





使用AllenNLP的童鞋一定很头疼一件事情,那就是config.json的格式应该如何去书写。我们总是不经意间会多加一行或者少一个逗号,这样在解json文件或者初始化我们的模型都会遇到bug。
这里就总结一下,json文件书写的格式,希望对大家有所帮助。
首先,我们应该知道我们能够配置的参数有哪些?下图将会告诉大家我们可以配置的参数~
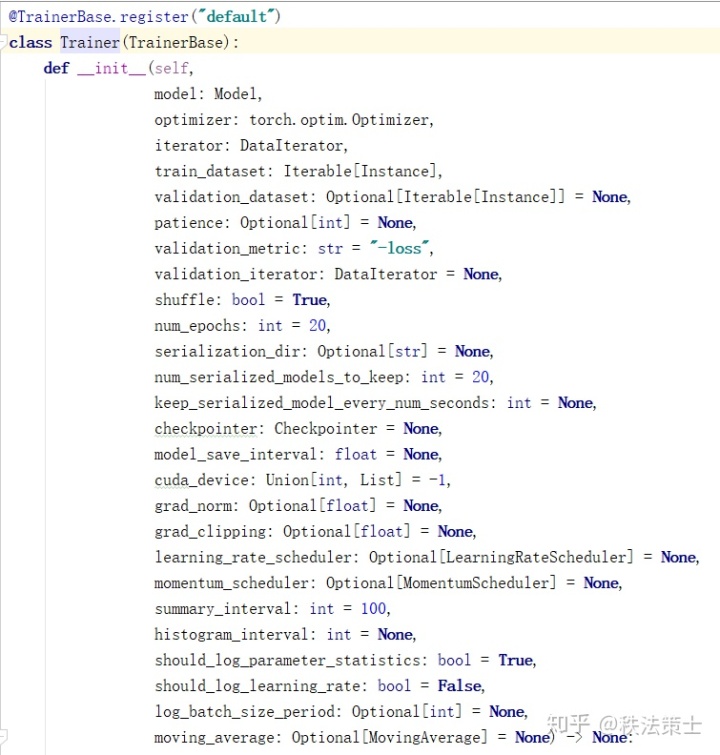





至于常用的module,这里列举几个:






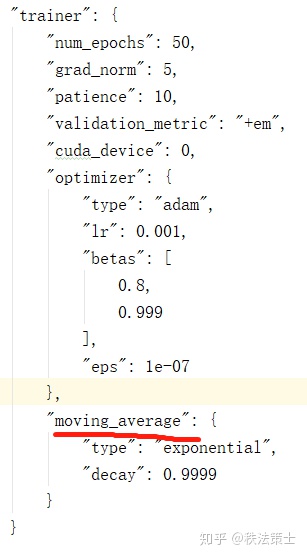
感觉常用的配置就这些,如果大家对其他配置感兴趣可以留言或私信,我看看我会不会,会的话再补上~














 163
163











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









