





除了最初发表的thor过滤器和HttpCatcher网球规则讲解的教程,以及初学者入门点这里,内容太过于巨细靡遗,主要是为了给入门朋友详解thor和网球这两个工具使用上的相关的基本流程,但造成的就是文章内容的冗余繁杂,所以之后所有文章唯有对于实例的重点讲解,主要在于培养大家对于一些关键数据的敏锐感知,逐渐加深对于thor过滤器或者HttpCatcher网球规则在个人自用调试方法上的了解以及学会正则表达式。
目前公众号一般会每次交替发布thor过滤器规则调试教程以及苹果官方免费的捷径制作教程。
捷径教程讲解一云手机短信验证码接受平台的聚合捷径教程讲解—系统照片基础功能细讲捷径教程讲解—系统勿扰模式的多种情境元素细讲捷径教程—三种“变量”的用法详分细解捷径教程—结合thor过滤器讲解捷径识图的实现以及“如果”的事
捷径教程—"共享表单"、"重复"、"如果"等元素的讲解
捷径教程讲解—"列表"、"词典"的不同运用&健康饮水的规划
捷径教程讲解—“Base64编码”的运用
捷径教程--结合thor过滤器讲解链接爬数据的实现以及API接口的事
捷径教程--结合thor关于API开放接口的运用实例讲解
捷径教程实例讲解--键与值的自定义&关于版权&
捷径讲解教程--通过查阅开发者文档来写捷径
捷径教程讲解-- 实例讲解文本的引用,仿Mac版微信的消息引用回复
放不下了………………
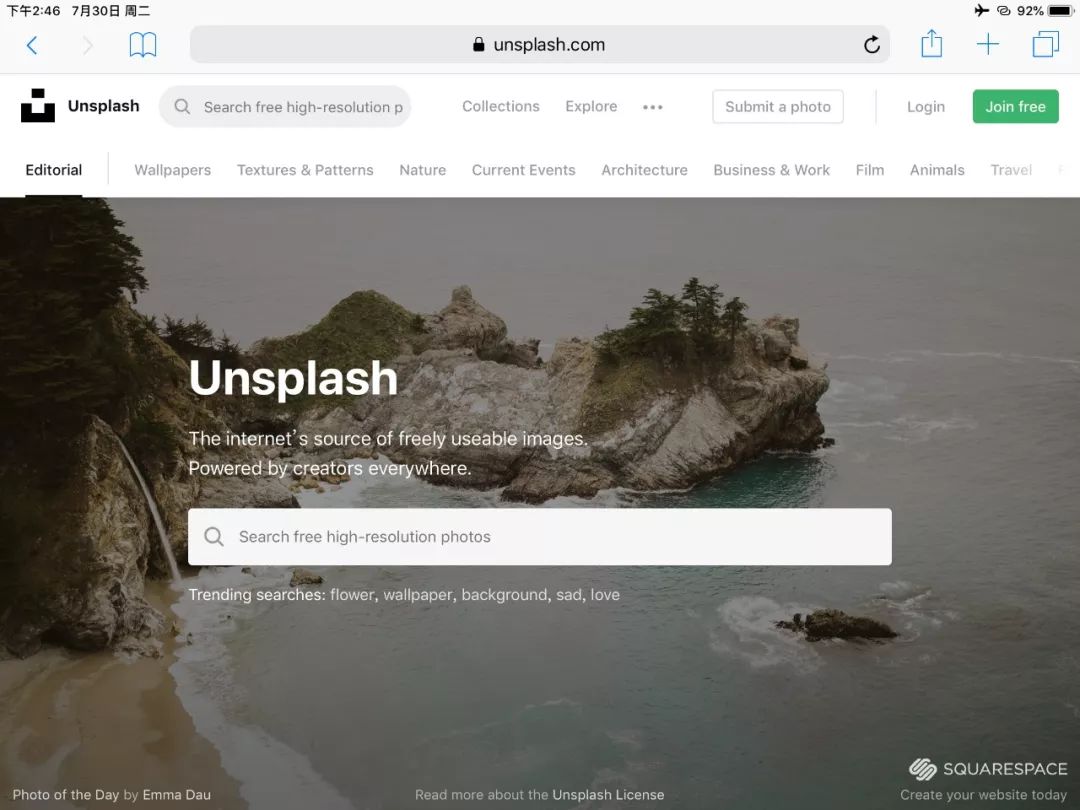
这是我个人比较中意并且经常几乎天天访问的一个网站,Unsplash。
现在网络上什么东西的使用都可能涉及版权,最为高危的就是照片类的项目了,如果一不小心被控为商用利益侵权的话会很麻烦,虽然本公号也非强制付费阅读类的商用目的,但我还是想尽量避免版权纠纷,于是寻找无版权可任意使用的图源是最好的选择了。
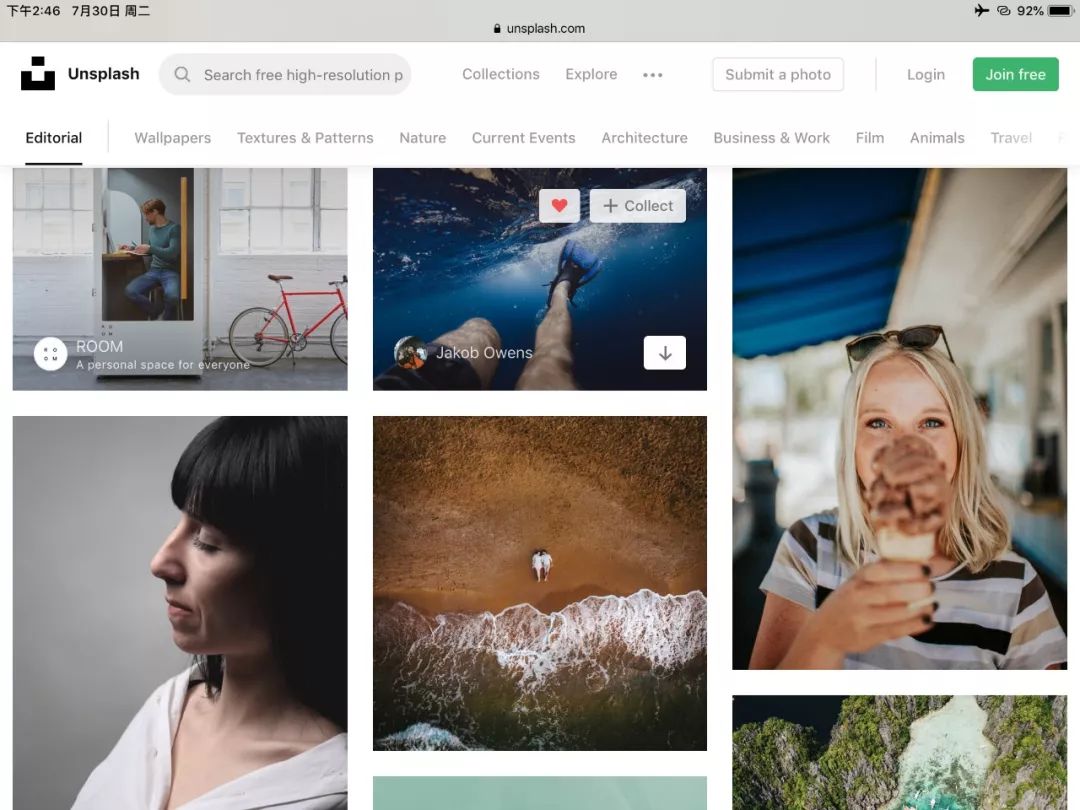
