







说明
这篇博客是我对《视觉SLAM十四讲》相关基础知识点的一个整理,没有详细的推导过程,仅仅相当于一个思维导图,同时在网上搜罗了一些相关的问题进行的补充总结,本人水平有限,如果文中有误,还请大家指出。
基础知识点
1. 特征提取、特征匹配
这是整个SLAM系统最开始的部分,先进行特征提取,然后进行特征匹配,通过匹配的特征点才求取的相关变换矩阵,这里容易搞混的概念是特征提取,特征提取是包括特征点和特征描述子,以ORB为例,ORB是由FAST特征点和BRIEF特征描述子构成。而我们通常所说的Harris角点通常仅仅指特征点,仅仅拥有Harris角点是无法进行特征匹配的,还需要通过向量对Harris角点进行特征描述(特征描述子),两帧之间才能进行特征的匹配。关于特征子的总结可以参看我的这篇总结博客 视觉SLAM总结——视觉特征子综述(总结得非常详细)
(1)Harris
Harris角点:如下图所示,通过一个小的滑动窗口在邻域检测角点在任意方向上移动窗口,若窗口内的灰度值都有剧烈的变化,则窗口的中心就是角点。转化为数学描述就是自相关矩阵两个特征值大小。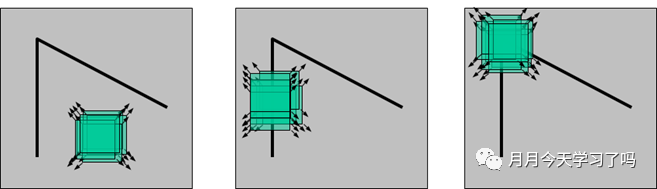 Harris特征描述子:Harris 角点的描述子通常是由周围图像像素块的灰度值,以及用于比较的归一化互相关矩阵构成的。图像的像素块由以该像素点为中心的周围矩形部分图像构成优点:计算简单;提取的点特征均匀且合理;稳定,稳定Harris算子对图像旋转、亮度变化、噪声影响和视点变换不敏感。缺点:对尺度很敏感,不具有尺度不变性;提取的角点精度是像素级的;需要设计角点匹配算法
Harris特征描述子:Harris 角点的描述子通常是由周围图像像素块的灰度值,以及用于比较的归一化互相关矩阵构成的。图像的像素块由以该像素点为中心的周围矩形部分图像构成优点:计算简单;提取的点特征均匀且合理;稳定,稳定Harris算子对图像旋转、亮度变化、噪声影响和视点变换不敏感。缺点:对尺度很敏感,不具有尺度不变性;提取的角点精度是像素级的;需要设计角点匹配算法
(2)SIFT
SIFT特征点:利用高斯金字塔和DOG函数进行特征点提取。高斯金字塔的当前层图像是对其前一层图像先进行高斯低通滤波,然后做隔行和隔列的降采样(去除偶数行与偶数列)而生成的。DoG (Difference of Gaussian)是高斯函数的差分,具体到图像处理来讲,就是将同一幅图像经过两个不同高斯滤波得到两幅滤波图像,将这两幅图像相减,得到DoG图。DOG图上的邻域梯度方向直方图峰值即特征点的主方向。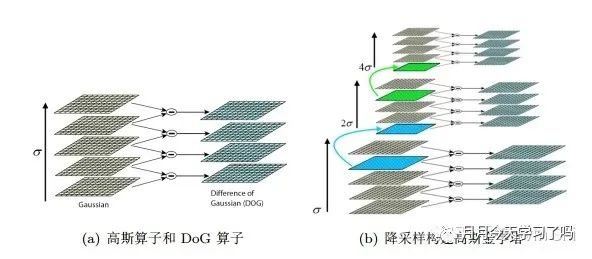 SIFT特征描述子:以特征点为中心取窗口,通过高斯加权增强特征点附近像素梯度方向信息的贡献,即在4 × 4的小块上计算梯度方向直方图( 取8个方向),计算梯度方向累加值,形成种子点,构成4× 4 × 8= 128维特征向量。然后进行统计。
SIFT特征描述子:以特征点为中心取窗口,通过高斯加权增强特征点附近像素梯度方向信息的贡献,即在4 × 4的小块上计算梯度方向直方图( 取8个方向),计算梯度方向累加值,形成种子点,构成4× 4 × 8= 128维特征向量。然后进行统计。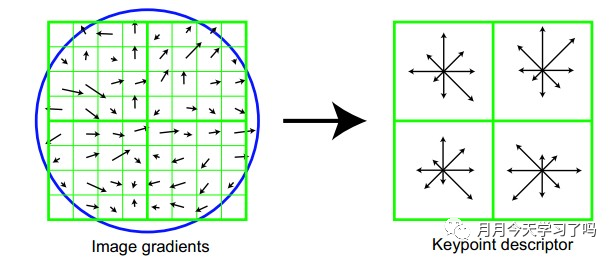 优点:SIFT特征对旋转、尺度缩放、亮度变化保持不变性,对视角变化、仿射变换、噪声也保持一定程度的稳定性。
