






HADOOP实战练习
引言:
昨天我讲解了如何从零搭建hadoop环境,那么这一篇文章讲解一下,如何通过项目或者实践来学习hadoop,接下来结合两个实例来讲解,主要通过实践的方式让大家对hadoop有想应的了解,先把它用起来,然后去深入研究它的理论意义。这样才能更快和更好的学习。
HADOOP实战练习一 hadoop 三个组件讲解 1.1 hdfs文件系统讲解 1.1.1 hdfs文件的写过程 1.1.2 hdfs文件的读过程 1.2 yarn 资源管理系统讲解 1.3 mapreduce运行机制讲解二 实例练习 2.1 WordCount 练习 2.2 代码运行最后的最后
一 hadoop 三个组件讲解
1.1 hdfs文件系统讲解
hdfs是yahoo提出的一个分布式文件存储的框架,在传统单机不能满足大数据量的高可靠存储时,yahoo和apache的工程师们设计了这一款开源文件系统。感兴趣的小伙伴可以拜读一下经典的论文(后台回复【hdfs】,即可获得该论文)。
hdfs主要的结构有namenode,secondaryNameNode,DataNode,CheckPointNode等。
1.1.1 hdfs文件的写过程
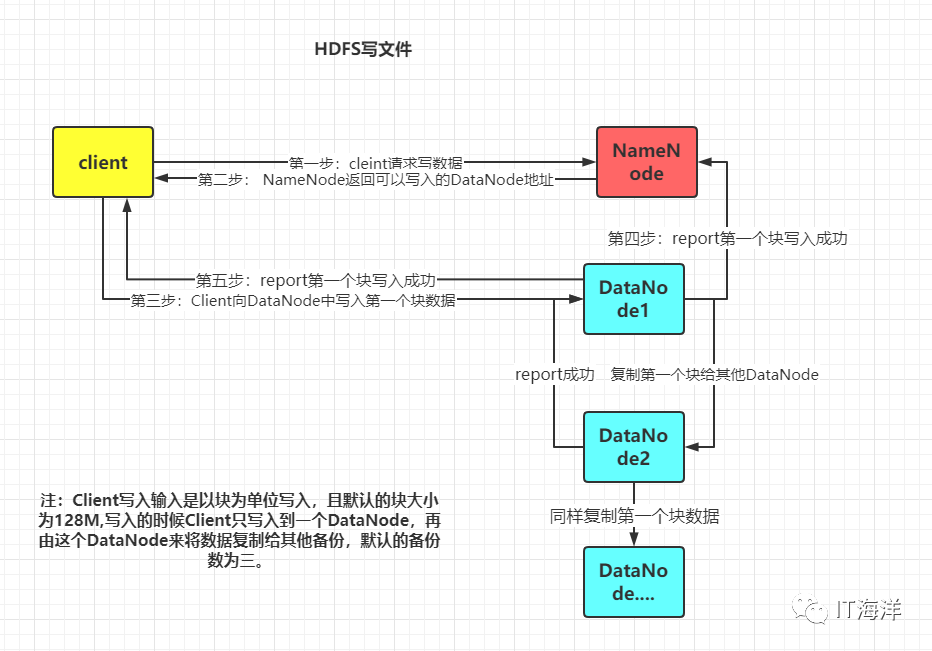
首先HDFS系统中的客户端会向NameNode请求相应的元数据(比如说即将分配给请求文件的DataNodes的地址),Client收到其数据后,就直接和DataNode取得联系,然后将文件分块写入到DataNode。可以结合一个博主画得好的动漫图来进一步理解一下。
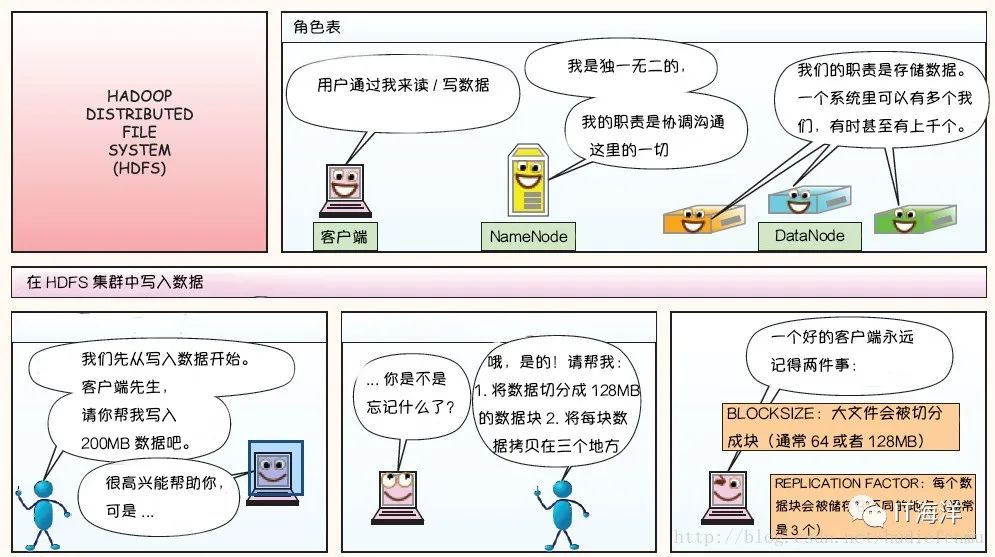
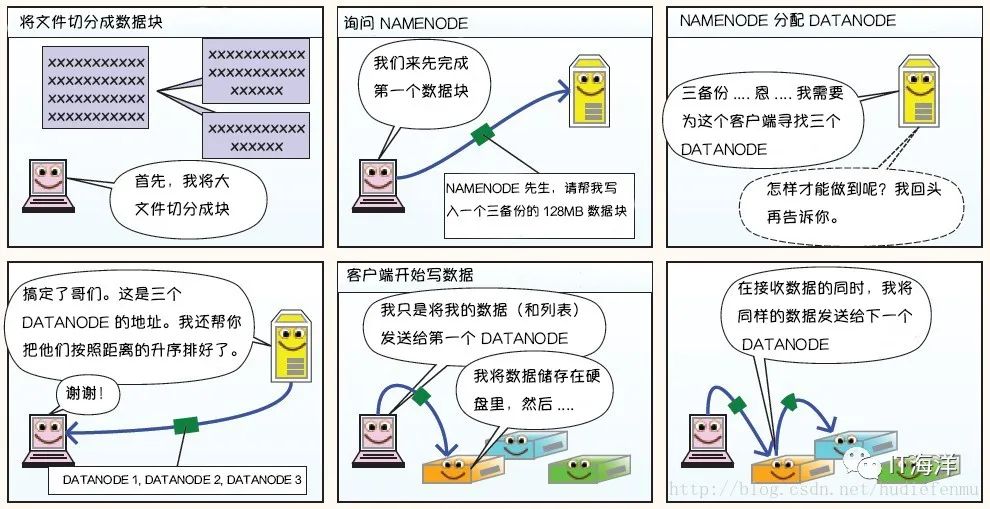
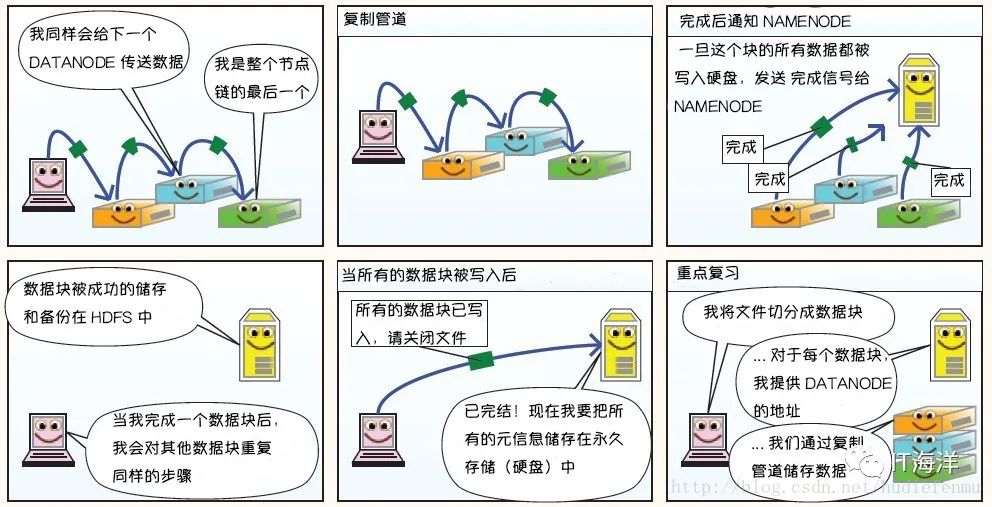
1.1.2 hdfs文件的读过程
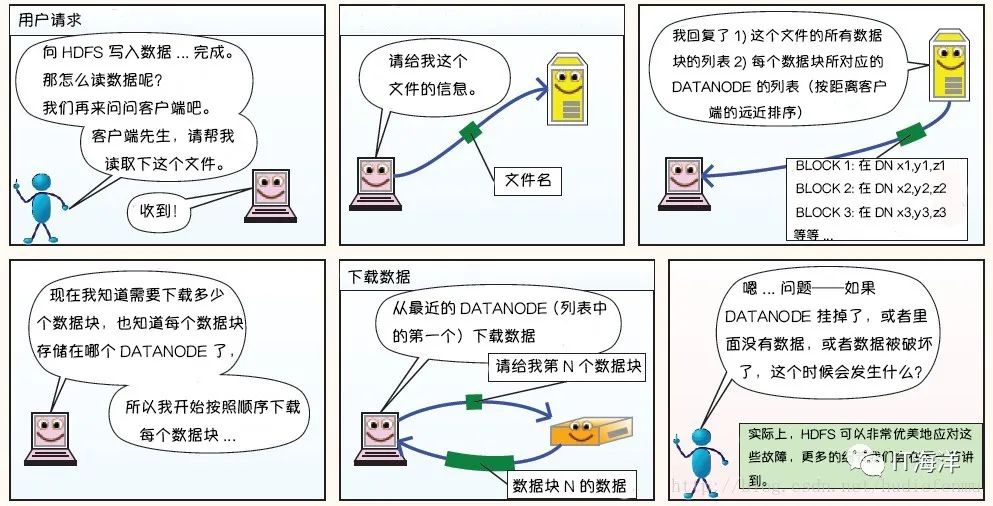
1.2 yarn 资源管理系统讲解
在hadoop早些版本没有引进yarn资源管理这层架构的时候,hadoop的性能是非常慢的,因为namenode既要管理磁盘的元数据,而在进行mapreduce的时候又要管理运行所需要的资源(比如说:磁盘空间,内存,cup等),而在引进yarn后每一层的司职就非常明显了,yarn将运行所需要的相关资源进行了一个虚拟化和规范性管理(规范性管理是事物发展到一定阶段必须要有的一个过程,类比其他领域也是这样的道理)。并且其他计算框架也能运行在yarn之上,例如spark等。下面就yarn得机制进行一个简单讲解,为下面的实操做个理论铺垫。
