






简单介绍
本篇文章主要介绍数据挖掘里面的科学计算模块中 numpy。
通过这篇文章,咱们将一起学习
以下内容:
- numpy 是什么?
- 如何构建numpy?
- numpy 与list 相比他的优点是什么?
- numpy 的 操作
numpy的定义:
numpy是一个科学计算包,能够提供强大的多为矩阵运算,内部用C写的。简单的一句话,里面的核心是矩阵运算,矩阵很容易做并行运算,这是他速度特别快的原因之一。
构建numpy:
1.构建一维度的
import numpy as np
a = np.array([1,2,3])
2.构建多维度的
a = np.array([1,2,3],[4,5,6])3.numpy生成正态分布数据
np.random.randn(2,2)out: array([[-1.3720004 , -0.08225269], [-0.9075861 , 0.10122909]])
4. 从1,3 输出10个数字,均匀分割
a = np.linespace(1,3,10)Output : [ 1. 1.22222222 1.44444444 1.66666667 1.88888889 2.11111111 2.33333333 2.55555556 2.77777778 3. ]
numpy VS List
货比三家才知道好不好,就跟我在xgboost当中和gdbt pk一样 , 现在我们就让 numpy与 python中广为人知list 一较高下。
先说结论
- 占用较少的内存
- 速度快 :在较大的数据集上 接近10倍的速度
- 方便
我们先看如何占用内存的故事
import numpy as np
import sys
import time
S= range(80000)
print(sys.getsizeof(5)*len(S))
D= np.arange(80000)
print(D.size*D.itemsize)out:
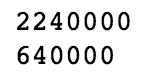
如果我们输入8万个数字进去,一共相差3.5倍左右,所以下次你看别人用pandas或者list 存储的时候,你是不是可以鄙视它。当然要看情况而定,有时候有些东西不适合numpy存储。
我们再看时间缩减和简单运算的的故事:
SIZE = 8000000
L1= range(SIZE)
L2= range(SIZE)
A1= np.arange(SIZE)
A2=np.arange(SIZE)
start= time.time()
result=[(x,y) for x,y in zip(L1,L2)]
print((time.time()-start)*1000)
start=time.time()
result= A1+A2
print((time.time()-start)*1000)
同样是做加法,在numpy里面一个+ 就可以搞定 , 同时时间上接近差了两倍的时间。
总结一下,就是大家以在遇到矩阵运算的时候尽量用numpy来。
numpy的操作
numpy的操作有很多,大家用的时候可以官网上看一下,我只列一下比较常用的一些
- dtype :数据类型 ,这个很常用,因为数据挖掘对数字类型很敏感。
- itemsize the size of each element 每个元素字节的大小
- ndim 查看多少维度
- size 总的元素个数
- shape :形状
