



 本文详细介绍了MySQL窗口函数的概念、用途和常见操作,包括rank、dense_rank、row_number的区别,以及如何解决经典排名和TOP N问题。通过实例展示了窗口函数在分组、排序、移动平均等场景的应用,强调其在数据分析中的重要作用。
本文详细介绍了MySQL窗口函数的概念、用途和常见操作,包括rank、dense_rank、row_number的区别,以及如何解决经典排名和TOP N问题。通过实例展示了窗口函数在分组、排序、移动平均等场景的应用,强调其在数据分析中的重要作用。

本次需要学习有如下几个部分:
一、什么是窗口函数
二、专用窗口函数rank,dense_rank,row_number有什么区别
三、经典排名问题
四、经典TOP n问题
五、聚合函数作为窗口函数
六、每组中比较
七、窗口函数的移动平均
八、总结
下面为以上内容一一解答:
一、什么是窗口函数
窗口函数,也叫OLAP函数(online anallytical processing ,联机分析处理),可以对数据库数据进行实时分析处理。
基本语法如下:
over (partition by <用于分组的列名>
order by <用于分组的列名>)
窗口函数是对where或者group by子句处理后的结果进行操作,所以窗口函数原则上只能写在select子句中。
实例:

想要在班级分组之后再进行排序,结果如下

select *,rank()over (partition by 班级
order by 成绩 desc)as ranking from 班级表
解释:rank是排序的函数。要求是“每个班级内按成绩排名”,这句话可以分为两部分:
1.每个班级内:按班级分组
partition by用来对表分组。在这个例子中,所以我们指定了按“班级”分组(partition by 班级)
2.按成绩排名
order by 子句的功能是对分组后的结果进行排序,默认是按照升序(asc)排序。在本例中是降序
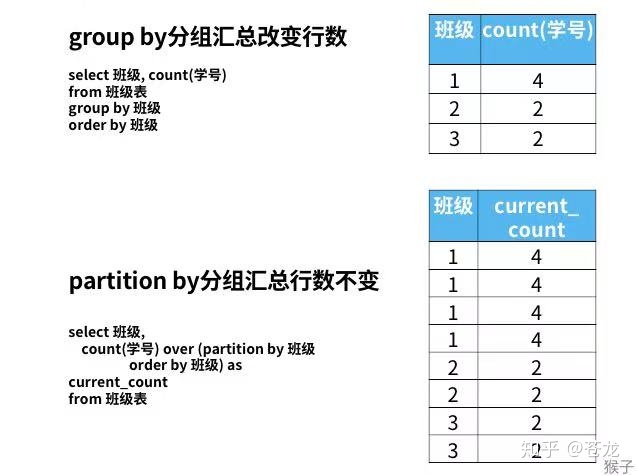
窗口函数分组与group by分组的区别:
grooup by分组汇总后改变了表的行数,一行只有一个类别。而partition by和rank函数不会减少原表中的行数。
例如:
统计每个班级的人数
为什么叫窗口函数呢?
这是因为partition by 分组后的结果称为"窗口”,这里的窗口不是我们家里的门窗,而是表示范围的意思
简单来说,窗口函数有以下功能:
1.同时具有分组和排序的功能
2.不减少原表的行数
3.语法:
over (partition by <用于分组的列名>
order by <用于分组的列名>)
二、专用窗口函数rank,dense_rank,row_number有什么区别?