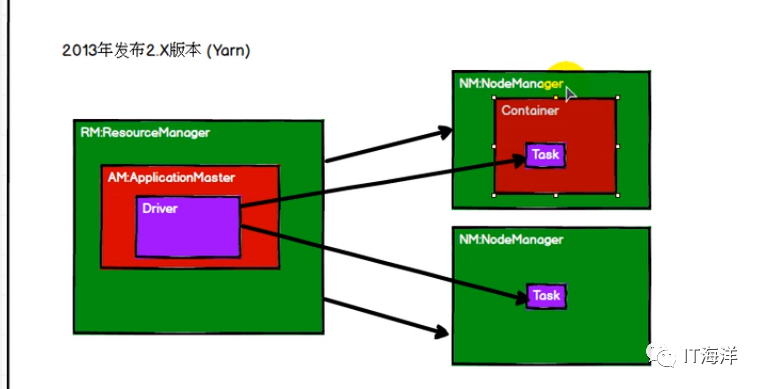
当客户端提交程序后,ResourceManager中的ApplicationMaster(就理解为一个java进程)会启动一个Driver的进程,Driver负责向AM(ApplicationMaster)申请本次代码运算所需要的资源数(cpu和内存等),ResourceManager然后根据Driver的申请分配相应的NodeManager中的Container给Driver用于计算,在yarn中引入了一个重要的容器化概念。资源分配的时候不再是整机分配,而是将整机虚拟成多个容器(Container)然后用于分配和计算Task。
1.3 mapreduce运行机制讲解
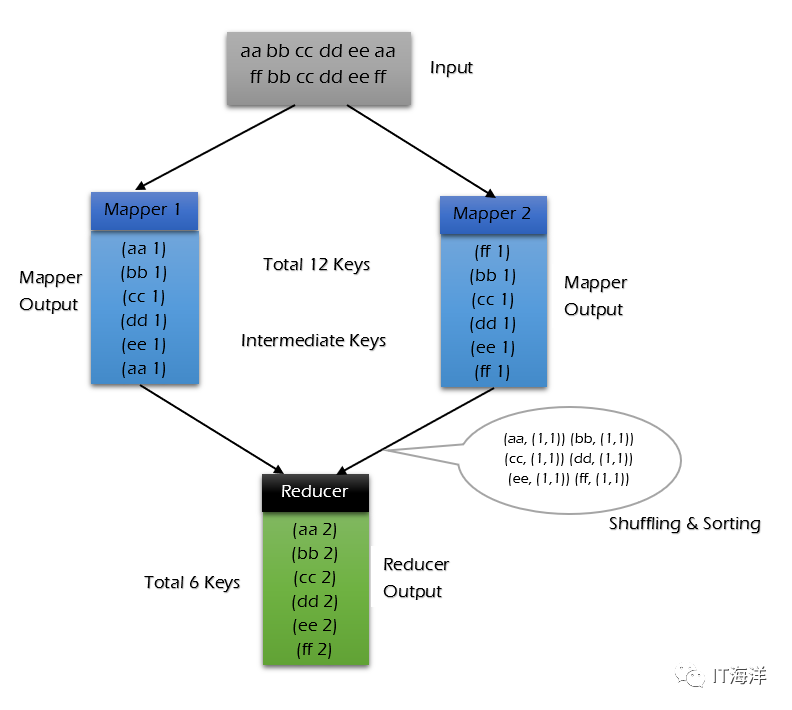
首先是一个input文件
然后在mapper阶段对输入文件的每一行调用map函数,并将结果传入reducer
reducer拿到map的结果后已经是经过shuffling的(也就是对相同键的数据进行了一个聚合生成一个(k,list)的键值对)
最后进行reduce操作,将结果保存。
二 实例练习
2.1 WordCount 练习
在编写hadoop程序时,用户只需要写三部分代码,一个是重写Map函数,一个是实现重写Reduce函数,一个是写Driver。本案例是实现一个词频统计,如果在google搜索系统中,要对一类文档做一个词频统计,如果数据量特别大的情况下,且不考虑实时性,那么mapreduce就是一个不错的选择。该案例的代码我已经放在github上了,后台回复【hadoop练习1】即可获得github链接。
首先是重写Map函数
//继承Mapper类,泛型传入的是map的输入和输出键值对类型。