Unsplash几乎每天都会更新,各种分门别类的标签每天新增10到20甚至更多的图片,可供自由下载超高清原图,而且无需版权许可,供君任意使用无论商用与否。这种公益性质的网站无疑是许多个人媒体必备之神器。我们今天就用这个网站作为例子,主要讲解URL输出来批量获取这里面的超清资源。
O 先分析获取方法
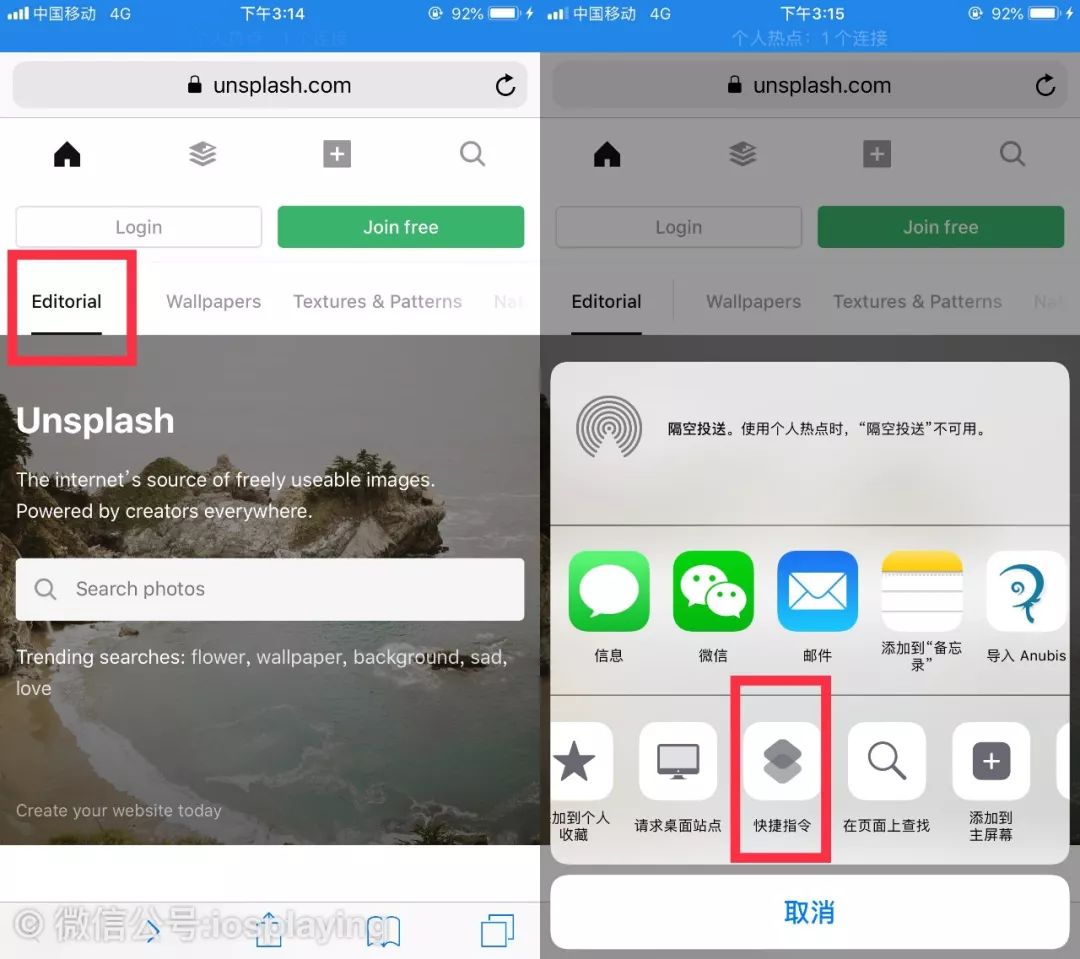
直接访问 unsplash.com ,默认是 Editorial 的主编推荐栏目,如果我们要获取这个栏目下今天更新的超清图片的话,最简单的当然是直接共享启动捷径这个步骤了。
当然如果你直接复制链接亲自去选择捷径来运行也可以,而且有些第三方浏览器在共享方面可能存在限制也不得不用这种方法。
所以现在我们分析了两种获取来源的输入方式后就可以开始了。
O 开始制作捷径
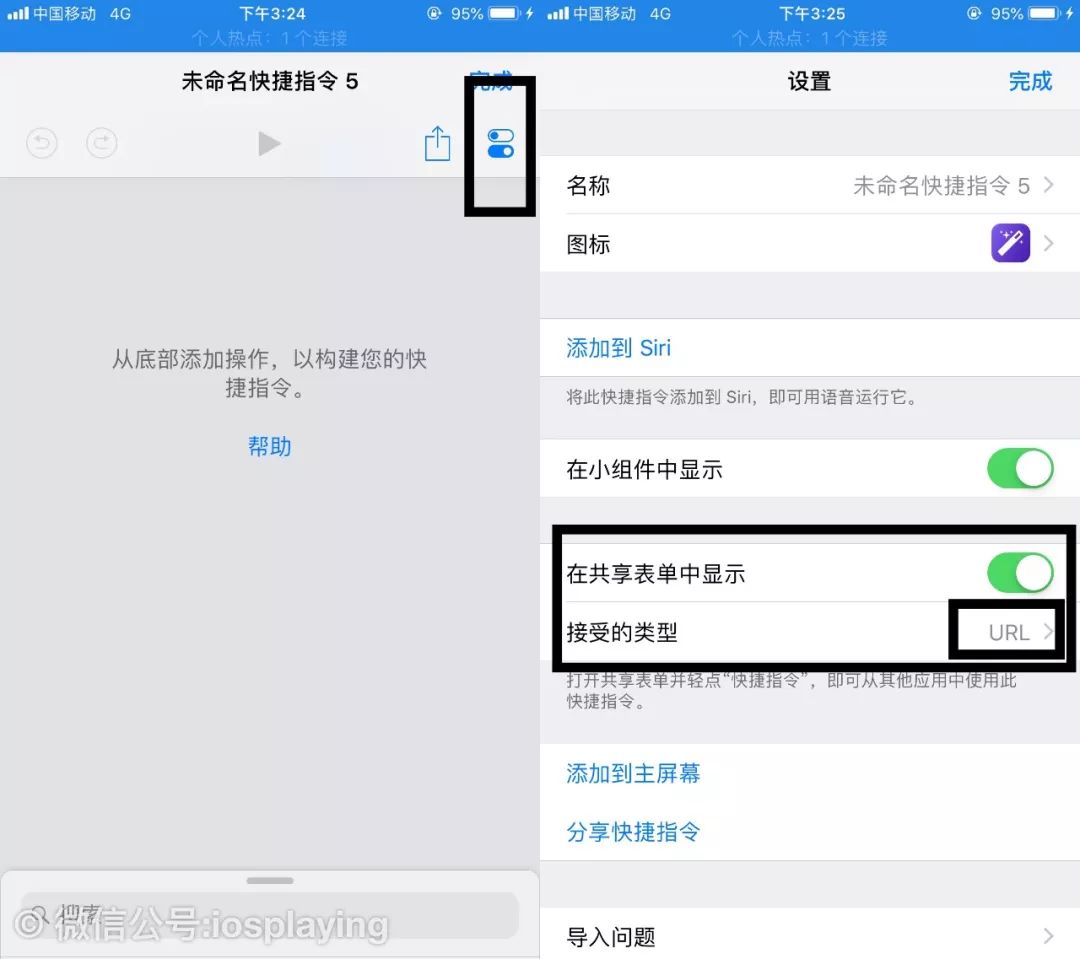
