






- | 作者:新一、
- | 简书:https://www.jianshu.com/u/b3263fc54bce
- | 知乎:https://www.zhihu.com/people/qing-ni-chi-you-zi-96
- | GitHub:https://github.com/JangYt?tab=repositories
- | 博客地址:https://blog.csdn.net/qq_41153943
我们在进行数据访问声明模板和repository之前都需要配置数据源用来连接数据库。数据源就是连接到数据库的一条路径,数据源中并无真正的数据,它仅仅记录的是你连接到哪个数据库,以及如何连接。常见的数据源有很多,比如dbcp,c3p0,druid。目前很多公司使用的是阿里巴巴开源的Druid数据源,因为该数据源不仅能够进行数据访问并且有成套的数据源以及安全监控。接下来就通过SpringBoot整合Druid数据源,并配置对数据源的监控。
首先需要新建一个springboot项目,这里需要的pom文件的配置如下:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.2.5.RELEASE</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>com.xinyi</groupId>
<artifactId>springboot-duriddemo</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>springboot-duriddemo</name>
<description>Demo project for Spring Boot</description>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
<java.version>1.8</java.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<scope>runtime</scope>
</dependency>
<!--引入druid数据源-->
<!-- https://mvnrepository.com/artifact/com.alibaba/druid -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.1.8</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<!--引入log4jlog4j-->
<!-- https://mvnrepository.com/artifact/log4j/log4j -->
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>接下来新建个yml配置文件,配置进行数据访问所需要的一些配置信息,下面的是整个的yml配置文件的配置信息:
spring:
datasource:
#用户名
username: root
#密码
password: 123456
#数据库的url
url: jdbc:mysql://localhost:3306/jdbc?serverTimezone=Asia/Shanghai
#驱动名称
driver-class-name: com.mysql.cj.jdbc.Driver
#对象的类型,这里是druid数据源
type: com.alibaba.druid.pool.DruidDataSource
#初始化连接数:默认值 0
initialSize: 5
#最小空闲连接数,默认值 0,当高峰期过后,连接使用的少了,但是连接池还是会为你留着minIdle的连接,以备高峰期再次来临的时候不需要创建连接当高峰期过后,连接使用的少了,但是连接池还是会为你留着minIdle的连接,以备高峰期再次来临的时候不需要创建连接
minIdle: 5
#最大活跃连接数,这个数字不宜设置过大,太多的并发连接对数据库的压力很大,甚至会导致雪崩,这是一定要注意的。但是如果设置过小,而应用的服务线程数有很高,可能会导致有的服务线程拿不到连接,所以服务的线程数和数据库连接数是需要经过配合调整的最大活跃连接数,这个数字不宜设置过大,太多的并发连接对数据库的压力很大,甚至会导致雪崩,这是一定要注意的。但是如果设置过小,而应用的服务线程数有很高,可能会导致有的服务线程拿不到连接,所以服务的线程数和数据库连接数是需要经过配合调整的
maxActive: 20
#最大等待毫秒数, 单位为 ms, 超过时间会出错误信息最大等待毫秒数, 单位为 ms, 超过时间会出错误信息
maxWait: 60000
#每过多少秒运行一次空闲连接回收器,这里设置的是30秒
timeBetweenEvictionRunsMillis: 30000
#连接池中的连接空闲多少时间后被回收,这里设置的是30分钟
minEvictableIdleTimeMillis: 1800000
# 验证使用的SQL语句
validationQuery: SELECT 1 FROM DUAL
#指明连接是否被空闲连接回收器(如果有)进行检验.如果检测失败,则连接将被从池中去除.
testWhileIdle: true
# 申请连接时执行validationQuery检测连接是否有效,做了这个配置会降低性能。
testOnBorrow: false
#归还连接时执行validationQuery检测连接是否有效,做了这个配置会降低性能
#testOnBorrow和testOnReturn在生产环境一般是不开启的,主要是性能考虑。失效连接主要通过testWhileIdle保证,如果获取到了不可用的数据库连接,一般由应用处理异常
testOnReturn: false
#是否缓存preparedStatement,即PSCache。PSCache对支持游标的数据库性能提升巨大
poolPreparedStatements: true
#最大启用PSCache的数量
maxPoolPreparedStatementPerConnectionSize: 20
# 配置监控统计拦截的filters,去掉后监控界面sql无法统计,'wall'用于防火墙
filters: stat,wall,log4j
# 合并多个DruidDataSource的监控数据
useGlobalDataSourceStat: true
#通过connectProperties属性来打开mergeSql功能;慢SQL记录
connectionProperties: druid.stat.mergeSql=true;druid.stat.slowSqlMillis=500新建一个Druid的配置类:
package com.xinyi.springboot.config;
import com.alibaba.druid.pool.DruidDataSource;
import com.alibaba.druid.support.http.StatViewServlet;
import com.alibaba.druid.support.http.WebStatFilter;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.boot.web.servlet.FilterRegistrationBean;
import org.springframework.boot.web.servlet.ServletRegistrationBean;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import javax.sql.DataSource;
import java.util.Arrays;
import java.util.HashMap;
import java.util.Map;
@Configuration
public class DruidConfig {
//获取yml配置文件的配置
@ConfigurationProperties(prefix = "spring.datasource")
//将druid数据源注入ioc容器
@Bean
public DataSource druid(){
return new DruidDataSource();
}
//配置Druid的监控
//1、配置管理后台的Servlet
@Bean
public ServletRegistrationBean DruidServlet(){
ServletRegistrationBean bean = new ServletRegistrationBean(new StatViewServlet(), "/druid/*");
Map<String,String> initParams = new HashMap<>();
//druid后台登录的用户名
initParams.put("loginUsername","admin");
//druid后台登录的密码
initParams.put("loginPassword","111111");
//默认就是允许所有访问
initParams.put("allow","");
bean.setInitParameters(initParams);
return bean;
}
//2、配置监控的filter
@Bean
public FilterRegistrationBean druidStatFilter(){
FilterRegistrationBean bean = new FilterRegistrationBean();
bean.setFilter(new WebStatFilter());
Map<String,String> initParams = new HashMap<>();
initParams.put("exclusions","*.js,*.css,/druid/*");
bean.setInitParameters(initParams);
bean.setUrlPatterns(Arrays.asList("/*"));
return bean;
}
}至此,可以启动项目,在浏览器的地址栏输入:
http://localhost:8080/druid/会跳转到Druid管理后台的登录页面,输入刚刚设置的用户名和密码登录管理后台,即可看到Druid 监控的相关信息:
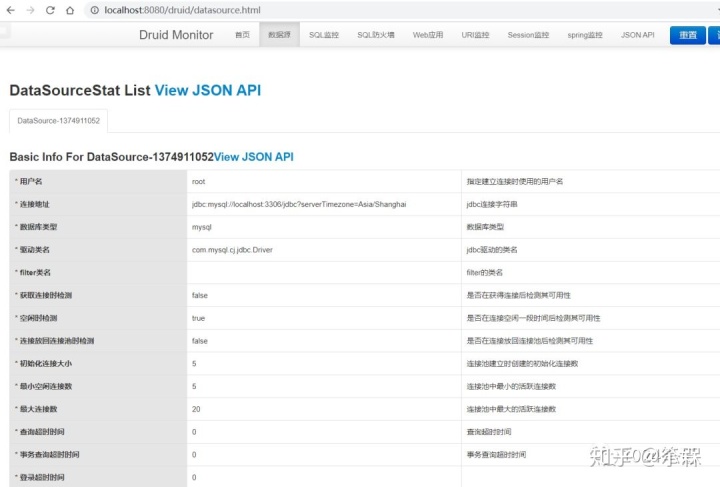
在数据库中新建一个表,并插入数据。

