






本文主要包含以下内容:
1 简介
2 最大似然和最小二乘
3 最小二乘几何
4 序列学习
5 正则化最小二乘
6 多元输出
1 简介
其中。这通常称为线性回归(linear regression)。这个模型的主要的属性是其是参数的线性函数。同时也是变量的线性函数,这个暗示了模型的限制。
因此,通过输入变量的固定的非线性函数的组合来扩展这个模型的类:
其中是基函数(basis functions),其最大值的索引是,所以模型中的参数一共有个。
参数允许数据中有任何固定的偏移,有时称为偏差(bias)(不要与统计学意义上的“偏差”混淆)。通常会定义一个额外的哑基函数,这样方便计算,即:
式中 , 。
在模式识别的应用中,对原始数据变量,会应用固定的预处理形式或特征提取。如果原始变量包含向量,则特征可以用基函数表示。
通过使用非线性基函数,则函数是输入向量的非线性函数。
式2形式的函数被称为线性模型,因为在中是线性。参数的线性化会简化这类模型的计算,但也会导致一些限制。
多项式回归就是这个模型的一个特例,基函数是。多项式基函数的一个限制是他们是输入变量的全局函数,所以输入空间的一个区域变化会影响其他区域。这个可以通过将输入空间划分成不同的区域并在每个区域拟合一个不同的多项式来解决,这会导致样条函数(spline functions)。
其中控制输入空间的基函数的位置,参数控制空间尺度。这些被认为是高斯基函数,尽管不需要一个概率解释,但归一化系数是不重要的,因为基函数将乘以自适应参数。
另一个s形的基函数的概率形式为:
是逻辑sigmoid函数,定义如下:
式同样地,可以用tanh函数,因为,与sigmoid相关,所以逻辑sigmoid函数的线性组合等价于‘tanh’函数的线性组合。这些基函数的各种选择如图1所示。

另一个基函数的可能选择是傅里叶基函数,其是正弦函数的扩展。每个基函数表示一个特定的频率并且有无限的空间延伸。对比发现,基函数是在由不同空间频率光谱组成的输入空间的有限区域内局部化。在许多信号处理中,感兴趣的是在空间和频率上局部化的基函数,即小波(wavelets)。它们也被定义为相互正交,以简化它们的应用。小波最适用于输入值位于规则晶格上的情况,例如时间序列中连续的时间点,或图像中的像素。
2 最大似然和最小二乘
假设目标变量由决定方程和加性高斯噪声给出,则:
式式中是均值为0的高斯随机变量,其精度为。因此可以写成:
如果假设损失函数是平方损失函数,则对于新值的最佳预测将由目标变量的条件均值给出。根据条件高斯分布式8,条件均值可以简化为:
高斯噪声假设暗示给定下的条件分布是单峰的,这可能不适合某些应用。条件高斯分布混合的扩展允许多峰条件分布。
现在考虑输入数据集,以及相应的目标值。将目标变量分组成一个列向量,用铅字体表示,区别于多元目标的单个观察。假设这些数据点是独立地从分布式8中采样,则得到以下的似然函数的表达式,它是可调参数和的一个函数,形式如下:
式中利用了式3。在监督学习中如回归和分类,我们不是寻找输入变量的分布模型。因为总是会出现在条件变量集中,所以从现在开始将从表达式中显示地删除如删除以保持符号整洁。
取似然函数的对数并利用单元高斯的标准形式,则有:
式中平方和误差函数定义如下:
已经写好了似然函数,下面用似然函数确定和。首先考虑对最大化。线性模型的条件高斯噪声的似然函数的最大化等价于最小化平方和误差函数。对数似然函数的梯度形式为:
梯度设为0:
然后得到:
式上式被称为最小二乘问题的正规方程(normal equations)。是一个的矩阵,称为设计矩阵(design matrix),其元素由给出,所以:
数量:
式被称为矩阵的Moore-Penrose pseudo-inverse。它可以看作是矩阵逆的概念在非方阵上的推广。事实上,如果是方阵且是可逆的,那么使用属性,我们看到。
此时,我们可以对偏差参数的作用有一些了解。如果使偏差参数显式,那么误差函数(式12)变为:
对求导令其等于0,并求出,得到:
式中定义了:
因此偏差补偿(在训练集上)目标值的平均值与基函数值的平均值的加权和之间的差异。
也可以对噪声精度参数最大化对数似然函数式11,得到:
因此可以看到噪声精度的逆由回归函数周围的目标值的剩余方差(residual variance)给出。
3 最小二乘几何
考虑最小二乘解的几何解释。考虑一个维空间,其轴用表示,因此在这个空间是一个向量。个数据点计算的每个基函数也可以用在同样空间里的向量表示,如图2所示。