创建一个空白捷径后,首先进入其设置,将“在共享表单中显示”打开,并将接受类型限制在URL上,这样当共享的是属于链接源并选择捷径时打开就能选择该项目了。
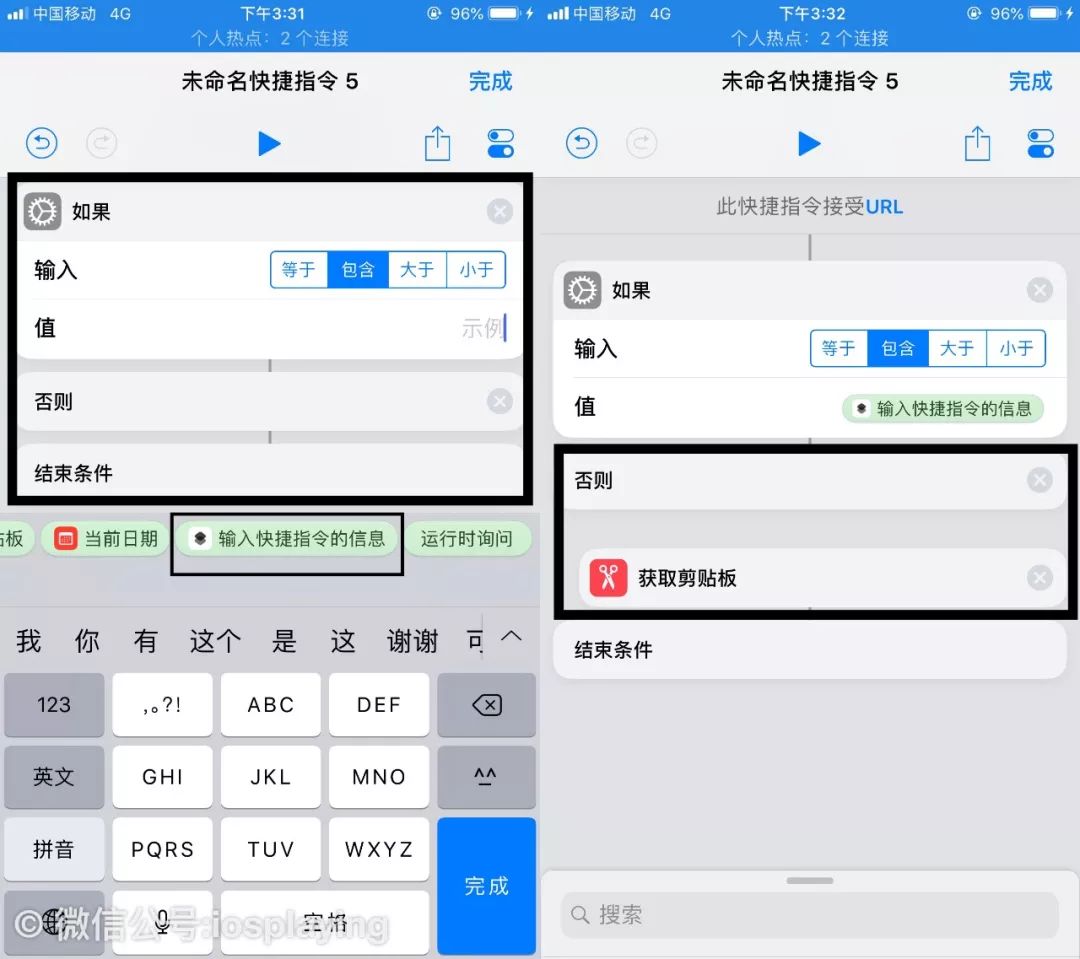
回到首页添加“如果”并在“值”里点击,编辑时会自动在输入法上方弹出一些快捷操作,选择“输入快捷指令的信息”,这就是共享到捷径时输入的内容获取。
再在“否则”下方添加“获取剪贴板”,也就是在我们亲手复制链接来运行的情况。
很熟悉的步骤吧,这也可以当作是某类输入源时的常规操作,像是文本链接日期之类的都可以适当地运用进去。
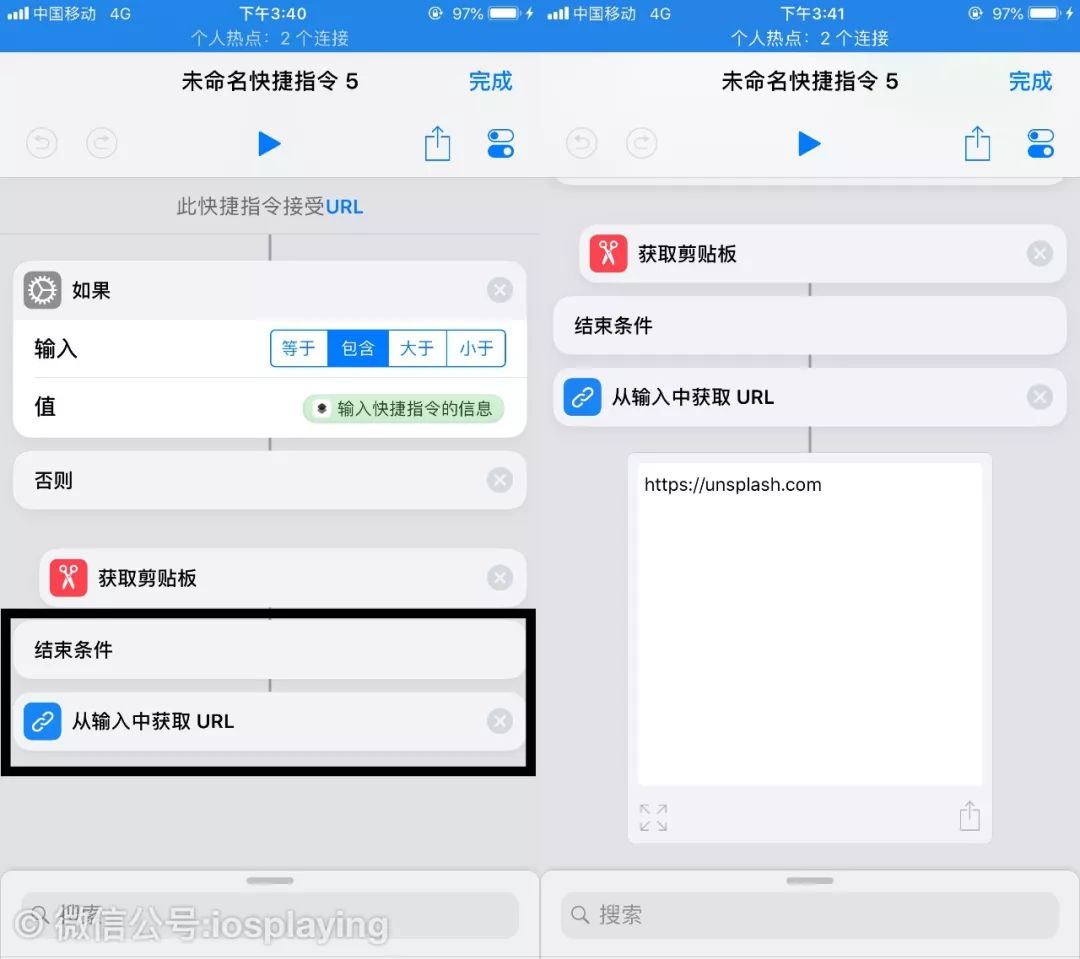
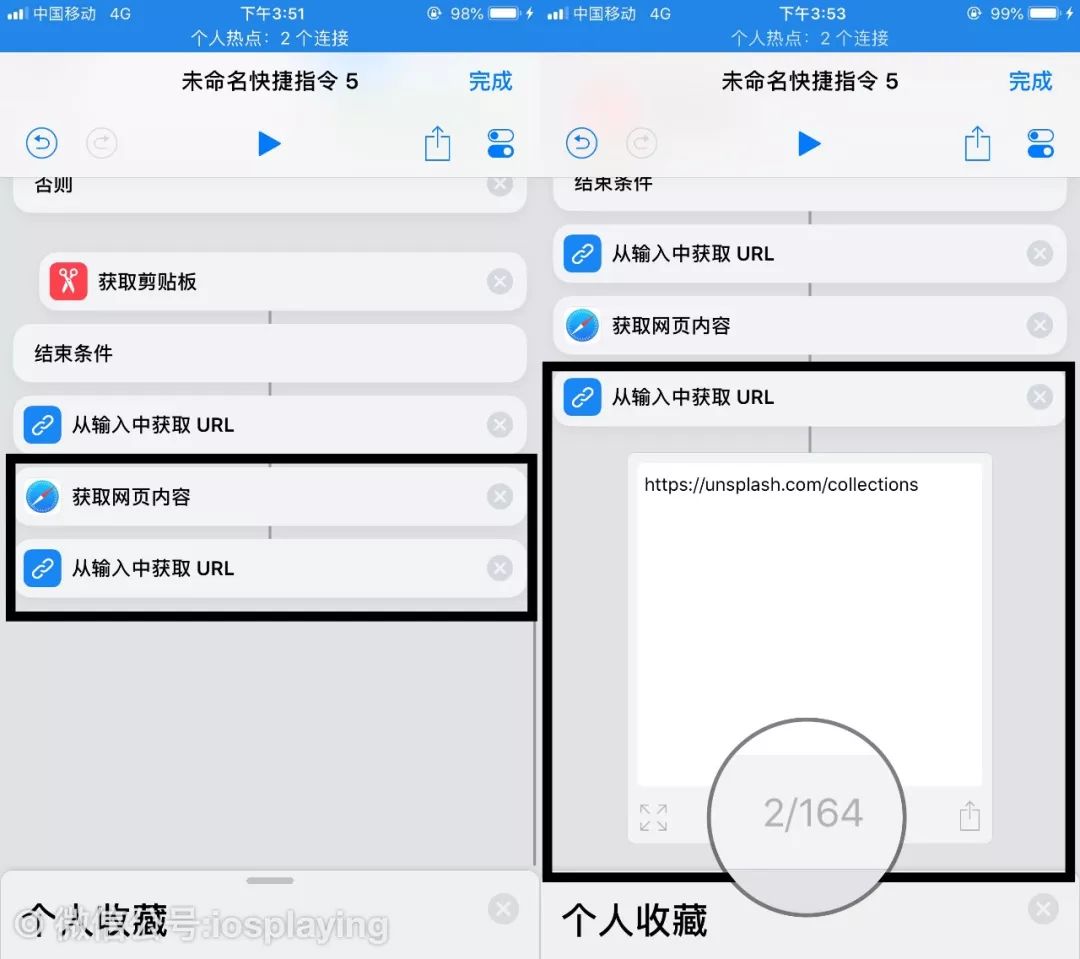
以免有时候共享到捷径的链接含有标题之类的,或者我们亲手复制的来源含有多余的东西,这个“从输入中获取URL”也是很常规必须的。试运行一下就能看见复制了链接了,但我们要的是这个链接的网页内容。