用实例来说明:
语法:
select *,
rank()over (order by 成绩 desc)as ranking,
dense_rank()over (order by 成绩 desc)as dese_rank,
row_number()over (order by 成绩 desc)as row_number from 班级表
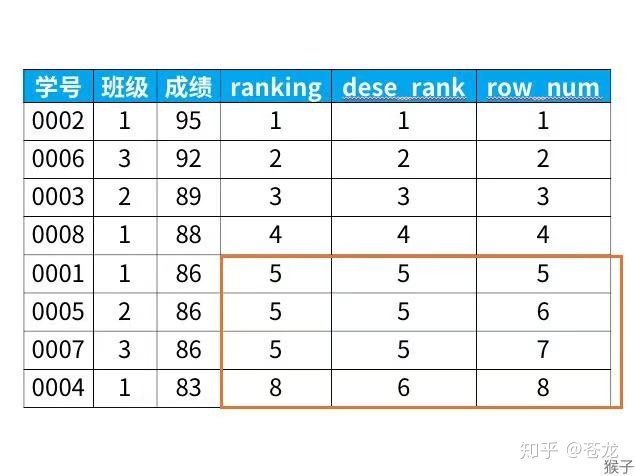
从上面的结果可以看出:
rank函数:这个例子中是5位,5位,5位,8位,也就是如果有并列名次的行,会占用下一名次的位置。比如正常排名是1,2,3,4,但是现在在前3名是并列的名次,结果是1,1,1,4。
dense_rank函数:这个例子中是5位,5位,5位,6位,也就是如果有并列名次的行,不占用下一名次的位置。比如正常排名是1,2,3,4,但是现在前3名是并列的名次,结果是1,1,1,2。
row_number函数:这个例子中是5位,6位,7位,8位,也就是不考虑并列名次的情况。比如前3名是并列的名次,排名是正常的1,2,3,4。
最后强调的是:在上述的这三个专用窗口函数,函数后面的括号不需要任何参数,保持()空着就可以。
三、经典排名问题
下图是班级表中的内容,记录了每个学生所在班级和对应的成绩,现在需要按成绩来排名,如果两个分数相同,那么排名要是并列的。
解题思路;
1.涉及排名问题,可以用窗口函数
2.根据题目要求的排名规则,选择专用函数中的dense_rank函数。
select * ,
dense_rank()over (order by 成绩 desc)as dese_rank from 班级;
四、经典TOP n问题
结合此个案例按课程号分组取成绩最大值所在行的数据
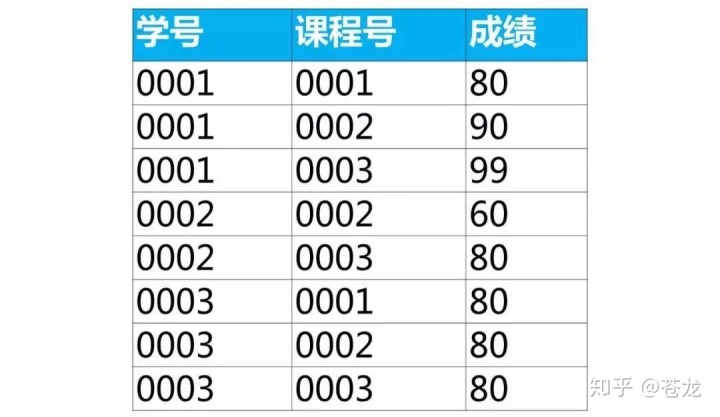
select 课程号,max(成绩)as 最大成绩 from score group by 课程号;
