那么如何判断它们是否与预测目标相关?
最好的方法是找到p值。该p值来定量统计学意义; 它允许判断零假设是否被拒绝。
零假设?
对于任何建模任务,假设是特征与目标之间存在某种相关性。因此零假设是相反的:特征与目标之间没有相关性。
因此,找到每个系数的p值将表明该变量在预测目标方面是否具有统计意义。作为一个经验一般规则,如果p值是小于0.05:有变量和目标之间有很强的关系。
评估模型的准确性
通过查找其p值发现变量具有统计显着性。
现在如何知道线性模型是否有用?
为了评估这一点,通常使用RSE(残差标准误差)和R²统计量。
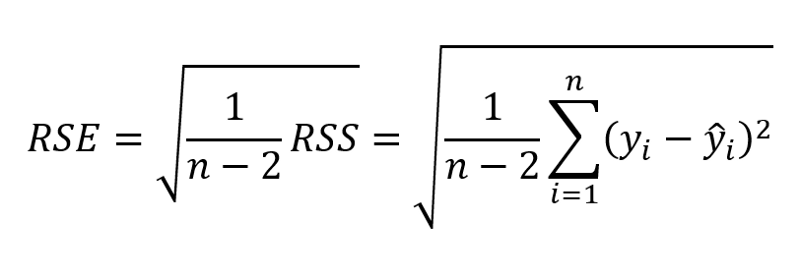
RSE公式
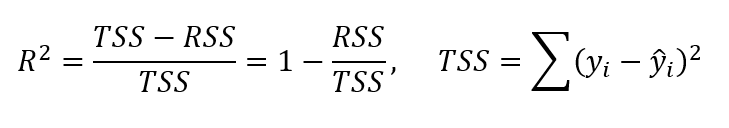
R²配方
第一个误差度量很容易理解:残差越小,模型越适合数据(在这种情况下,数据越接近线性关系)。
对于R²度量,它测量目标中可变性的比例,可以使用特征X来解释。因此假设线性关系,如果特征X可以解释(预测)目标,则比例高并且R 2值将接近1.如果相反,则R 2值接近0。
多元线性回归理论
在现实生活中,永远不会有一个功能来预测目标。那么一次对一个特征进行线性回归吗?当然不是。只需执行多元线性回归。
该方程与简单线性回归非常相似; 只需添加预测变量的数量及其相应的系数:
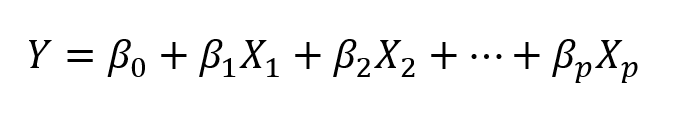
多元线性回归方程。p是预测变量的数量
评估预测变量的相关性
以前在简单线性回归中,通过查找其p值来评估特征的相关性。
在多元线性回归的情况下,使用另一个度量:F统计量。
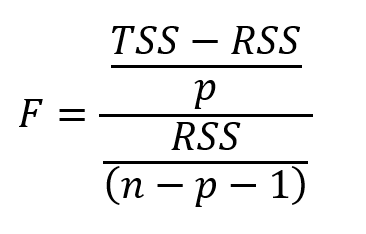
F统计公式。n是数据点的数量,p是预测变量的数量
这里针对整体模型计算F统计量,而p值对于每个预测值是特定的。如果存在强关系,则F将远大于1.否则,它将大约等于1。
如何大于 1足够大?
这很难回答。通常如果存在大量数据点,则F可能略大于1并表明存在强关系。对于小数据集,则F值必须大于1以表示强关系。
为什么不能在这种情况下使用p值?
由于拟合了许多预测变量,需要考虑一个有很多特征(p很大)的情况。有了大量的预测因子,即使它们没有统计学意义,也总会有大约5%的预测因子偶然会有非常小的p值。因此使用F统计量来避免将不重要的预测因子视为重要的预测因子。
评估模型的准确性
就像简单的线性回归一样,R²可以用于多元线性回归。但是要知道添加更多预测变量总是会增加R²值,因为模型必然更适合训练数据。
然而这并不意味着它在测试数据上表现良好(对未知数据点进行预测)。
添加互动
在线性模型中具有多个预测变量意味着某些预测变量可能对其他预测变量产生影响。
例如想要预测一个人的工资,了解她的年龄和在学校度过的年数。当然这个人年龄越大,这个人在学校度过的时间就越多。那么如何模拟这种互动效应呢?