对应的第列,对应的第行。如果基函数的数量远小于数据点数量,则个向量将会扩张成维数为的线性子空间。
定义是一个维向量,其第个元素由给出,其中。因为是向量的任意线性组合,所以它可以存在维子空间的任何地方。平方和误差式12等于和之间的欧式距离的平方。因此的最小二乘解对应在子空间中最接近的。
根据图2,这种解决方案对应于在子空间上的正交投影。确实是这种情况,通过指出由给出可以很容易地验证。然后确认这是一个正交投影的形式。
在实践中,正规方程的一个直接的解决方案会导致数值困难当接近奇异时。特别是,当两个或更多的基向量是共线的,或几乎共线,得到的参数值可以有很大的大小。这种近似简并(near degeneracies )在处理真实数据集时并不少见。由此产生的数值困难可以用奇异值分解技术来解决,即SVD(singular value decomposition)。注意正则化项的加入确保了矩阵是非奇异的,即使存在退化(degeneracies)。
4 序列学习
批处理技术,例如涉及一次性处理整个训练集的最大似然解(式15),对于大型数据集来说计算成本很高。如果数据集足够大,那么使用顺序算法(sequential algorithms)可能是值得的,也称为在线算法(on-line algorithms),在这种算法中,每次考虑一个数据点,并在每次这样的展示后更新模型参数。顺序学习也适用于实时应用,在这种应用中,数据观察是在一个连续的流中到达的,并且必须在看到所有数据点之前做出预测。
我们可以通过应用随机梯度下降(stochastic gradient descent)技术,也称为顺序梯度下降(sequential gradient descent),来获得一个顺序学习算法。如果误差函数包含数据点的和,则在模式出现后,随机梯度下降算法更新参数向量使用:
式式中表示迭代次数,表示学习率。的值被初始化为向量。对于平方和误差函数式12,得:
式中。这被称为最小均方算法(least-mean-squares)或LMS算法。在选择值时需要谨慎,以确保算法收敛。
5 正则化最小二乘
为了控制过拟合,我们在误差函数中引入了添加正则项的思想,从而使总误差函数最小化:
是正则化系数,控制数据误差和正则化项的相对重要性。正则项的一个简单形式由权重向量元素的平方和给出:
也要考虑平方和误差函数:
则总误差函数变为:
这种特殊的正则化选择在机器学习文献中被称为权值衰减(weight decay),因为在顺序学习算法中,它鼓励权值向零衰减,除非有数据支持。在统计学中,它提供了一个参数收缩(parameter shrinkage)方法的示例,因为它将参数值收缩到接近于零。
