





 本文介绍了如何使用Python爬虫从CSDN获取个人资源的URL、名称、下载量、分数等信息,重点讲解了如何人工分析HTML页面以获取评论。作者还提及了计划后续分析如何抓取JS加载的评论,并为读者提供了获取高评分资源的技巧。
本文介绍了如何使用Python爬虫从CSDN获取个人资源的URL、名称、下载量、分数等信息,重点讲解了如何人工分析HTML页面以获取评论。作者还提及了计划后续分析如何抓取JS加载的评论,并为读者提供了获取高评分资源的技巧。
这是一篇Python爬取CSDN下载资源信息的样例,主要是通过urllib2获取CSDN某个人全部资源的资源URL、资源名称、下载次数、分数等信息。写这篇文章的原因是我想获取自己的资源全部的评论信息。可是因为评论採用JS暂时载入。所以这篇文章先简介怎样人工分析HTML页面爬取信息。
源码# coding=utf-8
import urllib
import time
import re
import os
#**************************************************
#第一步 遍历获取每页相应主题的URL
#http://download.csdn.net/user/eastmount/uploads/1
#http://download.csdn.net/user/eastmount/uploads/8
#**************************************************
num=1 #记录资源总数 共46个资源
number=1 #记录列表总数1-8
fileurl=open('csdn_url.txt','w+')
fileurl.write('****************获取资源URL*************\n\n')
while number<9:
url='http://download.csdn.net/user/eastmount/uploads/' + str(number)
fileurl.write('下载列表URL:'+url+'\n\n')
print unicode('下载列表URL:'+url,'utf-8')
content=urllib.urlopen(url).read()
open('csdn.html','w+').write(content)
#获取包括URL块内容 匹配须要计算
个数start=content.find(r'
end=content.find(r'
cutcontent=content[start:end]
#print cutcontent
#获取块内容中URL
#形如
标题
res_dt = r'
(.*?)'m_dt = re.findall(res_dt,cutcontent,re.S|re.M)
for obj in m_dt:
#记录URL数量
print '******************************************'
print '第'+str(num)+'个资源'
fileurl.write('******************************************\n')
fileurl.write('第'+str(num)+'个资源\n')
num = num +1
#获取详细URL
url_list = re.findall(r"(?<=href=\").+?(?=\")|(?<=href=\').+?
(?=\')", obj)
for url in url_list:
url_load='http://download.csdn.net'+url
print 'URL: '+url_load
fileurl.write('URL: http://download.csdn.net'+url+'\n')
#获取资源标题
res_title = r'(.*?)'
title = re.findall(res_title,obj,re.S|re.M)
for t in title:
print unicode('Title: ' + t,'utf-8')
fileurl.write('Title: ' + t +'\n')
#**************************************************
#第二步 遍历详细资源的内容及评论
#http://download.csdn.net/detail/eastmount/8785591
#**************************************************
#定位指定结构化信息盒Infobox
resources = urllib.urlopen(url_load).read()
open('resource.html','w+').write(resources)
start_res=resources.find(r'
end_res=resources.find(r'
infobox=resources[start_res:end_res]
#获取资源积分、下载次数、资源类型、资源大小(前4个)
res_span = r'(.*?)'
m_span = re.findall(res_span,infobox,re.S|re.M)
print '资源积分: '+m_span[0]
fileurl.write('资源积分: ' + m_span[0] +'\n')
print '下载次数: '+m_span[1]
fileurl.write('下载次数: ' + m_span[1] +'\n')
print '资源类型: '+m_span[2]
fileurl.write('资源类型: ' + m_span[2] +'\n')
print '资源大小: '+m_span[3]
fileurl.write('资源大小: ' + m_span[3] +'\n')
#**************************************************
#第三步 怎样获取评论
#http://jeanphix.me/Ghost.py/
#http://segmentfault.com/q/1010000000143340
#http://casperjs.org/
#**************************************************
else:
fileurl.write('******************************************\n\n')
print '******************************************\n'
print 'Load Next List\n'
number = number+1 #列表加1
#退出全部循环
else:
fileurl.close()
显示结果
显示内容包含资源URL、资源标题、资源积分、下载次数、资源类型和资源大小:
HTML分析首先。获取每列中的全部资源的URL和标题,通过分析源码。

0
上传者:| 上传时间:2015-06-04
| 下载26次
该资源主要參考我的博客【数字图像处理】六.MFC空间几何变换之图像平移、镜像、旋转
缩放具体解释,主要讲述基于VC++6.0 MFC图像处理的应用知识,要通过MFC单文档视图实现显
示BMP图片。
图像处理<
相应的HTML显演示样例如以下图所看到的: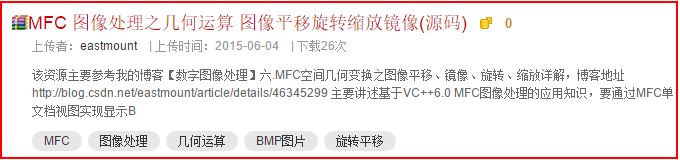
然后通过URL去到详细的资源获取我自己称为像消息盒的信息:
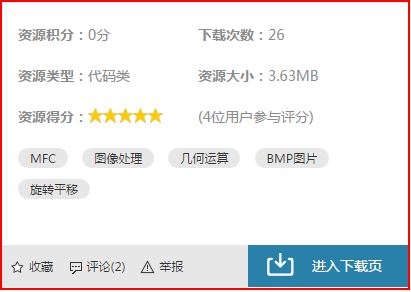
相应审查元素的信息例如以下所看到的。获取0分就可以:

最后我想做的事获取评论信息,可是它是通过JS实现的:
资源评论
var base_url= (window.location.host.substring(0,5)=='local') ? 'http://local.downloadv3.csdn.net' : 'http://download.csdn.net';
base_url = "";
$(document).ready(function(){
CC_Comment.initConfig();
CC_Comment.getContent(1);
});
var CC_Comment =
{
sourceid:0,
initConfig:function()
{
var sid = parseInt($(".download_comment").attr('sourceid'));
if(isNaN(sid) || sid<=0)
{
this.sourceid = 0;
}else
{
this.sourceid = sid;
}
}
....
}
最后希望文章对你有所帮助吧!
下一篇准备分析下Python怎样获取JS的评论信息,同一时候该篇文章能够给你提供一种简单的人工分析页面的样例;也能够获取某个人CSDN资源下载多、分数高的给你挑选。基础知识,仅供參考~
(By:Eastmount 2015-7-21 下午5点http://blog.csdn.net/eastmount/)















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