考虑这个有两个预测变量的非常简单的例子:
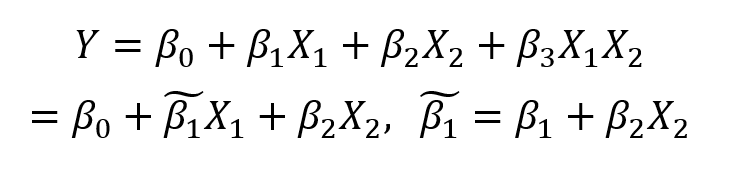
多元线性回归中的交互效应
简单地将两个预测变量相乘并关联一个新系数。简化公式,现在看到系数受另一个特征值的影响。
作为一般规则,如果包含交互模型,应该包括特征的单独效果,即使它的p值不重要。这被称为分层原则。这背后的基本原理是,如果两个预测变量相互作用,那么包括它们的个体贡献将对模型产生很小的影响。
好的!现在知道它是如何工作的,让它让它工作!将通过Python中的简单和多元线性回归进行研究,并将展示如何在两种情况下评估参数的质量和整体模型。
可以在此处获取代码和数据。
https://github.com/marcopeix/ISL-linear-regression
强烈建议按照并重新创建Jupyter笔记本中的步骤,以充分利用本教程。
介绍
该数据集包含有关广告花费和生成的销售额的信息。钱花在电视,广播和报纸广告上。
目标是使用线性回归来了解广告支出如何影响销售。
导入库
使用Python的优势在于可以访问许多库,这些库允许快速读取数据,绘制数据并执行线性回归。
喜欢在笔记本上导入所有必要的库,以保持一切井井有条。导入以下内容:
import pandas as pdimport numpy as npimport matplotlib.pyplot as pltfrom sklearn.linear_model import LinearRegressionfrom sklearn.metrics import r2_scoreimport statsmodels.api as sm阅读数据
假设下载了数据集,请将其放在data项目文件夹中的目录中。然后,像这样读取数据:
data = pd.read_csv("data/Advertising.csv")要查看数据的外观,执行以下操作:
data.head()应该看到这个:
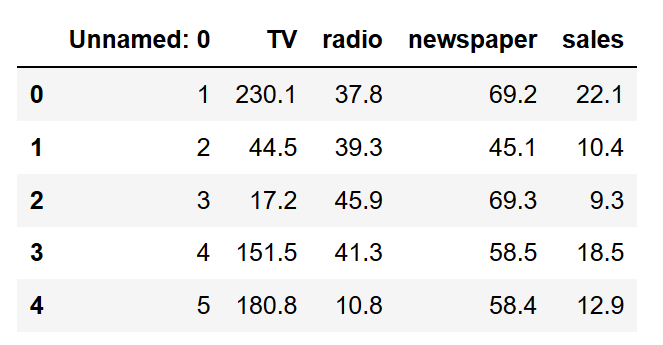 该列Unnamed: 0是多余的。因此删除它。
该列Unnamed: 0是多余的。因此删除它。
data.drop(['Unnamed: 0'], axis=1)好吧数据很干净,可以进行线性回归!
