






1、概述
本教程将演示如何用Java高效地读取大文件。
2、在内存中读取
读取文件行的标准方式是在内存中读取,Guava 和Apache Commons IO都提供了如下所示快速读取文件行的方法:
Files.readLines(new File(path), Charsets.UTF_8); FileUtils.readLines(new File(path));这种方法带来的问题是文件的所有行都被存放在内存中,当文件足够大时很快就会导致程序抛出OutOfMemoryError 异常。
例如:读取一个大约1G的文件:
@Testpublic void givenUsingGuava_whenIteratingAFile_thenWorks() throws IOException { String path = ... Files.readLines(new File(path), Charsets.UTF_8);}这种方式开始时只占用很少的内存:(大约消耗了0Mb内存)
[main] INFO org.baeldung.java.CoreJavaIoUnitTest - Total Memory: 128 Mb[main] INFO org.baeldung.java.CoreJavaIoUnitTest - Free Memory: 116 Mb然而,当文件全部读到内存中后,我们最后可以看到(大约消耗了2GB内存):
[main] INFO org.baeldung.java.CoreJavaIoUnitTest - Total Memory: 2666 Mb[main] INFO org.baeldung.java.CoreJavaIoUnitTest - Free Memory: 490 Mb这意味这一过程大约耗费了2.1GB的内存——原因很简单:现在文件的所有行都被存储在内存中。
把文件所有的内容都放在内存中很快会耗尽可用内存——不论实际可用内存有多大,这点是显而易见的。
此外,我们通常不需要把文件的所有行一次性地放入内存中——相反,我们只需要遍历文件的每一行,然后做相应的处理,处理完之后把它扔掉。所以,这正是我们将要做的——通过行迭代,而不是把所有行都放在内存中。
3、文件流
现在让我们看下这种解决方案——我们将使用java.util.Scanner类扫描文件的内容,一行一行连续地读取:
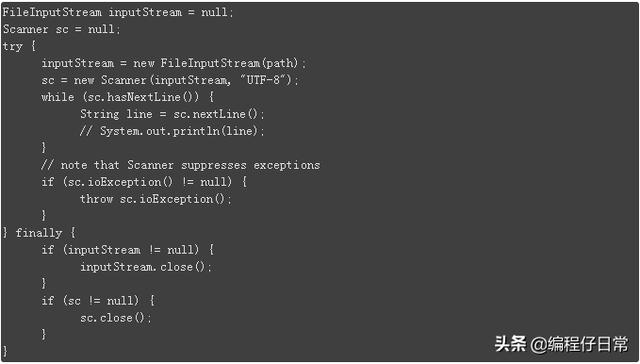
这种方案将会遍历文件中的所有行——允许对每一行进行处理,而不保持对它的引用。总之没有把它们存放在内存中:(大约消耗了150MB内存)
[main] INFO org.baeldung.java.CoreJavaIoUnitTest - Total Memory: 763 Mb[main] INFO org.baeldung.java.CoreJavaIoUnitTest - Free Memory: 605 Mb4、Apache Commons IO流
同样也可以使用Commons IO库实现,利用该库提供的自定义LineIterator:
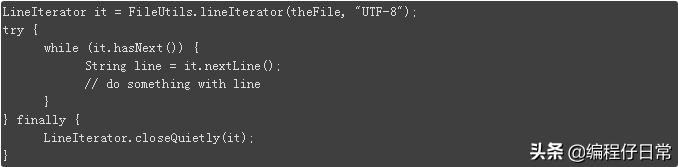
由于整个文件不是全部存放在内存中,这也就导致相当保守的内存消耗:(大约消耗了150MB内存)
[main] INFO o.b.java.CoreJavaIoIntegrationTest - Total Memory: 752 Mb[main] INFO o.b.java.CoreJavaIoIntegrationTest - Free Memory: 564 Mb5、结论
这篇短文介绍了如何在不重复读取与不耗尽内存的情况下处理大文件——这为大文件的处理提供了一个有用的解决办法。
文章来源:https://dwz.cn/kXwnf5wB作者:Java团长














 817
817











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