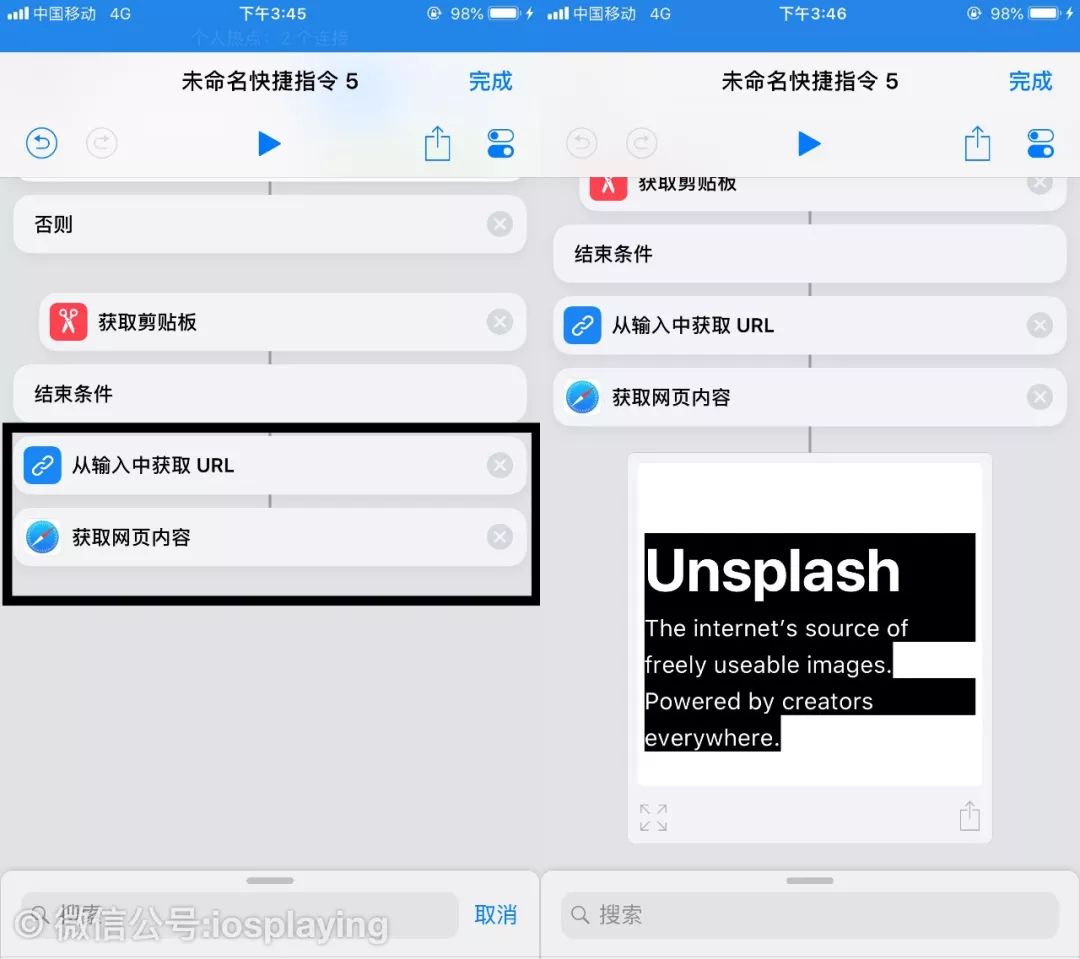
所以,我们添加一个“获取网页内容”,运行一下就能看见这个网站启动后的预览了。
但我们并不是需要里面所有的内容,我们只需要每天更新在最前面的的十到二十的图片,并且还得是超清的原图,而不是缩略图预览图之类的。
如果你亲自去看这个网站的首页你先看到的那些当然只是预览图,超清图需要你亲自点击一个下载按钮进去才能获得。
首先就需要意识到,我们上面获得了这个网页的内容后,超清图本身虽然不在其中,但是“下载按钮”包含的跳转链接是包含在里面的,所以我们要再次添加“从输入中获取URL”。
试着运行一下,你就会发现有多达一百六十四个的URL链接,这里面不仅包含了超清原图的链接,也包含缩略图等其他杂讯链接,所以接下来我们得筛选匹配了。