简单线性回归
造型
对于简单的线性回归,只考虑电视广告对销售的影响。在直接进入建模之前,看一下数据的样子。
使用matplotlib 一个流行的Python绘图库来制作散点图。
plt.figure(figsize=(16, 8))plt.scatter( data['TV'], data['sales'], c='black')plt.xlabel("Money spent on TV ads ($)")plt.ylabel("Sales ($)")plt.show()运行此代码单元格,应该看到此图表:
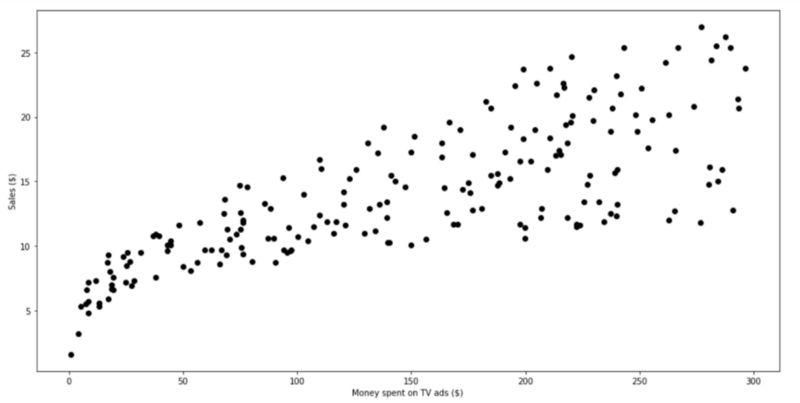
分散在电视广告和销售上花钱的情节
电视广告和销售额之间存在明显的关系。
看看如何生成这些数据的线性近似。
X = data['TV'].values.reshape(-1,1)y = data['sales'].values.reshape(-1,1)reg = LinearRegression()reg.fit(X, y)print("The linear model is: Y = {:.5} + {:.5}X".format(reg.intercept_[0], reg.coef_[0][0]))将直线拟合到数据集并查看等式的参数就很简单。在这种情况下
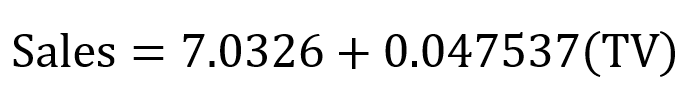
简单线性回归方程
想象一下这条线如何适合数据。
predictions = reg.predict(X)plt.figure(figsize=(16, 8))plt.scatter( data['TV'], data['sales'], c='black')plt.plot( data['TV'], predictions, c='blue', linewidth=2)plt.xlabel("Money spent on TV ads ($)")plt.ylabel("Sales ($)")plt.show()而现在看到:
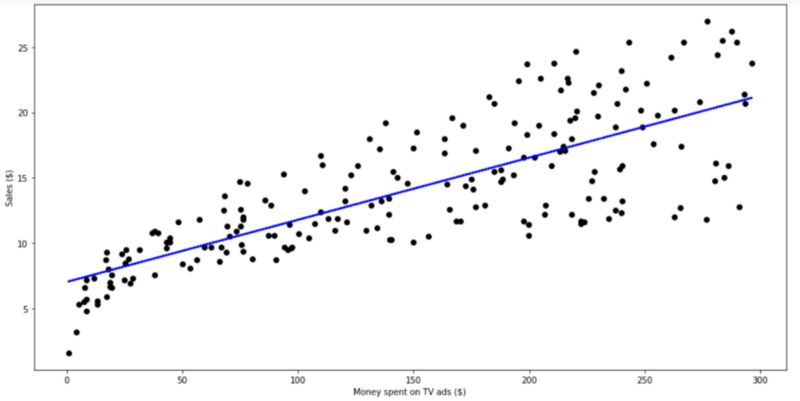
线性拟合
从上图可以看出,简单的线性回归似乎可以解释花在电视广告和销售上的金额的一般影响。
评估模型的相关性
看看模型是否有用,需要查看R²值和每个系数的p值。
是这样做的:
X = data['TV']y = data['sales']X2 = sm.add_constant(X)est = sm.OLS(y, X2)est2 = est.fit()print(est2.summary())这给这个可爱的输出:
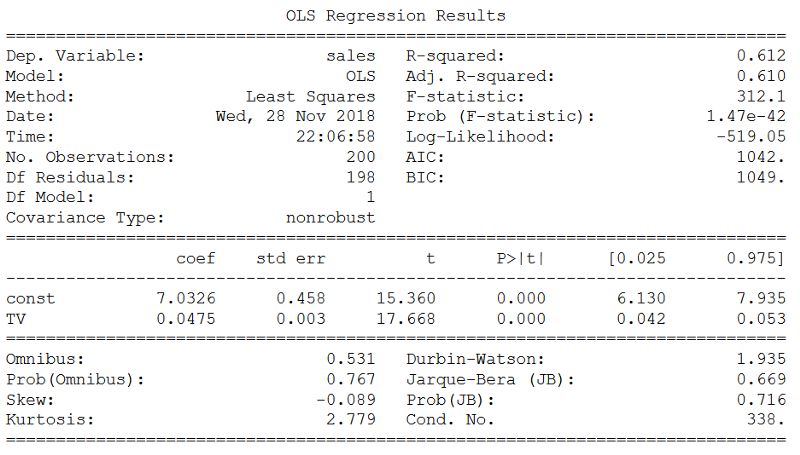
R²和p值
看两个系数,得到一个非常低的p值(虽然它可能不完全是0)。这意味着这些系数与目标(销售额)之间存在很强的相关性。
然后看看R²值,有0.612。因此,大约60%的销售可变性是由电视广告花费的金额来解释的。这没关系,但绝对不是能够准确预测销售额的最佳方法。当然,报纸和广播广告的支出必然会对销售产生一定的影响。