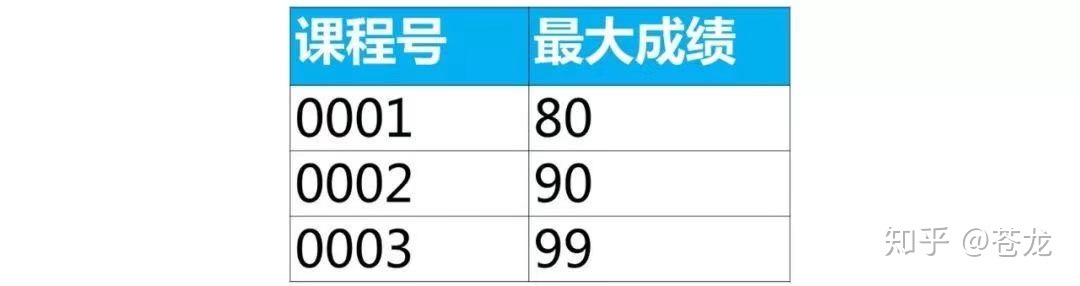
用group by分组汇总函数可以得到每组李的一个值(最大值,最小值,平均值等)。但是无法得到成绩最大值所在行的数据。
使用关联子查询,可以查询所在行的数据
select * from score as a where 成绩 = (select max(成绩)from score as b where b.课程号=a.课程号);
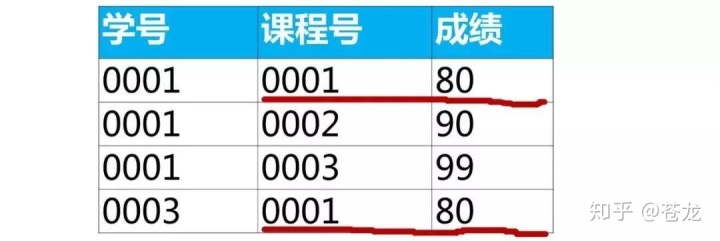
例:查询各科成绩前两名的记录
解题思路:
1.看到问题中要查每个学生最高的成绩,每个就要分组。
2.将表按学生姓名分组后,把成绩按降序排序,排在最前面的2个就是我们要找的成绩最高的2个科目
3.现在分组后,需要排序,又不减少原表的行数,这种功能就会想到窗口函数
4.使用哪个专用窗口函数?为了不受并列成绩的影响,使用row_number 专用窗口函数
select *from(select *,row_number ()over (partition by 姓名 order by 成绩 desc )as ranking from 成绩表) as a where ranking <=2;
每组最大的N条记录,通用公式:
select *from(select *,row_number ()over (partition by 要分组的列名 order by 要排序的列名 desc )as ranking from 表名 as a)where ranking <=N;
五、聚合函数作为窗口函数
select * ,
sum(成绩)over (order by 学号)as current_sum,
avg(成绩)over (order by 学号)as current_avg,
count(成绩)over (order by 学号)as current_count,
