





欢迎访问本人的CSDN博客【Together_CZ】,我是沂水寒城。
https://yishuihancheng.blog.csdn.net
在大数据处理领域里面,Hadoop和spark可以说是最广为流传的两个神器,随着计算力的不断发展和数据量的急剧扩大,当前愈来愈呈现一种以Hadoop为基础存储以spark为核心计算的体系模式。

spark同样也提供了对于python的支撑,我们可以通过pip的安装方式来安装pyspark模块从而完成与spark的交互,关于Hadoop和spark这一套环境的搭建的工作在我的博客里面都有涉及,如果需要这方面的详细介绍的朋友可以留言,我后续会发文出来进行介绍。
今天的分享内容主要还是基于pyspark完成一些基础的计算工作,主要是对经常使用到的两种数据库MySQL和SQLServer的交互操作进行介绍,如果抛开pysaprk不谈,单纯基于python来操作这两种数据库本身没有什么难度,在我的系列博客里面都有详细的文章,同样如果需要的话可以前去浏览或者给我留言,我后续再头条发文出来。
基于pyspark来对数据库进行操作是很重要也是很基础的一环,为了简化整个操作过程,我对MySQL和SQLServer数据的操作都封装成为了一个单独的函数,可以直接拿去使用的,下面是我的具体实现,非常简单,只要细心点就好了:
首先是pyspark操作MySQL数据库,实现如下:
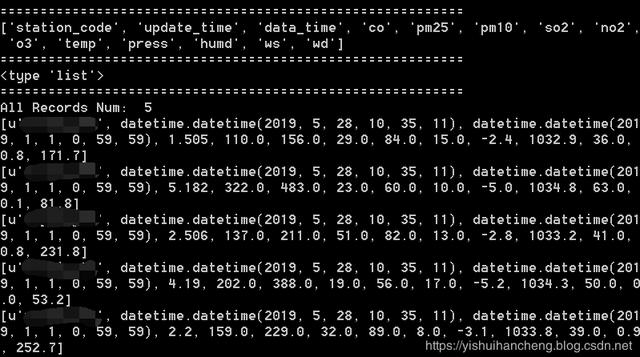
def mysqlDataRead(table='table'): ''' 读取 MySQL 数据库内容 ''' sqlContext=SQLContext(sc) url='jdbc:mysql://'+mysql['host']+':'+str(mysql['port'])+'/'+mysql['db']+'?'+'user='+mysql['user']+'&password='+mysql['passwd'] df=sqlContext.read.format("jdbc").options(url=url,dbtable=table).load() print '==========================================================' df.show() all_columns=df.columns print '==========================================================' print all_columns res_list=df.collect() print '==========================================================' print type(res_list) print '==========================================================' result=splitRowData(all_columns,res_list) for one in result[:10]: print one sc.stop() return result在使用上述代码的时候,只需要修改对应的数据库连接字段的信息就好了,简单测试结果输出如下:
table='(SELECT * FROM myTable LIMIT 5) T'mysqlDataRead(table=table)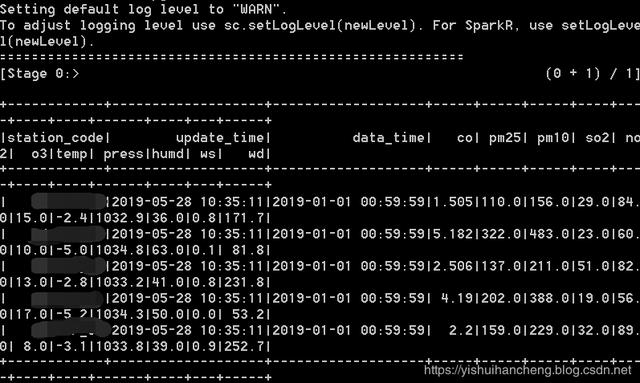
接下来是pyspark操作SQLServer数据,具体的实现如下:
def sqlServerDataRead(table='TableName'): ''' 读取 SQLServer 数据库内容 ''' url='jdbc:sqlserver://'+sqlserver['host']+':'+str(sqlserver['port'])+';DatabaseName='+sqlserver['database']+';'+'username='+sqlserver['user']+';password='+sqlserver['password'] sqlContext=SQLContext(sc) df=sqlContext.read.format("jdbc").options(url=url,dbtable=table).load() print '==========================================================' df.show() all_columns=df.columns print '==========================================================' print all_columns res_list=df.collect() print '==========================================================' print type(res_list) print '==========================================================' result=splitRowData(all_columns,res_list) for one in result[:10]: print one sc.stop() return result在使用上述代码的时候,只需要修改对应的数据库连接字段的信息就好了,简单测试结果输出如下:
table='(select top 5 * from myTable) tmp'sqlServerDataRead(table=table)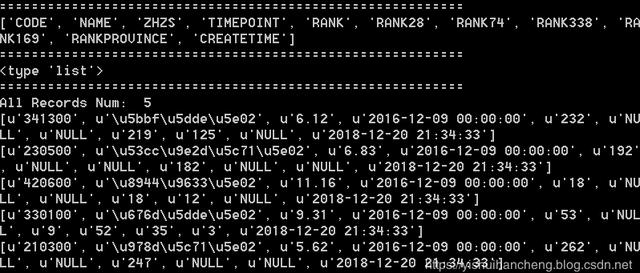
该函数的使用说明同MySQL数据库函数的调用,都是只需要将我代码里面的数据库连接字段修改为自己的数据库连接配置信息就好了。
欢迎交流!















 1231
1231











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









