






RDD依赖关系为成两种:窄依赖(Narrow Dependency)、宽依赖(Shuffle Dependency)。窄依赖表示每个父RDD中的Partition最多被子RDD的一个Partition所使用;宽依赖表示一个父RDD的Partition都会被多个子RDD的Partition所使用。
一、窄依赖解析
RDD的窄依赖(Narrow Dependency)是RDD中最常见的依赖关系,用来表示每一个父RDD中的Partition最多被子RDD的一个Partition所使用,如下图所示,父RDD有2~3个Partition,每一个分区都只对应子RDD的一个Partition(join with inputs co-partitioned:对数据进行基于相同Key的数值相加)。
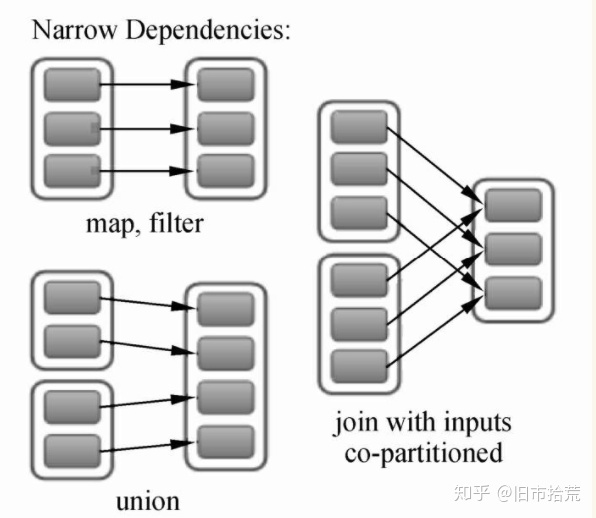
窄依赖分为两类:第一类是一对一的依赖关系,在Spark中用OneToOneDependency来表示父RDD与子RDD的依赖关系是一对一的依赖关系,如map、filter、join with inputs co-partitioned;第二类是范围依赖关系,在Spark中用RangeDependency表示,表示父RDD与子RDD的一对一的范围内依赖关系,如union。OneToOneDependency依赖关系的Dependency.scala的源码如下。
/**
OneToOneDependency的getParents重写方法引入了参数partitionId,而在具体的方法中也使用了这个参数,这表明子RDD在使用getParents方法的时候,查询的是相同partitionId的内容。也就是说,子RDD仅仅依赖父RDD中相同partitionID的Partition。
Spark窄依赖中第二种依赖关系是RangeDependency。Dependency.scala的RangeDependency的源码如下。
/**
RangeDependency和OneToOneDependency最大的区别是实现方法中出现了outStart、length、instart,子RDD在通过getParents方法查询对应的Partition时,会根据这个partitionId减去插入时的开始ID,再加上它在父RDD中的位置ID,换而言之,就是将父RDD中的Partition,根据partitionId的顺序依次插入到子RDD中。
分析完Spark中的源码,下边通过两个例子来讲解从实例角度去看RDD窄依赖输出的结果。对于OneToOneDependency,采用map操作进行实验,实验代码和结果如下所示。
val 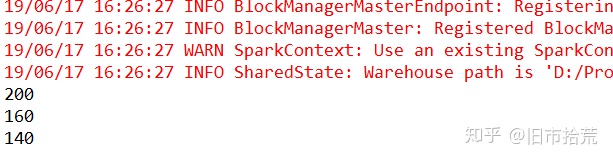
对于RangeDependency,采用union操作进行实验,实验代码和结果如下所示。
val 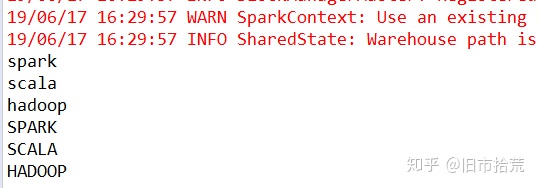
二、宽依赖解析
RDD的宽依赖(Shuffle Dependency)是一种会导致计算时产生Shuffle操作的RDD操作,用来表示一个父RDD的Partition都会被多个子RDD的Partition使用,如下图中groupByKey算子操作所示,父RDD有3个Partition,每个Partition中的数据会被子RDD中的两个Partition使用。
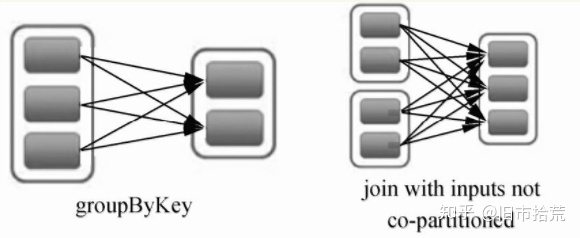
宽依赖的源码位于Dependency.scala文件的ShuffleDependency方法中,newShuffleId()产生了新的shuffleId,表明宽依赖过程需要涉及shuffle操作,后续的代码表示宽依赖进行时的shuffle操作需要向shuffleManager注册信息。Dependency.scala的ShuffleDependency的源码如下。
@DeveloperApi
Spark中宽依赖关系非常常见,其中较经典的操作为GroupByKey(将输入的key-value类型的数据进行分组,对相同key的value值进行合并,生成一个tuple2),具体代码和操作结果如下所示。输入5个tuple2类型的数据,通过运行产生3个tuple2数据。
val 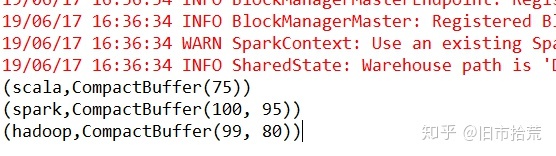
三、DAG生成的机制
在图论中,如果一个有向图无法从任意顶点出发经过若干条边回到该点,则这个图是一个有向无环图(DAG图)。而在Spark中,由于计算过程很多时候会有先后顺序,受制于某些任务必须比另一些任务较早执行的限制,我们必须对任务进行排队,形成一个队列的任务集合,这个队列的任务集合就是DAG图,每一个定点就是一个任务,每一条边代表一种限制约束(Spark中的依赖关系)。
通过DAG,Spark可以对计算的流程进行优化,对于数据处理,可以将在单一节点上进行的计算操作进行合并,并且计算中间数据通过内存进行高效读写,对于数据处理,需要涉及Shuffle操作的步骤划分Stage,从而使计算资源的利用更加高效和合理,减少计算资源的等待过程,减少计算中间数据读写产生的时间浪费(基于内存的高效读写)。
Spark中DAG生成过程的重点是对Stage的划分,其划分的依据是RDD的依赖关系,对于不同的依赖关系,高层调度器会进行不同的处理。对于窄依赖,RDD之间的数据不需要进行Shuffle,多个数据处理可以在同一台机器的内存中完成,所以窄依赖在Spark中被划分为同一个Stage;对于宽依赖,由于Shuffle的存在,必须等到父RDD的Shuffle处理完成后,才能开始接下来的计算,所以会在此处进行Stage的切分。
在Spark中,DAG生成的流程关键在于回溯,在程序提交后,高层调度器将所有的RDD看成是一个Stage,然后对此Stage进行从后往前的回溯,遇到Shuffle就断开,遇到窄依赖,则归并到同一个Stage。等到所有的步骤回溯完成,便生成一个DAG图。
DAG生成的相关源码位于Spark的DAGScheduler.scala。getParentStages获取或创建一个给定RDD的父Stages列表,getParentStages调用了getShuffleMapStage,,getShuffleMapStage调用了getAncestorShuffleDependencies,getAncestorShuffleDependencies返回给定RDD的父节点中直接的Shuffle依赖。DAGScheduler.scala的getParentStages的源码如下。
/**
DAGScheduler.scala的getShuffleMapStage的源码如下。
/**
DAGScheduler.scala的getAncestorShuffleDependencies的源码如下。
/** Find ancestor shuffle dependencies that are not registered in shuffleToMapStage yet */
四、DAG逻辑视图解析
下面通过一个简单计数案例讲解DAG具体的生成流程和关系。示例代码如下。
val 