max(成绩)over (order by 学号)as current_max,
min(成绩)over (order by 学号)as current_min
from 班级表
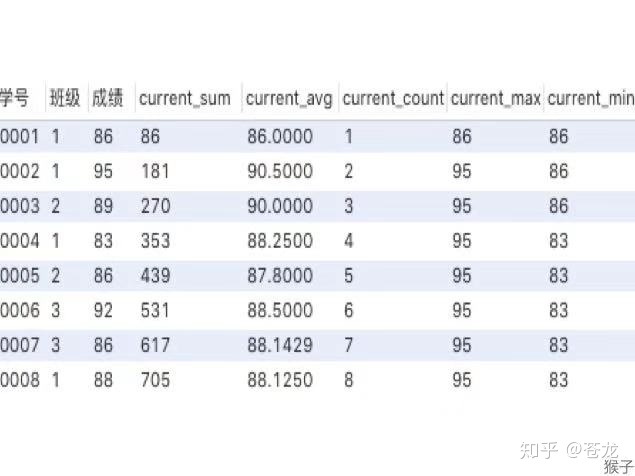
作用:聚合函数作为窗口函数,可以在每一行的数据里直观的看到,截止到本行数据,统计数据是多少(最大值,最小值)。同事可以看出每一行数,对整体统计数据的影响。
六、每组中比较
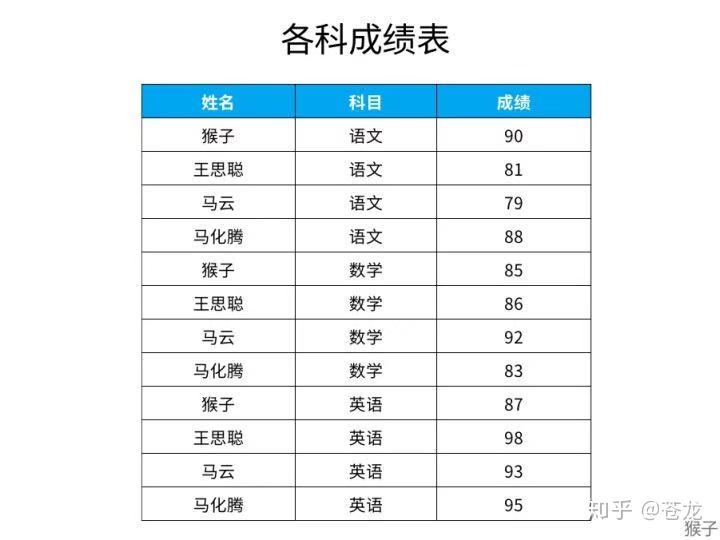
问题:查找单科成绩高于该科目平均成绩的学生名单
解题思路:
1.查找单科成绩高于该科目平均成绩,也就是在每个科目里比较。当每个出现的时候,就要想到分组。能实现负责功能的sql有两种,一是group by字句,另一个是窗口函数的partition by。
2.使用聚合窗口函数(求平均值avg),将每门课的平均成绩求出以后,然后找出大于比平均成绩的数据。要求分组后不能减少表的行数。
group by分组汇总后改变了表的行数,一行只有一个类别。而partition by和rank函数不会减少原表中的行数。
所以这里我们使用窗口函数的partition by
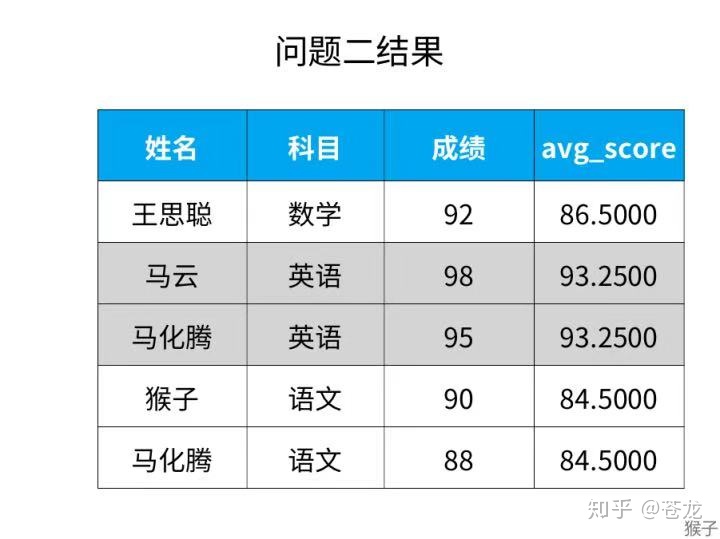
select * from(select *,avg (成绩)over (partition by 科目 )as avg_score from 成绩表) as a where 成绩>avg_score;
七、窗口函数的移动平均
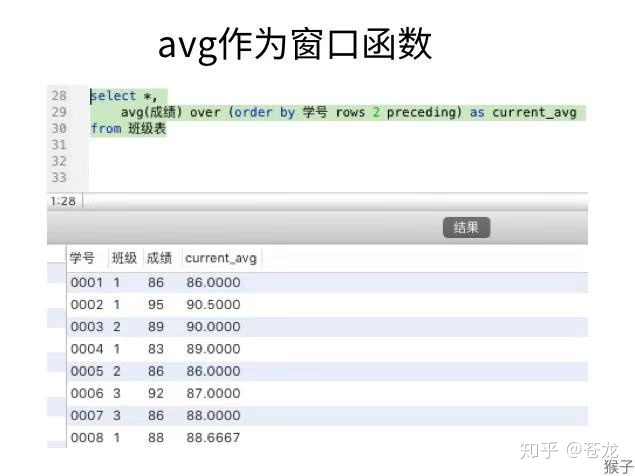
用了rows和preceding这两个关键字,是“之前...行”的意思,上面的句子中,是之前2行。也就是得到的结果是自身记录及前2行的平均。
例如:学号0004学生的current_avg,是自己和前2位同学的平均,即0002,0003,0004三位同学成绩的平均,其他数据的情况也一样,下图非常直观的可以看到计算过程:
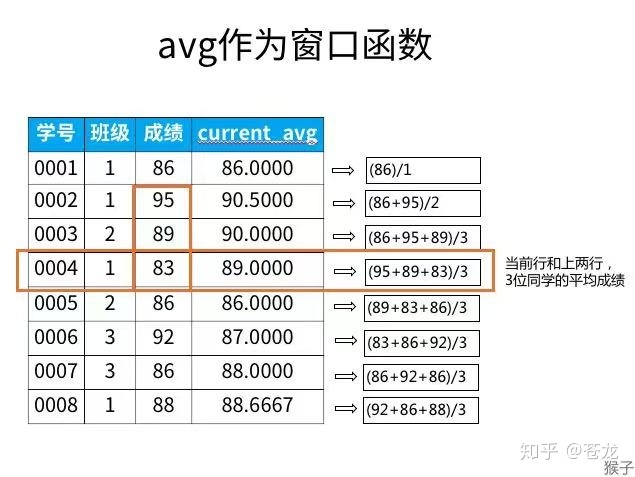
每一行得到的结果,都是当前行和前面2行的平均(共3行)。想要计算当前行与前n行(n+1)行的平均时,只要调整rows...preceding中间的数字即可。
作用:由于这里可以通过preceding关键字调整作用范围,在一下场景中非常适用:
在公司业绩名单排名中,可以通过移动平均,直接地查看到与相邻名次业绩的平均、求和等统计数据。
八、总结
1.注意事项
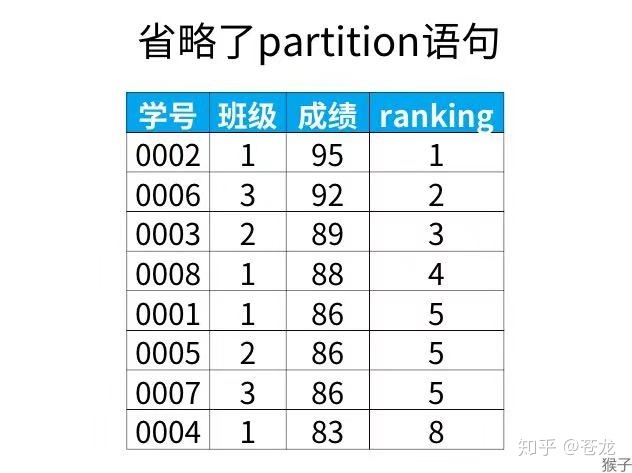
partition子句可是省略,省略就是不指定分组,结果如下,只是按成绩由高到低进行了排序:
select *,rank() over(order by 成绩 desc)as ranking from 班级表;
2.窗口函数语法
(窗口函数) over (partition by (用于分组的列名) order by (用于排序的列名))
(窗口函数)的位置,可以放以下两种函数:
1)专用窗口函数,比如:rank,dense_rank,row_number等
2)聚合函数,比如sum,avg,count,max,min等
3.窗口函数的功能
1)同时具有分组(partition by)和排序(order by)的功能
2)不减少原表的行数,所以经常用来在每组内排名
4.窗口函数使用场景
1)经典top N问题
找出每个部门排名前N的员工进行奖励
2)经典排名问题
业务需求“在每组内排名”,比如:每个部门按业绩来排名
3)在每个组里比较的问题
比如查找每个组里大于平均值的数据,可以有两种方法:
方法1,使用前面窗口函数案例来实现
方法2,使用关联子查询


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









