





关于描述分析
在数据分析之前,一般要对数据进行一些描述性的工作,通过操作SPSS的一些操作可以得出一些描述性统计量,比如均值、方差、标准差,全距等等,在这里还可以同时将原始分数转化为Z分数,生成Z分数的新变量。
通过这些描述性统计量我们可以对数据有一个具体、大概的了解。
下面通过一组数据实例来讲解。
1.打开数据文件“20180206”
2.菜单栏中选择【分析】→【描述统计】→【描述】
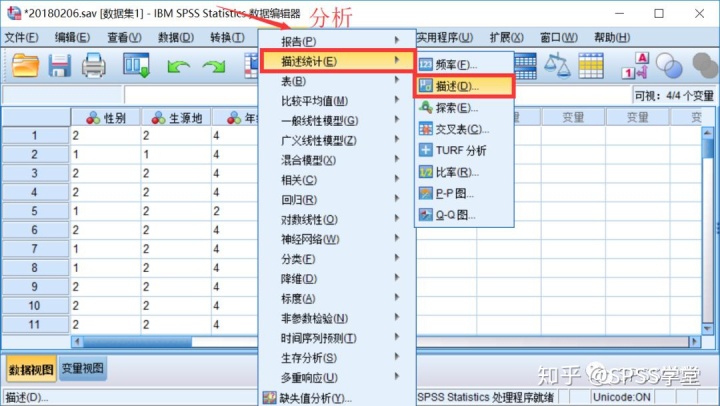
图1.
3.打开【描述】对话框,将“情绪智力”送入【变量】框
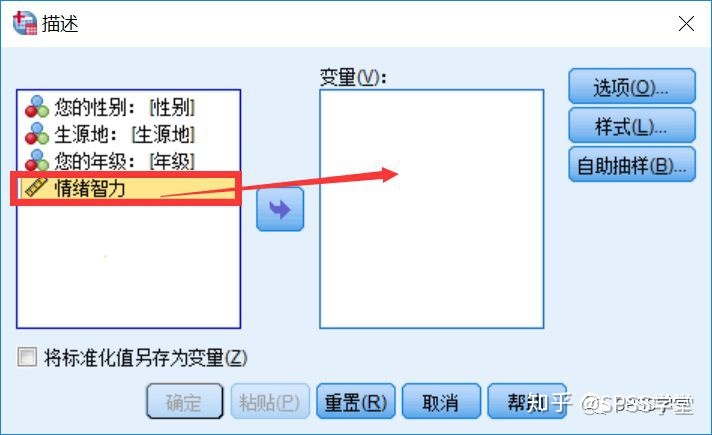
图2-1.
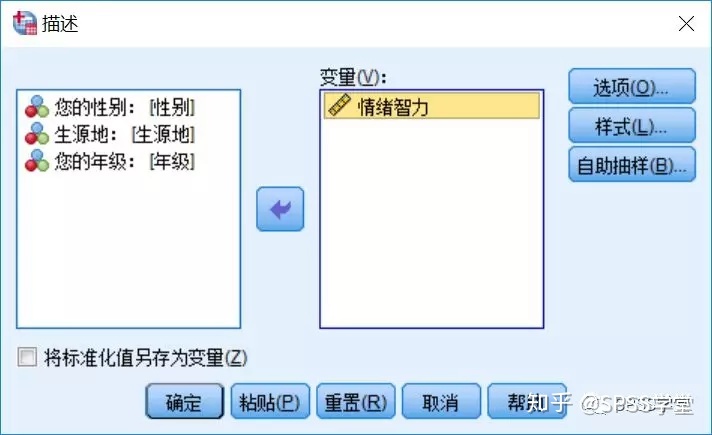
图2-2.
4.送入变量框后,点击【选项】标签,弹出【描述“选项】
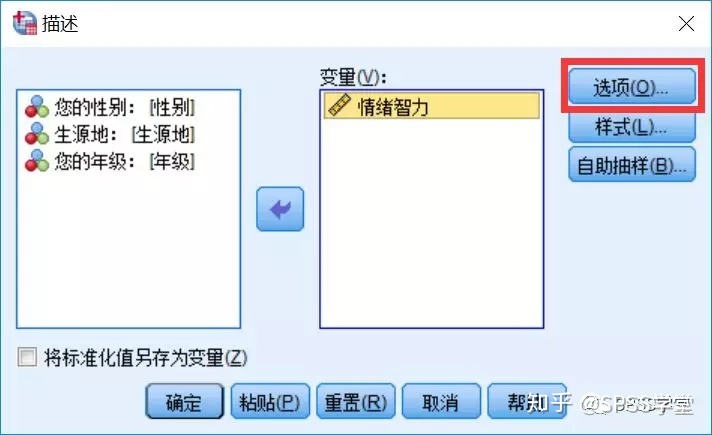
图3-1.
图3-2.
5.SPSS通常默认选项为”平均值“、”标准差“、”最大值“以及”最小值“。点击【继续】
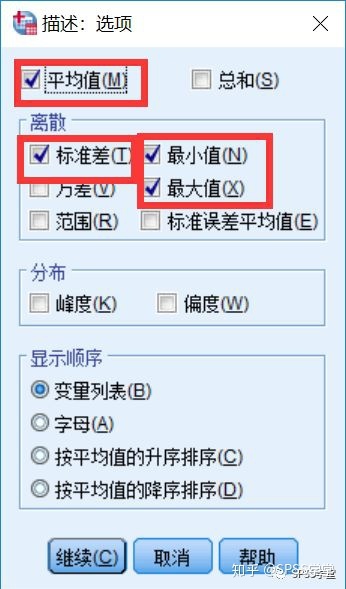
图4-1.
7.返回【描述】对话框。此时注意左下角有一个”将标准化值另存为变量“,勾选这个选项就可以将原始分数转化为Z分数并生成新变量。然后再点击【确定】
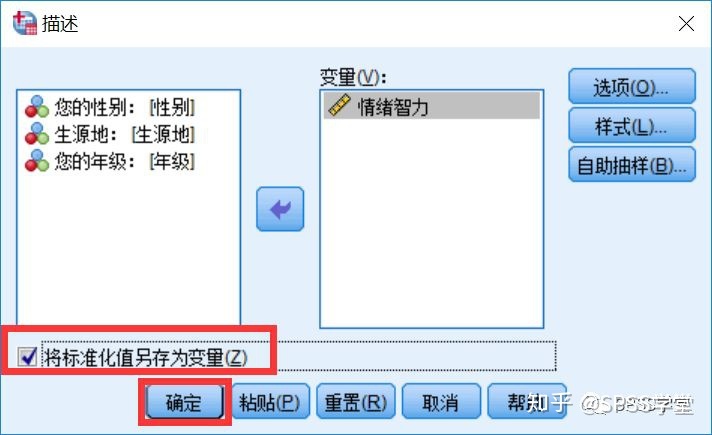
图4-2.
8.返回”查看器“查看结果