而关键是我们要怎么获知这些超清原图拥有怎样的特殊标识呢?如果你是在电脑端的话各种工具浏览器都支持查看网页源码,屏幕大找起来也方便,不过既然我们是手机的话,还是用我们最熟悉的thor来解答一下这个问题吧。
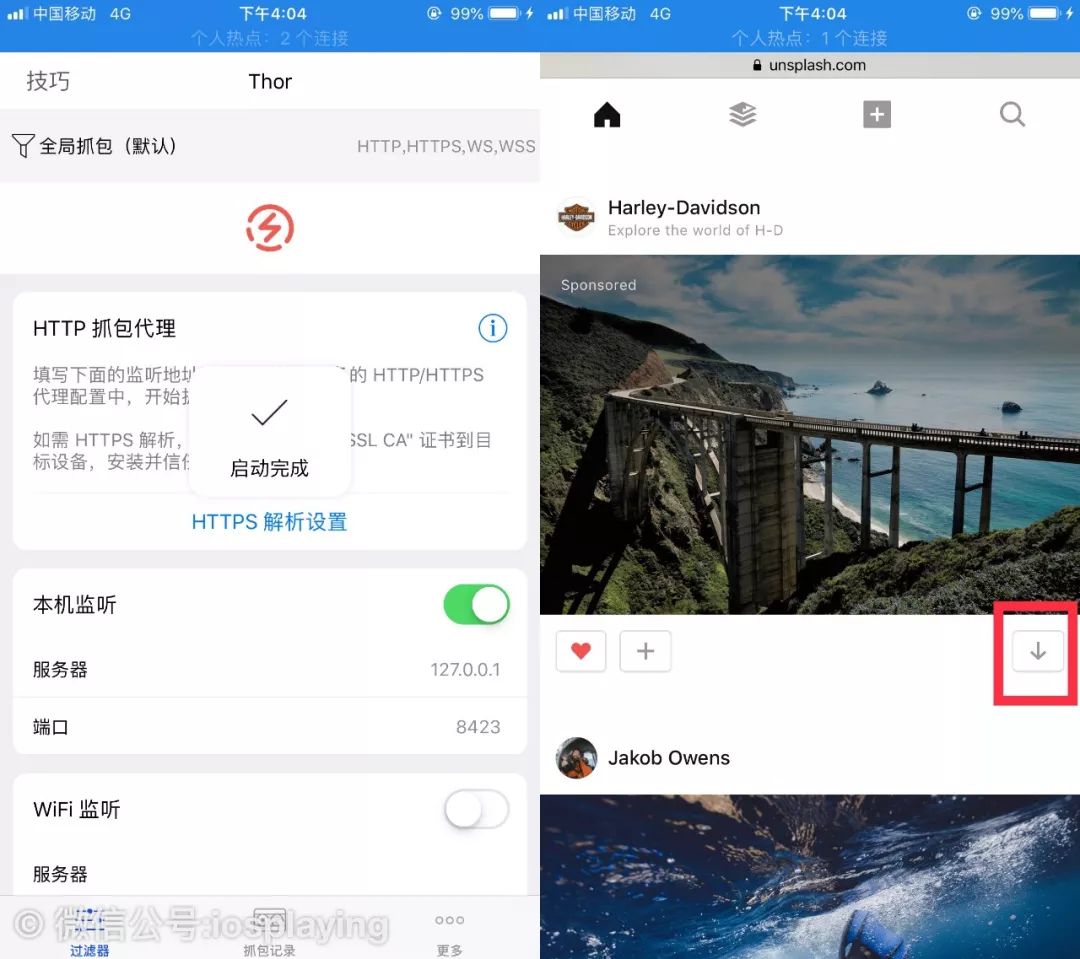
启动thor的全局过滤,进入浏览器打开unsplash网站,如果已经在这个网站的话就刷新一下,找到一张图片,其有个下载按钮就超清原图的链接了,点击以后等待加载完整。
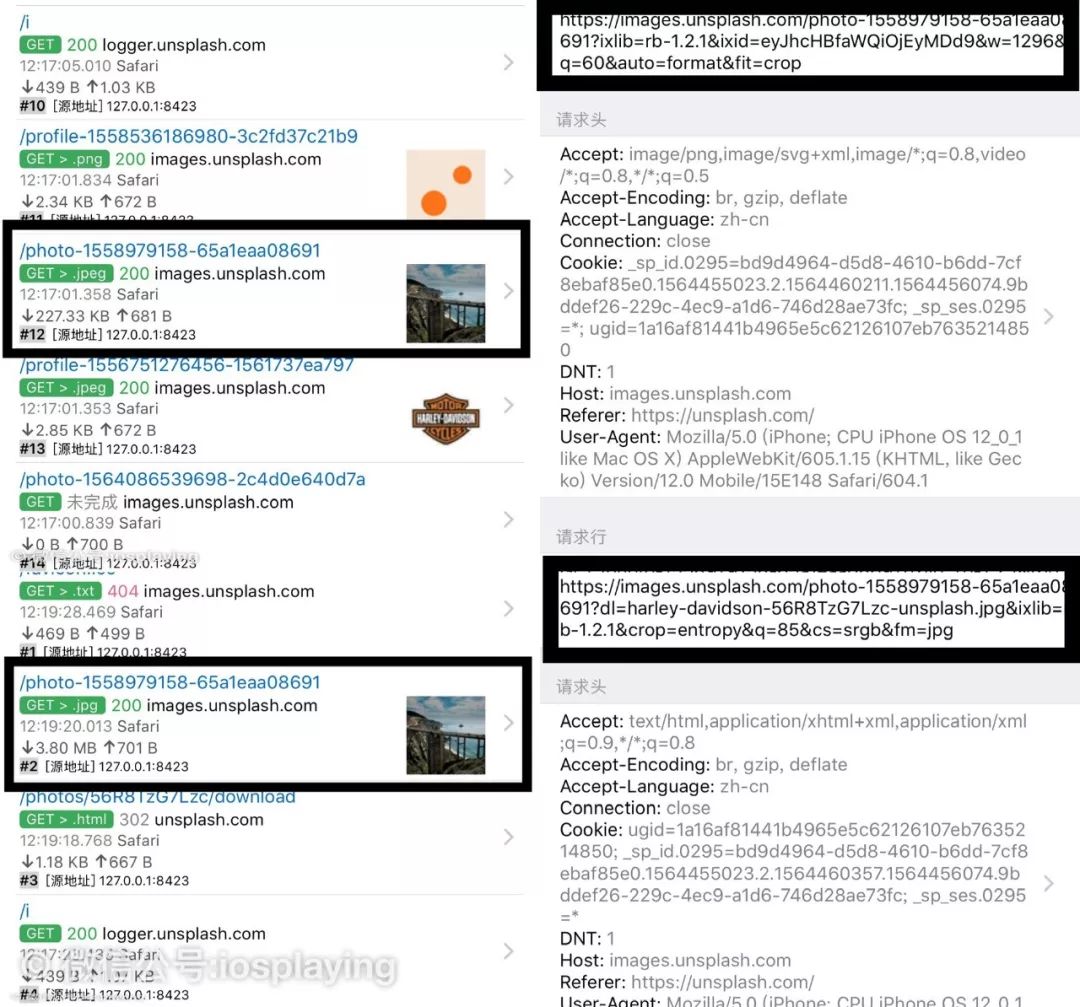
上是缩略图,下是原图。如果按照之前曾有讲解过的教程的话,我们第一个冒出来的念头的就是查看这两者的不同点,找准原图的链接里特有的字符,然后匹配就得了。
但是你有发现吧,我们上面演示的时候就发现打开这个网站里面就包含有一百六十多个URL链接啊,你怎么知道原图里的某些字符其他链接里没有呢?而且这张原图是我们亲手打开才获知链接的哦。所以这种方法在这里并不适用。
