






代码有解释,可能一开始看不到,更着动手多敲几遍就能掌握了。加油。
"""
目标:写一段程序,从无序链表中移除重复项
例如:
输入-> 1->0->3->1->4->5->1->8
输出-> 1->0->3->4->5->8
"""
先定义好链表结构
# -*- coding: utf-8 -*-
方法一:顺序删除
主要思路为:通过双重循环直接在链表上进行删除操作。外层循环用一个指针从第一个结点开始遍历整个链表,然后内层循环用另外一个指针遍历其余结点,将与外层循环遍历到的指针所指结点的数据域相同的结点删除。如下图所示: .
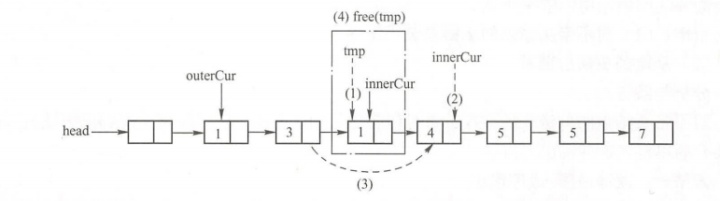
假设外层循环从outerCur开始遍历,当内层循环指针innerCur 遍历到上图实线所示的位置(outerCur.data= =innerCur.data)时,需要把innerCur指向的结点删除。具体步骤如下:
(1)用tmp记录待删除的结点的地址。
(2)为了能够在删除tmp结点后继续遍历链表中其余的结点,使innerCur指向它的后继结点: innerCur=zinnerCur.next。
(3)从链表中删除tmp结点。
实现代码如下:
def 算法性能分析:
由于这种方法采用风重循环对链表进行遍历,因此,时间复杂度为
方法二:递归法
主要思路为:对于结点cur,首先递归地删除以cur.next为首的子链表中重复的结点,接着从以cur.next为首的子链表中找出与cur有着相同数据域的结点并删除,实现代码如下:
def 算法性能分析:
这种方法与方法一类似,从本质上而言,由于这种方法需要对链表进行双重遍历,因此,时间复杂度为
方法三:空间换时间
通常情况下,为了降低时间复杂度,往往在条件允许的情况下,通过使用辅助空间来实现。具体而言,主要思路为: .
(1)建立一个HashSet, HashSet 中的内容为已经遍历过的结点内容,并将其初始化为空。
(2)从头开始遍历链表中的所有结点,存在以下两种可能性: .
1)如果结点内容已经在HashSet中,那么删除此结点,继续向后遍历。
2)如果结点内容不在HashSet中,那么保留此结点,将此结点内容添加到HashSet中,继续向后遍历。
核心思想:建一个辅助栈记录链表数据项,遍历链表,
1、如果当前结点的数据项在辅助栈中,则删除该结点
2、如果当前结点数据项不在辅助栈中,则该结点数据项进行入栈操作
3、继续遍历,直至遍历结束。
辅助栈可选数据类型:元祖,列表,字典,集合
其中字典和集合的查找时间复杂度为O(1),字典内部是有哈希表(哈希函数+哈希冲突表)构成,故查找时间复杂度为O(1),
Python里集合的内部实现是字典,故查找时间复杂度也为O(1)。
- 时间复杂度:O(N)
- 空间复杂度:O(N)
def 测试代码:
if 参考:
《python程序员宝典》














 685
685











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