它的优点是误差函数仍然是的二次函数,因此它的精确极小值可以以封闭的形式找到。具体来说,将式27关于的梯度设为零,像前面一样求解,我们得到:
式这代表了最小二乘解(式15)的简单扩展。
有时会使用更一般的正则化,正则化误差采用这种形式:
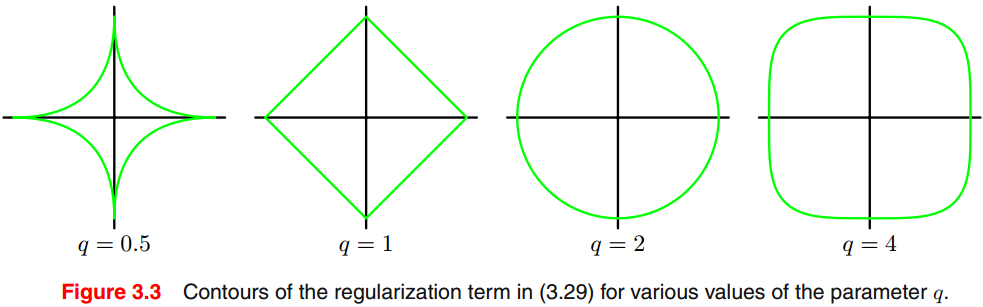
其中对应二次正则化(式27)。图3给出了不同值下的正则化函数轮廓,的情况在统计文献中称为lasso。它的性质是,如果足够大,一些系数就会趋近于零,从而形成一个相应的基函数不发挥作用的稀疏模型(sparse model)。
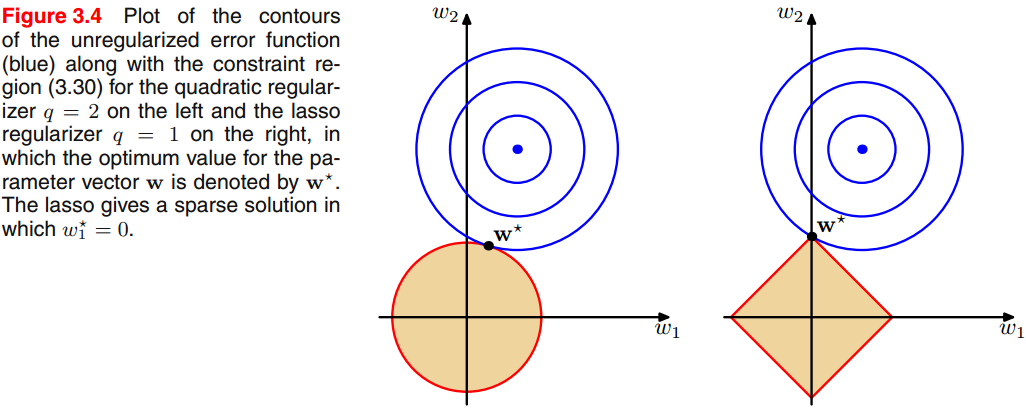
为了了解这一点,我们首先注意到最小化(式29)等价于最小化受约束的非正则化平方和误差(式12)
式为了获得参数的适当值,其中可以将这两种方法关联起来 使用拉格朗日乘子。稀疏度的起源可以从图4中看出,在约束条件(式30)下误差函数的最小值。随着参数的增加,越来越多的参数被归零。
通过限制模型的有效复杂度,正则化使得复杂模型可以在有限大小的数据集上进行训练,而不会出现严重的过拟合。然而,确定最优模型复杂度的问题从寻找合适的基函数数量转移到确定正则化系数的合适值。
6 多元输出
到目前为止,已经考虑了单一目标变量的情况。在某些应用中,我们可能希望预测的目标变量,用目标向量表示。这可以通过为的每个成分引入一组不同的基函数来实现,从而导致多个独立的回归问题。然而,一种更有趣、更常见的方法是使用相同的基函数集对目标向量的所有成分建模,所以:
式式中,为维列向量,为参数的的矩阵,而为元素为的维列向量,而。假设目标向量的条件分布为各向同性高斯分布形式:
如果有一组观测,我们可以把它们组合成一个大小为的矩阵,使第行由给出。同样,我们可以将输入向量组合为矩阵,则对数似然函数为:
和之前一样,我们可以最大化这个关于的函数:
式如果检查每个目标变量的结果,有
其中为维列向量,其成分为。因此,对回归问题的求解需要在不同的目标变量之间解耦,并且我们只需要计算一个伪逆矩阵,这是由所有的向量共享。
推广到具有任意协方差矩阵的一般高斯噪声分布是直接的。同样,这导致了个独立回归问题的解耦。这个结果并不令人惊讶,因为参数只定义了高斯噪声分布的平均值,并且我们知道多元高斯分布的平均值的最大似然解是独立于协方差的。因此,从现在开始,为了简单起见,我们将考虑单一目标变量。
















 2620
2620











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