我们需要找更准确的路径。
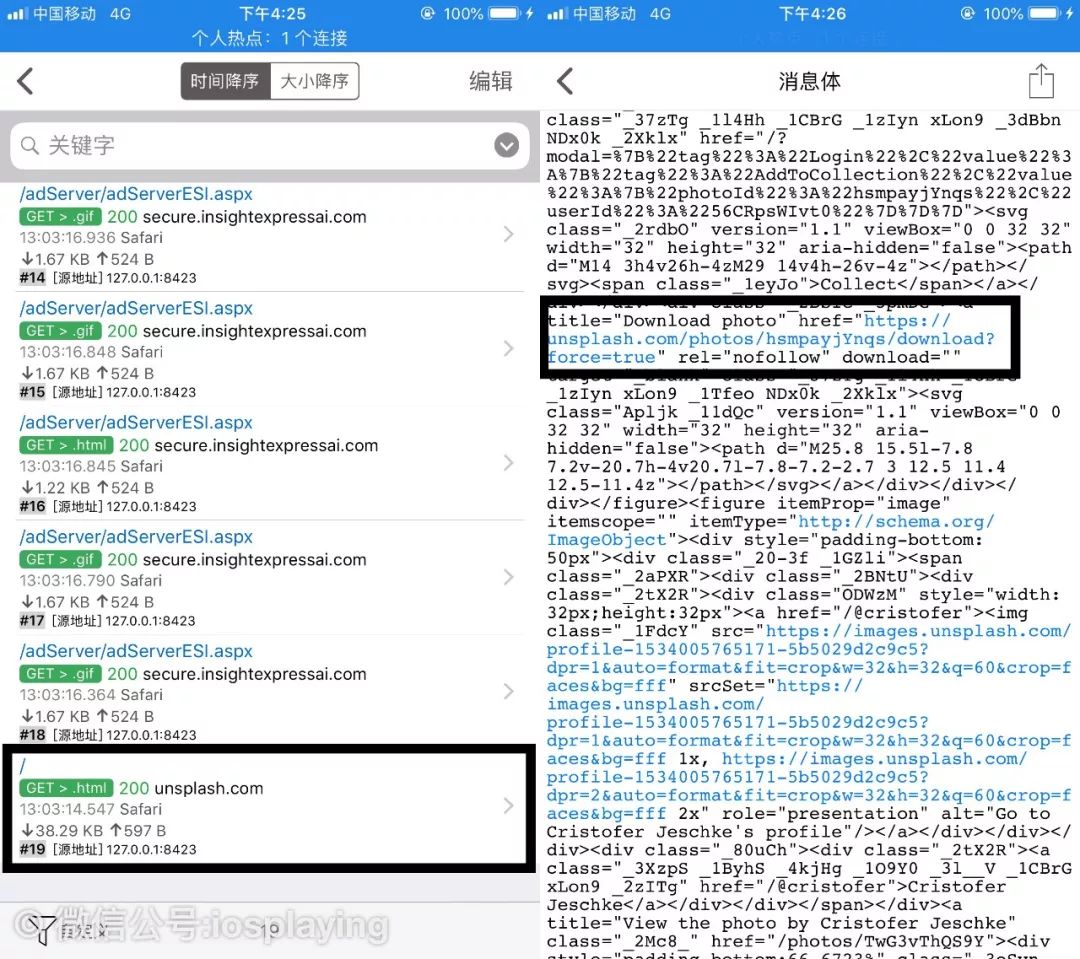
在thor全局捕获的数据里找到最后面的带有“html”标志的,这就是我们起始访问获得链接,响应里面就包含了这个网页的源码,我们的原图跳转下载的链接就包含其中。
Download photo ,很明显吧。右图黑色框住的就是下载按钮的内容,蓝色的部分就是该原图的跳转链接,你试着点击一下就可以知道结果。
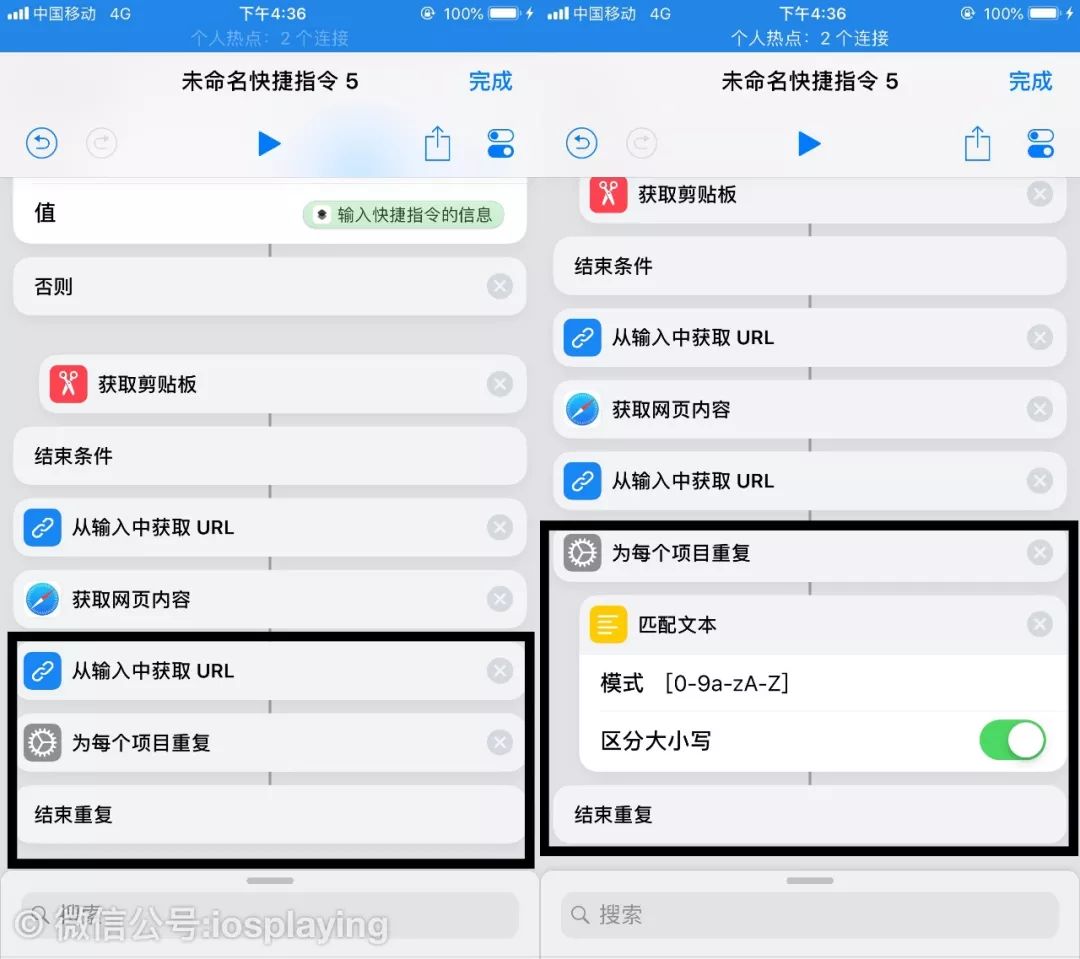
添加一个“为每个项目重复”并在其中间插入一个“匹配文本”,我们要开始匹配真正需要获取的链接了。
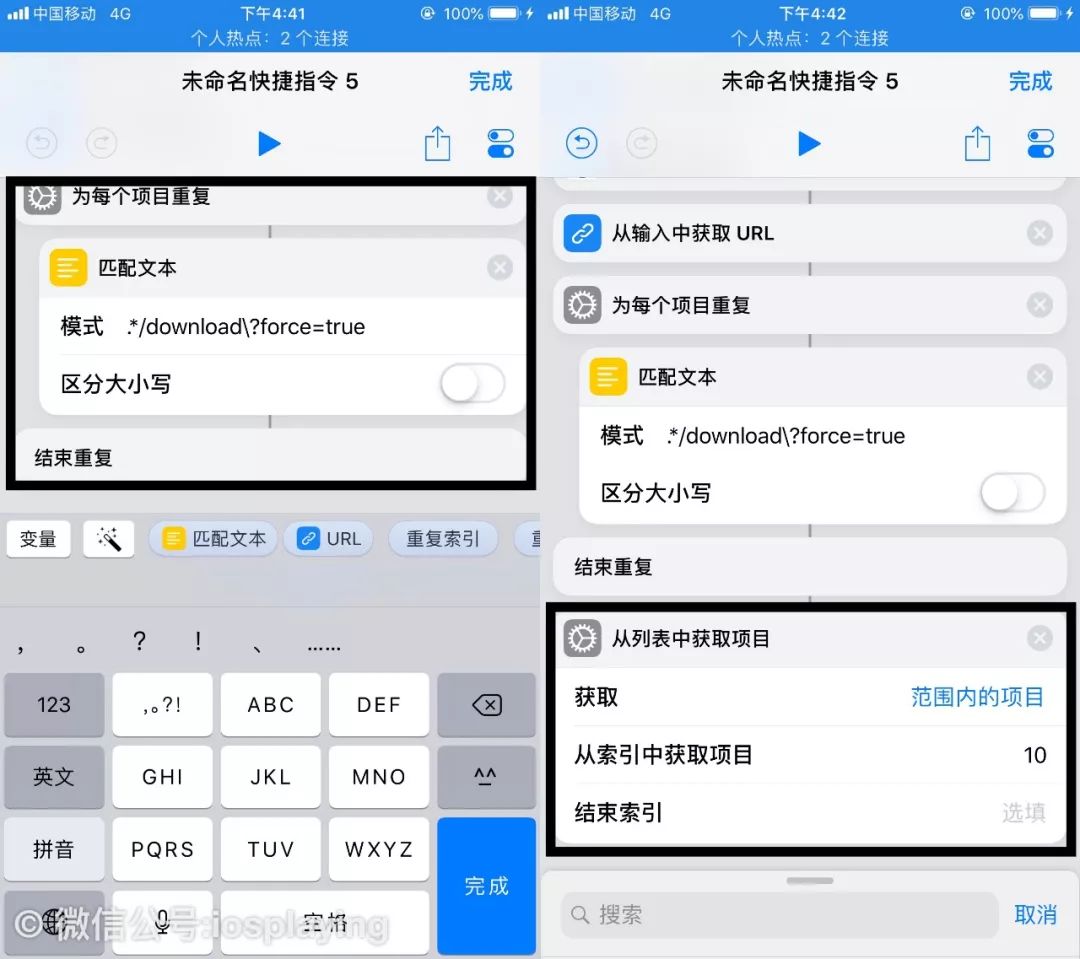
匹配里是支持正则表达式的,用 .* 代表前面的部分,唯有问号?需要注意一下 ,因为问号在正则里是元字符的存在,作为非贪婪匹配用的,但是这里我们只想要问号本身而已,所以需要加上一个斜杠转义。
