






求100内的素数
为了比较算法效率我们扩大到求100000内素数
# 1 简单算法
- #一个数能被从2开始到自己的平方根的正整数整数整除,就是合数
import # 2 使用奇数
import # 3 存储质数
- #合数一定可以分解为几个质数的乘积, 2 是质数
- #质数一定不能整除1和本身之内的整数
import # 4 在#3的基础上缩小范围
import 算法2和算法4对比,算法2的奇数应该是多余算法4的,也就是算法4应该要快一点,但是测试的计时却不是,为什么?
结果是增加了质数列表反而慢了,为什么?
修改算法如下
# 4 缩小范围
这回测试,速递第一了。也就是增加了列表,记录了质数,控制了边界后,使用质数来取模比使用奇数计算更少。
空间换时间,使用列表空间存储质数列表,来换取计算时间。
孪生素数性质
大于3的素数只有6N-1和6N+1两种形式,如果6N-1和6N+1都是素数称为孪生素数
import 用了这个性质并没有超过算法4,原因还是在于使用列表存储已经计算得到的素数来减少计算。请自行使用列表完成素数的存储。
计算杨辉三角前6行
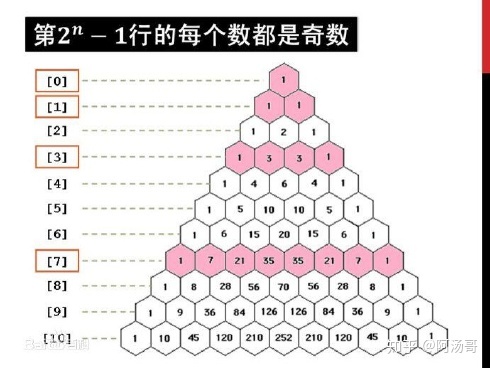
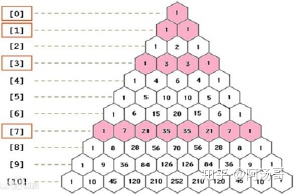
n行有n项,n是正整数
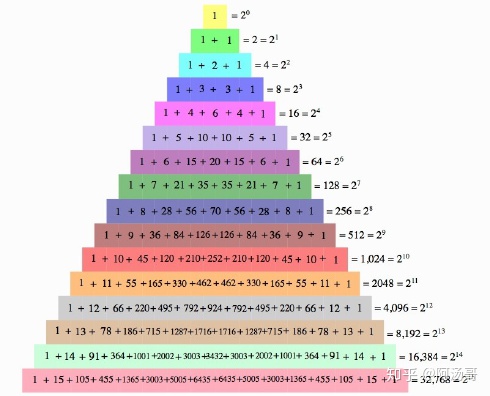
第n行数字之和为2**(n-1)
解法1 杨辉三角的基本实现
下一行依赖上一行所有元素,是上一行所有元素的两两相加的和,再在两头各加1
预先构建前两行,从而推导出后面的所有行
triangle 变体
从第一行开始
triangle 解法2 补零
- 除了第一行以外,每一行每一个元素(包括两头的1)都是由上一行的元素相加得到。如何得到两头的1呢?
- 目标是打印指定的行,所以算出一行就打印一行,不需要用一个大空间存储所有已经算出的行。
for循环实现
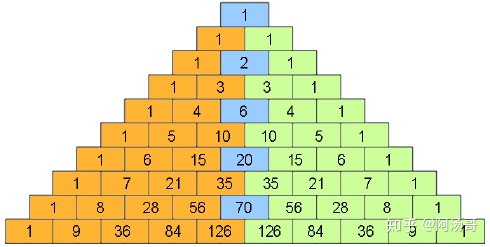
n 解法3 对称性
思路:
- 能不能一次性开辟空间,可以使用列表解析式或者循环迭代的方式。
- 能不能减少一半的数字计算。左右对称。
1、 构建行
triangle 上面创建每一行的代码过于啰嗦了,一次性创建出一行,以后覆盖其中数据就行了
triangle 2、 中点的确定
[1]
[1, 1]
[1, 2, 1]
[1, 3, 3, 1]
[1, 4, 6, 4, 1]
[1, 5, 10, 10, 5, 1]
把整个杨辉三角看成左对齐的二维矩阵。
i==2时,在第3行,中点的列索引j==1
i==3时,在第4行,无中点
i==4时,在第5行,中点的列索引j==2
得到以下规律,如果有i==2j,则有中点triangle 上面的代码row[-j-1] = val 多做了一次
triangle 另一种中点的处理
i 中点索引 j
[1]
[1, 1]
[1, 2, 1] 2 1 or -2 0
[1, 3, 3, 1]
[1, 4, 6, 4, 1] 4 2 or -3 1
[1, 5, 10, 10, 5, 1]
[1, 6, 15, 20, 15, 6, 1] 6 3 or -4 2
由此,得到中点的索引处i和j关系为i=2*(j+1)其实,相当于上例中代码的j循环向左平移1,将所有的j变成 j+1
# 对称
解法4 单行覆盖
- 方法2每次都要清除列表,有点浪费时间。
- 能够用上方法3的对称性的同时,只开辟1个列表实现吗?
首先我们明确的知道所求最大行的元素个数,例如前6行的最大行元素个数为6个。
下一行等于首元素不变,覆盖中间元素。
n = 6
row = [1] * n # 一次性开辟足够的空间
print(row)
print('-' * 30)
for i in range(n):
print(row[:i+1])
运行结果如下
[1, 1, 1, 1, 1, 1]
------------------------------
[1]
[1, 1]
[1, 1, 1]
[1, 1, 1, 1]
[1, 1, 1, 1, 1]
[1, 1, 1, 1, 1, 1]由于,这一次直接开辟了所有大小的列表空间,导致负索引比较难计算。
是否可以考虑直接使用正索引计算呢?
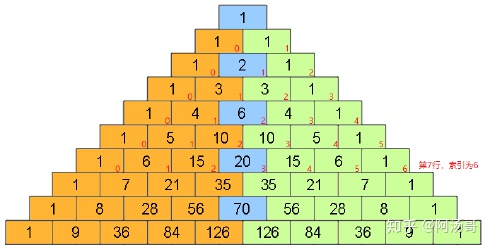
以第七行为例,索引1对称索引为5,而1 + 5 = 6当前索引值。
n 问题出在哪里了呢?
原因在于,4覆盖了3,导致3+3变成了3+4才有了7。使用一个临时变量解决
n 也可以写成下面这样
n 














 1797
1797











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