具体解释为:在程序正式运行前,Spark的DAG调度器会将整个流程设定为一个Stage,此Stage包含3个操作,5个RDD,分别为MapPartitionRDD(读取文件数据时)、MapPartitionRDD(flatMap操作)、MapPartitionRDD(map操作)、MapPartitionRDD(reduceByKey的local段的操作)、ShuffleRDD(reduceByKeyshuffle操作)。
(1)回溯整个流程,在shuffleRDD与MapPartitionRDD(reduceByKey的local段的操作)中存在shuffle操作,整个RDD先在此切开,形成两个Stage。
(2)继续向前回溯,MapPartitionRDD(reduceByKey的local段的操作)与MapPartitionRDD (map操作)中间不存在Shuffle(即两个RDD的依赖关系为窄依赖),归为同一个Stage。
(3)继续回溯,发现往前的所有的RDD之间都不存在Shuffle,应归为同一个Stage。
(4)回溯完成,形成DAG,由两个Stage构成:
第一个Stage由MapPartitionRDD(读取文件数据时)、MapPartitionRDD(flatMap操作)、MapPartitionRDD(map操作)、MapPartitionRDD(reduceByKey的local段的操作)构成。第二个Stage由ShuffleRDD(reduceByKey Shuffle操作)构成。















 184
184











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









