




R中提供了许多用来整合(aggregate)和重塑(reshape)数据的强大方法。在整合数据时,往往将多组观测替换为根据这些观测计算的描述性统计量。在重塑数据时,则会通过修改数据的结构(行和列)来决定数据的组织方式。
一、整合数据
在R中使用一个或多个by变量和一个预先定义好的函数来折叠(collapse)数据是比较容易的。调用格式为:
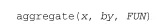
x是待折叠的数据对象, by是一个变量名组成的列表,这些变量将被去掉以形成新的观测,而FUN则是用来计算描述性统计量的标量函数,它将被用来计算新观测中的值。
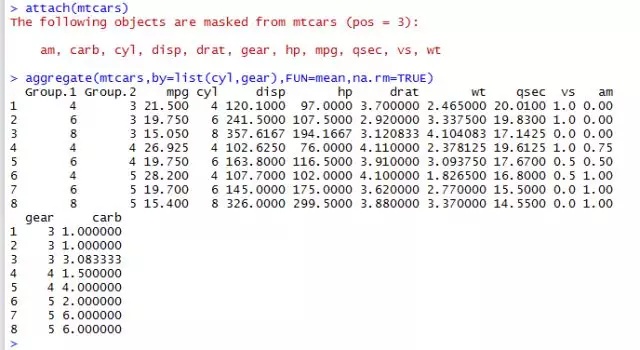
在结果中,Group.1表示汽缸数量(4、6或8), Group.2代表挡位数(3、4或5)。举例来说,拥有4个汽缸和3个挡位车型的每加仑汽油行驶英里数(mpg)均值为21.5。
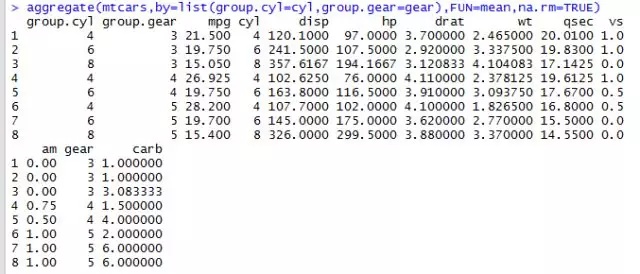
在使用aggregate()函数的时候, by中的变量必须在一个列表中(即使只有一个变量)。你可 以 在 列 表 中 为 各 组 声 明 自 定 义 的 名 称 , 例 如by=list(Group.cyl=cyl, Group.gears=gear)。指定的函数可为任意的内建或自编函数,这就为整合命令赋予了强大的力量。
二、reshape包
基本原理
首先将数据“融合”(melt),以使每一行都是一个唯一的“标识符—变量”组合。然后将数据“重铸”(cast)为想要的任何形状,在重铸过程中,可以使用任何函数对数据进行整合。
(一)融合
1、原始数据:在本例中,标识符是指ID、Time以及观测属于X1还是X2)唯一地确定。举例来说,在知道ID为1、Time为1,以及属于变量X1之后,即可确定测量值为第一行中的5。
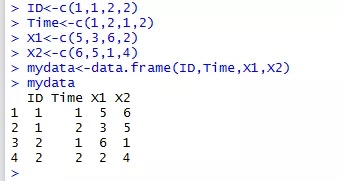
2、数据融合:数据集的融合是将它重构为这样一种格式:每个测量变量独占一行,行中带有要唯一确定这个测量所需的标识符变量。数据融合的结果是形成“ID (主键)— 属性 —属性值”
一般我们见到的数据框形式:

aggdata<-melt(data,id=c(variable1 ) ),融合后的数据格式:


(二)重铸数据
1、重铸后的数据格式
newdata<-cast(aggdata, variable 1+ variable 2~ variable 3+ variable 4,fun)


2、cast函数解释
cast()函数读取已融合的数据,并使用你提供的公式和一个(可选的)用于整合数据的函数将其重塑。调用格式为:
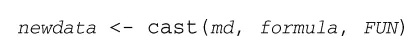
其中的md为已融合的数据, formula描述了想要的最后结果,而FUN是(可选的)数据整合函数。其接受的公式形如:
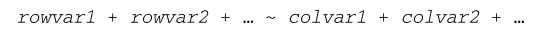
在这一公式中, rowvar1 + rowvar2 + ...定义了要划掉的变量集合,以确定各行的内容,而colvar1 + colvar2 + ...则定义了要划掉的、确定各列内容的变量集合。
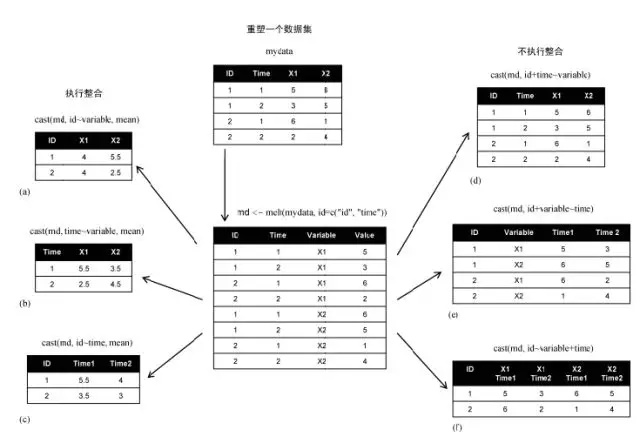
由于右侧(d、 e和f)的公式中并未包括某个函数,所以数据仅被重塑了。反之,左侧的示例(a、 b和c)中指定了mean作为整合函数,从而就对数据同时进行了重塑与整合。例如, (a)中给出了每个观测所有时刻中在X1和X2上的均值;示例(b)则给出了X1和X2在时刻1和时刻2的均值,对不同的观测进行了平均;在(c)中则是每个观测在时刻1和时刻2的均值,对不同的X1和X2进行了平均。

















 1202
1202

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