优点:SIFT特征对旋转、尺度缩放、亮度变化保持不变性,对视角变化、仿射变换、噪声也保持一定程度的稳定性。
(3)SUFT
SUFT是对SIFT的改进,他们在思路上是一致的,只是采用的方法不同而已SUFT特征点:基于Hessian矩阵构造金字塔尺度空间,利用箱式滤波器(box filter)简化二维高斯滤波SUFT特征描述子:通过Haar小波特征设定特征点主方向,这样构建的特征描述子就是64维的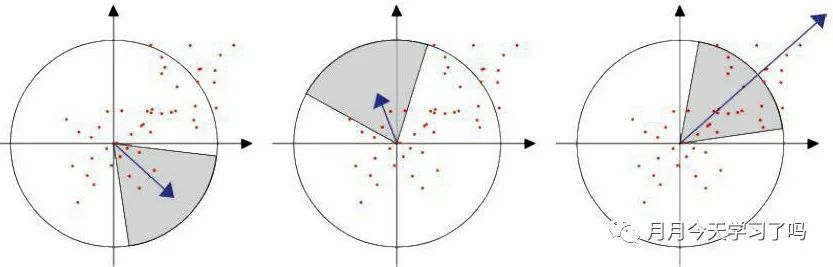 缺点:在求主方向阶段太过于依赖局部区域像素的梯度方向;图像金字塔的层取得不足够紧密也会使得尺度有误差
缺点:在求主方向阶段太过于依赖局部区域像素的梯度方向;图像金字塔的层取得不足够紧密也会使得尺度有误差
(4)ORB
Fast角点:如果某个像素与周围领域内足够多的像素相差较大,则该像素有可能为角点。直接的阈值判断来加速角点提取简单高效。 BRIEF特征描述子:BRIEF算法计算出来的是一个二进制串的特征描述符。它是在一个特征点的邻域内,选择n对像素点pi、qi(i=1,2,…,n)。然后比较每个点对的灰度值的大小。如果I(pi)> I(qi),则生成二进制串中的1,否则为0。所有的点对都进行比较,则生成长度为n的二进制串。优点:ORB算法的速度大约是SIFT的100倍,是SURF的10倍。
BRIEF特征描述子:BRIEF算法计算出来的是一个二进制串的特征描述符。它是在一个特征点的邻域内,选择n对像素点pi、qi(i=1,2,…,n)。然后比较每个点对的灰度值的大小。如果I(pi)> I(qi),则生成二进制串中的1,否则为0。所有的点对都进行比较,则生成长度为n的二进制串。优点:ORB算法的速度大约是SIFT的100倍,是SURF的10倍。
以上参考 https://zhuanlan.zhihu.com/p/36382429
(5)特征匹配
特征匹配的方法有很多,就不在这里一一赘述,包括暴力匹配(Brute-Force Macher)、近似最近邻(FLANN)等,ORB SLAM2中采用词典加速匹配过程。
2. 2D-2D:对极约束、基础矩阵、本质矩阵、单应矩阵
3. 3D-2D:PnP
PnP是求解3D到2D点对运动的方法,即问题描述为,我们的已知条件是n个3D空间点以及它们作为特征点的位置(以归一化平面齐次坐标表示),我们求解的是相机的位姿R , t R,tR,t,如果3D空间点的位置是世界坐标系的位置,那么这个R , t R,tR,t也是世界坐标系下的。特征点的3D位置可以通过三角化或者RGBD相机的深度图确定。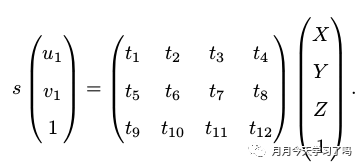
(1)直接线性变换方法
根据推导,一对特征点(一个3D点加一个2D点)可以提供两个线性约束,因此12维的齐次变换矩阵需要6对特征点。
(2)P3P方法
P3P的作用是将利用三对特征点,讲空间点在世界坐标系下的坐标,转换到像极坐标系中的坐标,将PnP问题转化为ICP问题,推导过程是利用三角形特征完成的。
(3)Bundle Adjustment方法
其本质是一个最小化重投影误差的问题,公式如下: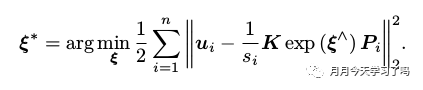
即理解为调整相机的位姿使得重投影误差变小,而最小的重投影误差就对应着实际的位姿。需要求这里要注意的是这里仅仅是采用了BA的方法,但是实际做BA优化的时候,是同时优化位姿和路点位置,因此有两个相关的雅克比矩阵,但这里仅仅优化位姿,因此所求的雅克比矩阵仅仅和位姿有关,可以直接求取J JJ如下,然后就可以进行求解δ ξ \delta \xiδξ进行迭代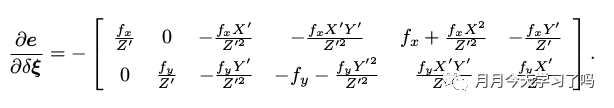