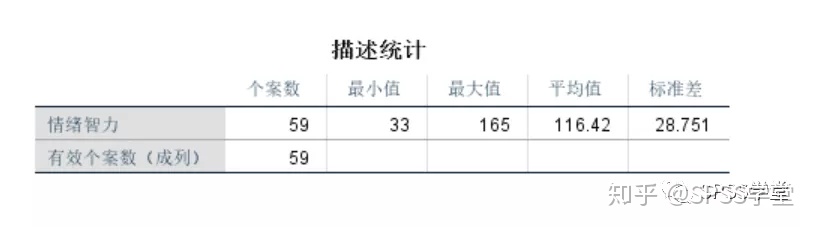
从结果中,可以得知,该样本的最大值为156,最小值为165,平均数为116.42,标准差为28.751.该样本的数值之间幅度还是挺大的。
9.返回”变量视图“可以发现新增的Z分数的变量”Z情绪智力“
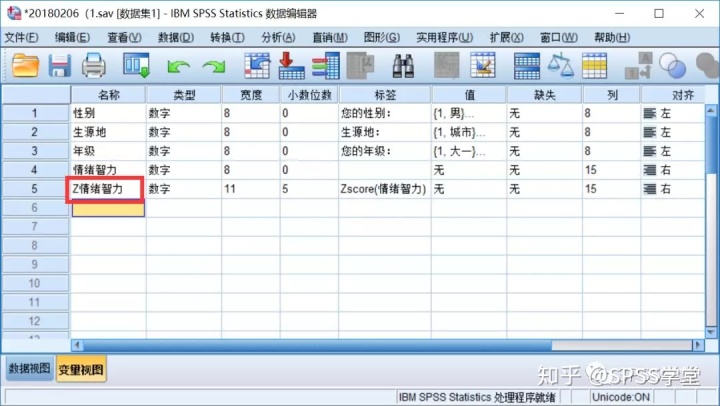
图5.
附后:描述统计量介绍
平均值:表示集中趋势的统计量,在这里是指常用的算数平均值。
总和:是计算变量的总和,需要注意的是这个总和不是计算个案的总和
方差:是表示离散趋势的统计量,是指各个数据与平均数之差的平方的平均数,从方差中可以了解数据变化的幅度。
标准差:是方差的开根号,也是表示数据的离散程度
最大值:样本数据中的最大值
最小值:样本数据中的最小值
范围:又称全距,是样本数据中最大值到最小值的差值
标准误差平均值:在其他版本的SPSS中也有写做”平均值的标准误差“,这个统计量是指样本均值的标准差,标准误用来衡量抽样误差,误差越小,表明样本统计量与总体参数越接近,样本越有代表性。
峰度:是指样本频率分布曲线与正态分布相比较。当值等于3则是正态分布,小于3尖峰分布,大于3平峰分布。
偏度:是对分布偏斜方向及程度的预测,值为正数,则为右偏态;值为负数,则为左偏态
在 SPSS学堂 中输入“20180206”即可获得操作数据,多多练习~















 754
754











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