a = np.array([(8,9,10),(11,12,13)])
print(a.size,a.dtype,a.shape,a.ndim,a.itemsize)output : 6 int64 (2, 3) 2 8
- reshape :改变形状
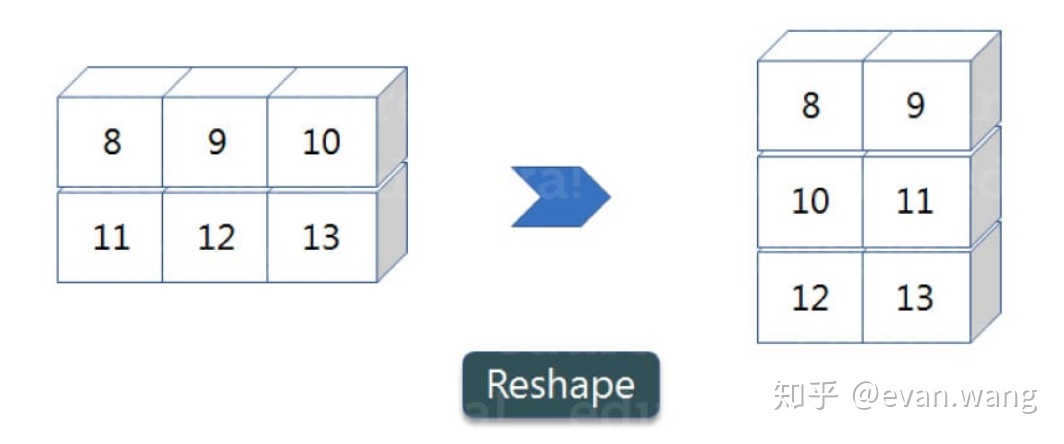
a = np.array([(8,9,10),(11,12,13)])
a.reshape((3,2))output : array([[ 8, 9], [10, 11], [12, 13]])
我们把两行三列的二维矩阵变成了 ,三行两列的二维矩阵。
- slice :切片 ,重要的操作,为什么重要,因为矩阵一般很大,我们没法全部看,此外我们有时候可能只对部分数据操作
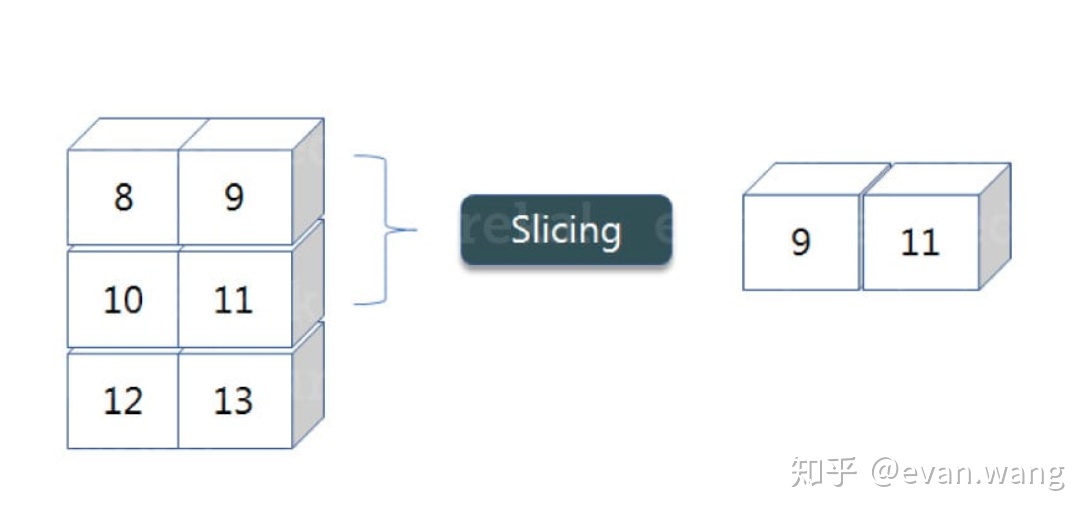
#a的第一行,第3列
a[0:,2]
Out : array([10, 13])
- min/max/sum ,矩阵最小,最大,求和
a = np.array([(8,9,10),(11,12,13)])
print(a.sum(),a.min(),a.max())out:63 8 13
- with axis 有时候我们只求某一行或者某一列的值的和,最大,最小
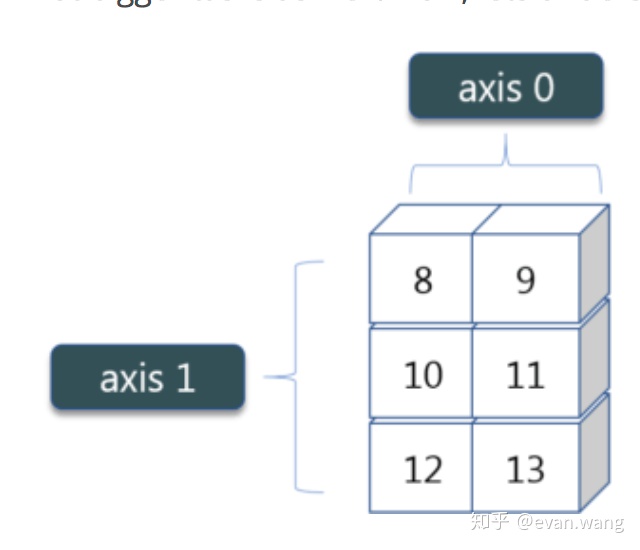
a.sum(axis=1)out:array([27, 36])
- std and sqrt 方差 和 开方
a= np.array([(1,2,3),(3,4,5)])
np.sqrt(a)out : array([[1. , 1.41421356, 1.73205081], [1.73205081, 2. , 2.23606798]])
np.std(a)out : 1.2909944487358056
- + - * / 就是对应元素的加减乘除
- Vertical & Horizontal Stacking
矩阵水平,或者垂直方向合并
x= np.array([(1,2,3),(3,4,5)])
y= np.array([(1,2,3),(3,4,5)])
np.vstack((x,y))
np.hstack((x,y))
#合并成一行
x.ravel()out:array([1, 2, 3, 3, 4, 5])
怎么判断两个矩阵是否完全一样
(data1==data2).all()
总结:
numpy是一个经常用的东西,但是我们对它有多快和有多减少内存没有具体的量化,今天的例子估计是内存可以节约3.5倍左右,速度大概是2倍左右,当时这是简单的计算,当你的数据越大,计算越复杂,他的效用就会越高。
至于后面的操作你在实践中慢慢熟悉吧,可能我写的好一点,今天的目的就是告诉咱们能用numpy就不要用pandas,list等。
好了,如果改变了大家计算用numpy而不用list的观念,给我点个赞,给我点个赞,给我点个赞,重要事说三遍,然后可以收藏一下哦。小熊猫是专门干数据这一块的,今天numpy属于算法中的科学计算也属于数据操作模块。想了解其他可以看
evan.wang:小熊猫数据挖掘目录篇zhuanlan.zhihu.com














 1686
1686











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









