





1. 数据本地化的级别:
1.PROCESS_LOCAL
2.NODE_LOCAL
3.NO_PREF
4.RACK_LOCAL
5.ANY
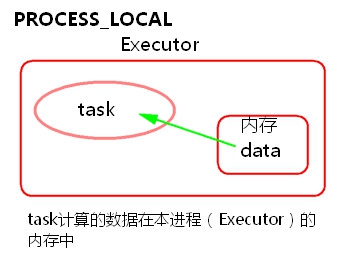
1) PROCESS_LOCAL
task要计算的数据在本进程(Executor)的内存中。
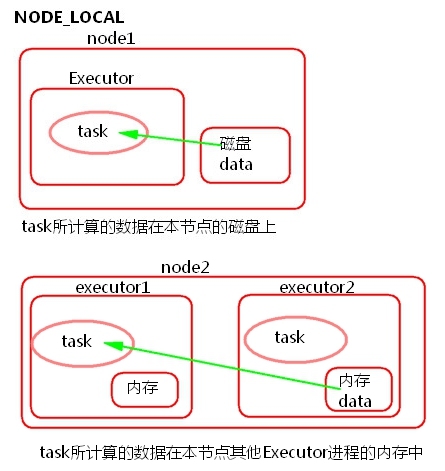
2) NODE_LOCAL
① task所计算的数据在本节点所在的磁盘上。
② task所计算的数据在本节点其他Executor进程的内存中。
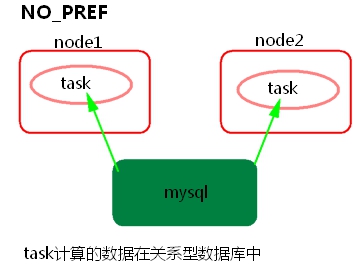
3) NO_PREF
task所计算的数据在关系型数据库中,如mysql。
4) RACK_LOCAL
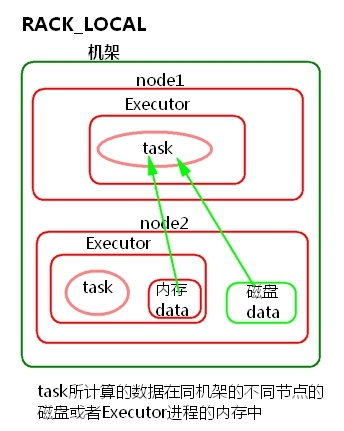
task所计算的数据在同机架的不同节点的磁盘或者Executor进程的内存中
5) ANY
跨机架。
2. Spark数据本地化调优:
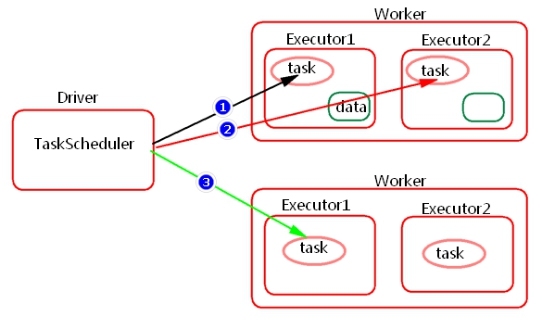
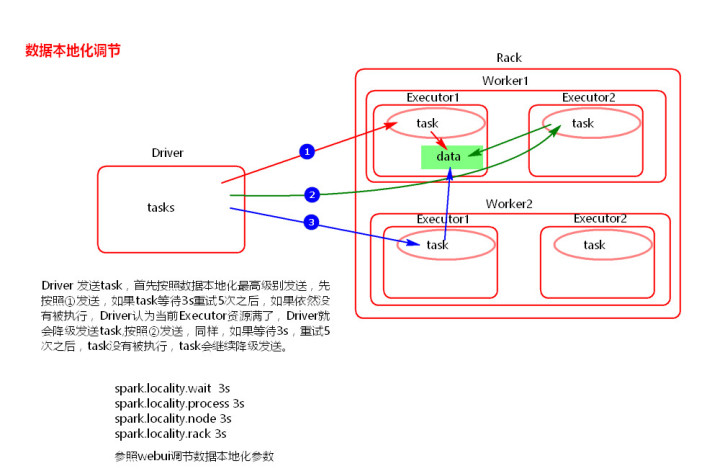
Spark中任务调度时,TaskScheduler在分发之前需要依据数据的位置来分发,最好将task分发到数据所在的节点上,如果TaskScheduler分发的task在默认3s依然无法执行的话,TaskScheduler会重新发送这个task到相同的Executor中去执行,会重试5次,如果依然无法执行,那么TaskScheduler会降低一级数据本地化的级别再次发送task。
如上图中,会先尝试1,PROCESS_LOCAL数据本地化级别,如果重试5次每次等待3s,会默认这个Executor计算资源满了,那么会降低一级数据本地化级别到2,NODE_LOCAL,如果还是重试5次每次等待3s还是失败,那么还是会降低一级数据本地化级别到3,RACK_LOCAL。这样数据就会有网络传输,降低了执行效率。
1) 如何提高数据本地化的级别?
可以增加每次发送task的等待时间(默认都是3s),将3s倍数调大, 结合WEBUI来调节,使任务平均分配,达到三种级别执行所花时间相差最少:
• spark.locality.wait (以下三个参数的默认值参照spark.locality.wait)
• spark.locality.wait.process
• spark.locality.wait.node
• spark.locality.wait.rack
注意:等待时间不能调大很大,调整数据本地化的级别不要本末倒置,虽然每一个task的本地化级别是最高了,但整个Application的执行时间反而加长。
2) 如何查看数据本地化的级别?
通过日志或者WEBUI
3. 内存调优
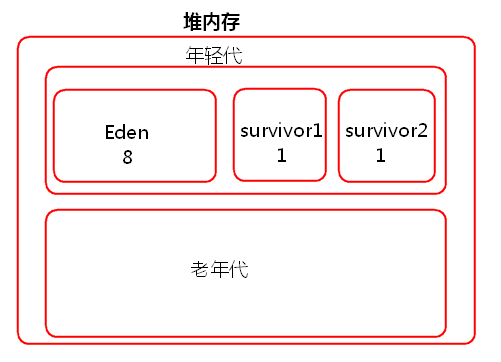