让看看多元线性回归是否会表现得更好。
多元线性回归
模型
就像简单的线性回归一样,将定义特征和目标变量,并使用scikit-learn库来执行线性回归。
Xs = data.drop(['sales', 'Unnamed: 0'], axis=1)y = data['sales'].reshape(-1,1)reg = LinearRegression()reg.fit(Xs, y)print("The linear model is: Y = {:.5} + {:.5}*TV + {:.5}*radio + {:.5}*newspaper".format(reg.intercept_[0], reg.coef_[0][0], reg.coef_[0][1], reg.coef_[0][2]))从这个代码单元格中,得到以下等式:
多元线性回归方程
无法想象所有三种媒介对销售的影响,因为它总共有四个维度。
请注意,报纸的系数是负数,但也相当小。它与模型有关吗?通过计算每个系数的F统计量,R²值和p值来看。
评估模型的相关性
此处的过程与在简单线性回归中所做的非常相似。
X = np.column_stack((data['TV'], data['radio'], data['newspaper']))y = data['sales']X2 = sm.add_constant(X)est = sm.OLS(y, X2)est2 = est.fit()print(est2.summary())得到以下内容:
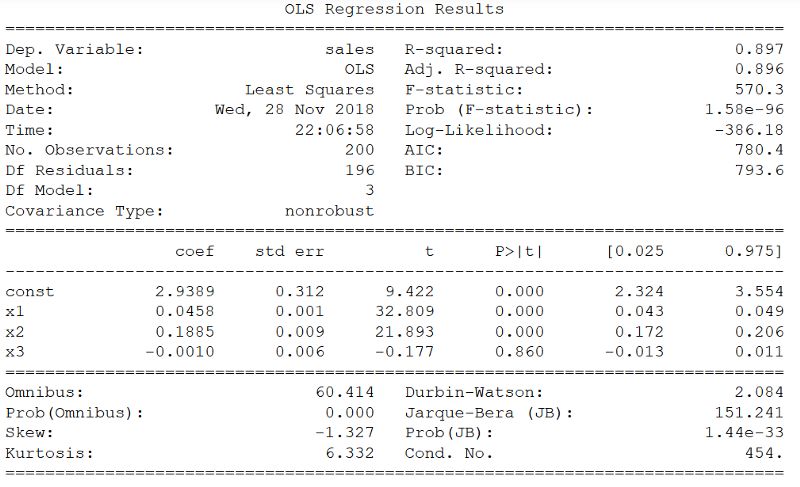
R²,p值和F统计量
R²远高于简单线性回归,其值为0.897!
此外F统计量为570.3。这远远大于1,并且由于数据集相当小(仅200个数据点),它表明广告支出与销售之间存在很强的关系。
最后因为只有三个预测变量,可以考虑p值来确定它们是否与模型相关。当然注意到第三个系数(报纸的系数)具有较大的p值。因此报纸上的广告支出在统计上并不显着。删除该预测器会略微降低R²值,但可能会做出更好的预测。
如前所述,这可能不是表现最佳的算法,但对于理解线性回归非常重要,因为它构成了更复杂的统计学习方法的基础。
推荐阅读
使用TensorFlow进行线性回归
关于图书
《深度学习之TensorFlow:入门、原理与进阶实战》和《Python带我起飞——入门、进阶、商业实战》两本图书是代码医生团队精心编著的 AI入门与提高的精品图书。配套资源丰富:配套视频、QQ读者群、实例源码、 配套论坛:http://bbs.aianaconda.com 。更多请见:https://www.aianaconda.com















 293
293











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