输入的建为文本中数据的第几行,值为每一行的内容public class WordCountMapper extends Mapper<LongWritable,Text,Text,IntWritable> { @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { //获取一行数据 String line=value.toString(); //分解为每个单词 String[] words=line.split(" "); //将每个单词的计数置为1 for(String word:words){ context.write(new Text(word),new IntWritable(1)); } }}然后重写Reduce函数:
//继承Reducer,同样泛型为输入和输出类型,shuffle会将map后相同的键进行一个类似于group by的操作,得到一个相同键,值为一个列表的kv对。public class WordCountReducer extends Reducer<Text,IntWritable,Text,IntWritable> { @Override protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { int temp=0; for(IntWritable count:values){ temp=temp+count.get(); } context.write(new Text(key),new IntWritable(temp)); }}最后Driver:
public class WordCountApp { private static final String HDFS_URL="hdfs://hadoop001:9000"; private static final String HADOOP_USR_NAME="root"; public static void main(String[] args){ //检查参数是否合法 if(args.length<2){ System.out.println("参数输入错误,请重新输入"); return; } //设置环境变量 Configuration configuration=new Configuration(); System.setProperty("HADOOP_USR_NAME",HADOOP_USR_NAME); configuration.set("fs.defualtFS",HDFS_URL); Job job=null; //通过上面的配置的configuration来创建一个Job try { job=Job.getInstance(configuration); } catch (IOException e) { e.printStackTrace(); } //设置job执行的主类 job.setJarByClass(WordCountApp.class); //设置mapper和reducer及其输入类型 job.setMapperClass(WordCountMapper.class); job.setReducerClass(WordCountReducer.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(IntWritable.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); //输出文件是否存在 FileSystem fileSystem=null; try { fileSystem= FileSystem.get(new URI(HDFS_URL),configuration,HADOOP_USR_NAME); } catch (IOException e) { e.printStackTrace(); } catch (InterruptedException e) { e.printStackTrace(); } catch (URISyntaxException e) { e.printStackTrace(); } //配置输入和输出路径 Path outputpath=new Path(args[1]); Path intputpath=new Path(args[0]); try { if(fileSystem.exists(outputpath)){ fileSystem.delete(outputpath,true); } } catch (IOException e) { e.printStackTrace(); } //设置输入和输入文件名 try { FileInputFormat.setInputPaths(job,intputpath); } catch (IOException e) { e.printStackTrace(); } FileOutputFormat.setOutputPath(job,outputpath); //提交作业 boolean result=false; try { result=job.waitForCompletion(true); } catch (IOException e) { e.printStackTrace(); } catch (InterruptedException e) { e.printStackTrace(); } catch (ClassNotFoundException e) { e.printStackTrace(); } //决定是否返回 System.exit(result?0:-1); }}2.2 代码运行
首先当然是从github上下载代码(记得fork+star哦)
接下来是打包,在实际开发中,可以在本机配置 hadoop 开发环境,直接在 IDE 中启动进行测试。这里主要介绍一下打包提交到服务器运行。由于本项目没有使用除 Hadoop 外的第三方依赖,直接打包即可:
# mvn clean package使用以下命令提交作业:
#jar后面接的是运行的jar包路径(将jar包放到指定的目录下)#然后是jar包中main方法所在的类#最后两个参数是输入和输出文件路径hadoop jar /usr/appjar/hadoop-wordcount-1.0-SNAPSHOT.jar \WordCountApp \/wordcount/input.txt /wordcount/output/WordCountApp作业完成后查看 HDFS 上生成目录:
# 查看目录hadoop fs -ls /wordcount/output/WordCountApp# 查看统计结果hadoop fs -cat /wordcount/output/WordCountApp/part-r-00000最后的最后
码字不容易啊,如果对您有帮助,麻烦点赞+关注。谢谢!!未来坏蛋哥会分享更多大数据相关知识,用项目实践的方式学习大数据。

参考文献:
github文档:https://github.com/heibaiying/BigData-Notes
经典漫画解说hdfs https://blog.csdn.net/hudiefenmu/article/details/37655491
Tom White . hadoop 权威指南 [M] . 清华大学出版社 . 2017.














 224
224











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