再添加一个“从列表中获取项目”,因为我只需要最新的一批原照即可,当然如果你连旧的也需要的话填的数字可以大一些,或者浏览网页的时候自己限定。
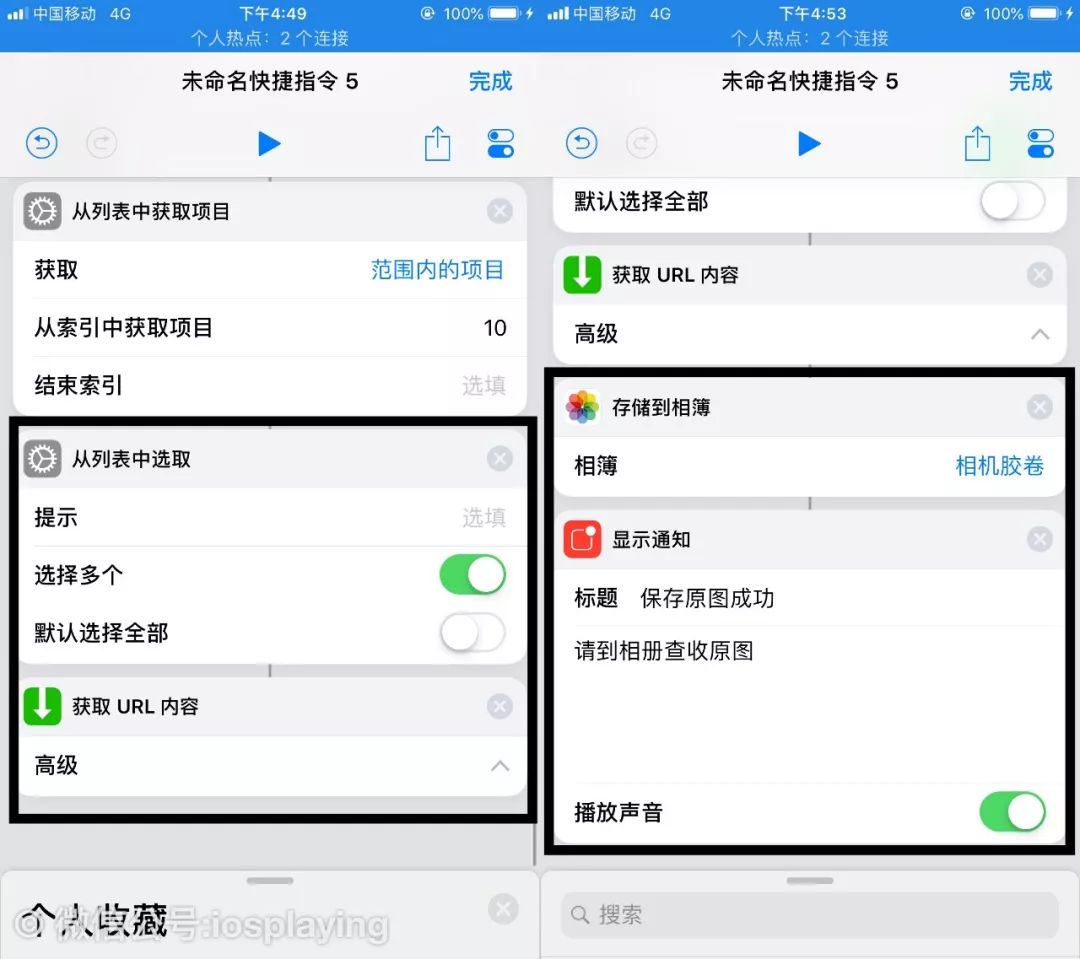
如果还想再次进行挑选可以添加一个弹出式的“从列表中选取”,并打开多个的选项。再添加一个“获取URL内容”来获得该链接的原图。
然后就是保存到相册,再加一个“显示通知”稍加编辑就完美了。如果访问下载慢的话尝试番一下,毕竟该网站主服务器应该是国外的,国内有时访问量大的话会有些慢。
教程到此结束。微的群建议加一下luailin0(全小写加一个零),请稍耐心。















 1508
1508











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