然后新建一个controller类,从数据库中查询数据:
package com.xinyi.springboot.controller;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.jdbc.core.JdbcTemplate;
import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.ResponseBody;
import java.util.List;
import java.util.Map;
@Controller
public class HelloController {
@Autowired
JdbcTemplate jdbcTemplate;
@ResponseBody
@GetMapping("/select")
public Map<String,Object> map(){
List<Map<String, Object>> list = jdbcTemplate.queryForList("select * FROM demo");
return list.get(0);
}
}重新启动SpringBoot项目,并登录Druid后台,可以看到在sql监控下的信息是空的:
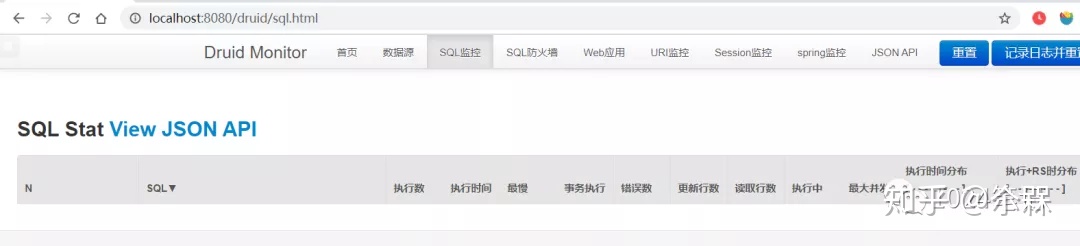
新建一个标签页,输入请求:
http://localhost:8080/select
在去监控后台的sql监控就可以发现已经监控到了刚刚请求中执行的sql语句:

以上就是如何通过SpringBoot整合Druid数据源以及配置数据源监控,当然Druid的使用不仅仅这些,还需要自己的不断的学习才能掌握更多的知识。本文原创首发于gzh【1024笔记】,我们一起学习,共同进步!














 1478
1478











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