JVM堆内存分为一块较大的Eden和两块较小的Survivor,每次只使用Eden和其中一块Survivor,当回收时将Eden和Survivor中还存活着的对象一次性复制到另外一块Survivor上,最后清理掉Eden和刚才用过的Survivor。也就是说当task创建出来对象会首先往Eden和survivor1中存放,survivor2是空闲的,当Eden和survivor1区域放满以后就会触发minor gc小型垃圾回收,清理掉不再使用的对象。会将存活下来的对象放入survivor2中。
如果存活下来的对象大小大于survivor2的大小,那么JVM就会将多余的对象直接放入到老年代中。
如果这个时候年轻代的内存不是很大的话,就会经常的进行minor gc,频繁的minor gc会导致短时间内有些存活的对象(多次垃圾回收都没有回收掉,一直在用的又不能被释放,这种对象每经过一次minor gc都存活下来)频繁的倒来倒去,会导致这些短生命周期的对象(不一定长期使用)每进行一次垃圾回收就会长一岁。年龄过大,默认15岁,垃圾回收还是没有回收回去就会跑到老年代里面去了。
这样会导致在老年代中存放大量的短生命周期的对象,老年代应该存放的是数量比较少并且会长期使用的对象,比如数据库连接池对象。这样的话,老年代就会满溢(full gc 因为本来老年代中的对象很少,很少进行full gc 因此采取了不太复杂但是消耗性能和时间的垃圾回收算法)。不管minor gc 还是 full gc都会导致JVM的工作线程停止。
总结-堆内存不足造成的影响:
1) 频繁的minor gc。
2) 老年代中大量的短生命周期的对象会导致full gc。
3) gc 多了就会影响Spark的性能和运行的速度。
Spark JVM调优主要是降低gc时间,可以修改Executor内存的比例参数。
RDD缓存、task定义运行的算子函数,可能会创建很多对象,这样会占用大量的堆内存。堆内存满了之后会频繁的GC,如果GC还不能够满足内存的需要的话就会报OOM。比如一个task在运行的时候会创建N个对象,这些对象首先要放入到JVM年轻代中。比如在存数据的时候我们使用了foreach来将数据写入到内存,每条数据都会封装到一个对象中存入数据库中,那么有多少条数据就会在JVM中创建多少个对象。
Spark中如何内存调优?
Spark Executor堆内存中存放(以静态内存管理为例):RDD的缓存数据和广播变量(spark.storage.memoryFraction 0.6),shuffle聚合内存(spark.shuffle.memoryFraction 0.2),task的运行(0.2)那么如何调优呢?
1) 提高Executor总体内存的大小
2) 降低储存内存比例或者降低聚合内存比例
如何查看gc?
Spark WEBUI中job->stage->task















 2650
2650











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