4. 3D-3D:ICP
其本质就是确定两个点集之间的匹配关系。
(1)SVD方法
其问题构建为: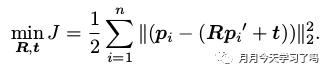
求解过程是先对每个点进行去质心坐标,然后根据优化问题计算旋转矩阵R RR(这里会用到SVD),最后求t tt
(2)非线性优化方法
其问题构建为: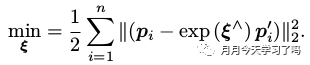
这里的推导和PnP的类似,即求位姿导数。
5. 直接法和光流法
(1)光流法
光流法的基本假设是灰度不变假设,即同一个空间点的像素灰度值,在各个图像中是固定不变的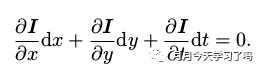
在LK光流中假设某一窗口内的像素具有相同的运动,因此w × w w×ww×w大小的窗口内有w 2 w^2w2个像素,即构成w 2 w^2w2个方程,然后构成关于d x d t \frac{dx}{dt}dtdx,d y d t \frac{dy}{dt}dtdy的超定线性方程,求其最小二乘解。LK光流是得到特征点之间的对应关系,如同描述子的匹配,之后还是需要通过对极几何、PnP等求解相机位姿。
(2)直接法
直接法之所以称为直接法是因为它是直接获得相机位姿,而不需要通过匹配、求解矩阵等过程,直接法的思路是根据当前相机的位姿估计值,来寻找 p 2 p_2p2 的位置。但若相机位姿不够好, p 2 p_2p2的外观和p 1 p_1p1会有明显差别, 然后通过优化光度误差来优化相机位姿。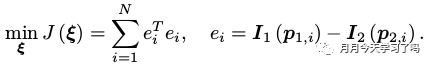
非常快的框架SVO就是结合了直接法和特征点法,SVO采用的是提取稀疏特征点(类似特征点法),帧间VO用图像对齐(类似于直接法)。
直接法的缺点:1. 非凸性;2. 单个像素没有区分度;3. 灰度值不变是很强的假设
6. Bundle Adjustment
我后来对后端进行了一个非常全面的总结,参考博客视觉SLAM总结——后端总结
首先注意目标函数如下:
示该函数对路标点位置的偏导数。因此在非线性优化过程中获得的H HH矩阵为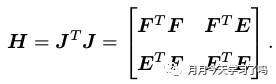
H矩阵最重要的一个特性就是它的稀疏性,其中左上角和右下角为对角阵且一般左上角较小右下角较大。左下角和右上角可能稀疏也可能稠密,矩阵的非对角线上的非零矩阵块,表示了该处对应的两个相机变量之间存在着共同观测的路标点,有时候称为共视(Co-visibility)。其对应关系如下: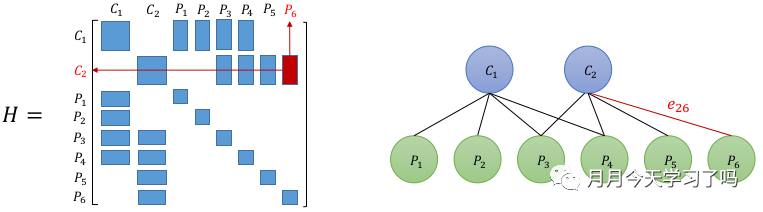
回环检测
这一部分之前并没有花很多时间去研究,主要是知道目前SLAM中用的比较多的方法是词袋模型,词袋模型中涉及到字典的生成和使用的问题,这一部分和机器学习的只是挂钩比较深。
字典的生成问题就是非监督聚类问题,可以采用K-means对特征点进行聚类,然后通过K叉树进行表达,相似度判断采用是TD-IDF的方法。














 444
444











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









