





文源网络,仅供学习之用,如有侵权请联系删除。
在 Redis 3.0 之前,使用 哨兵(sentinel)机制来监控各个节点之间的状态。
Redis Cluster 是 Redis 的 分布式解决方案,在 3.0 版本正式推出,有效地解决了 Redis 在 分布式 方面的需求。当遇到 单机内存、并发、流量 等瓶颈时,可以采用 Cluster 架构方案达到 负载均衡 的目的。
本文将从 集群方案、数据分布、搭建集群、节点通信、集群伸缩、请求路由、故障转移、集群运维 等几个方面介绍 Redis Cluster。
Redis集群方案
Redis Cluster 集群模式通常具有 高可用、可扩展性、分布式、容错 等特性。Redis 分布式方案一般有两种:
1、 客户端分区方案
客户端 就已经决定数据会被 存储 到哪个 redis 节点或者从哪个 redis 节点 读取数据。其主要思想是采用 哈希算法 将 Redis 数据的 key 进行散列,通过 hash 函数,特定的 key会 映射到特定的 Redis 节点上。
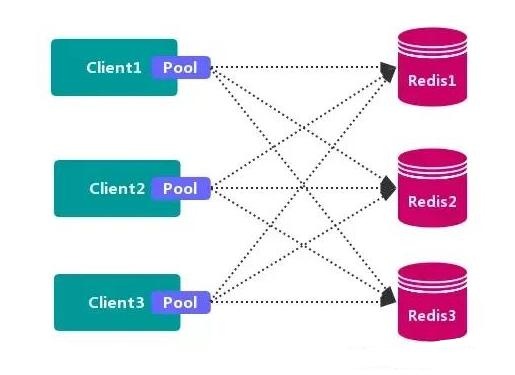
客户端分区方案 的代表为 Redis Sharding,Redis Sharding 是 Redis Cluster 出来之前,业界普遍使用的 Redis 多实例集群 方法。Java 的 Redis 客户端驱动库 Jedis,支持 Redis Sharding 功能,即 ShardedJedis 以及 结合缓存池 的 ShardedJedisPool。
优点
不使用 第三方中间件,分区逻辑 可控,配置 简单,节点之间无关联,容易 线性扩展,灵活性强。
缺点
客户端 无法 动态增删 服务节点,客户端需要自行维护 分发逻辑,客户端之间 无连接共享,会造成 连接浪费。
2、代理分区方案
客户端 发送请求到一个 代理组件,代理 解析 客户端 的数据,并将请求转发至正确的节点,最后将结果回复给客户端。
- 优点:简化 客户端 的分布式逻辑,客户端 透明接入,切换成本低,代理的转发和存储分离。
- 缺点:多了一层 代理层,加重了 架构部署复杂度 和 性能损耗。
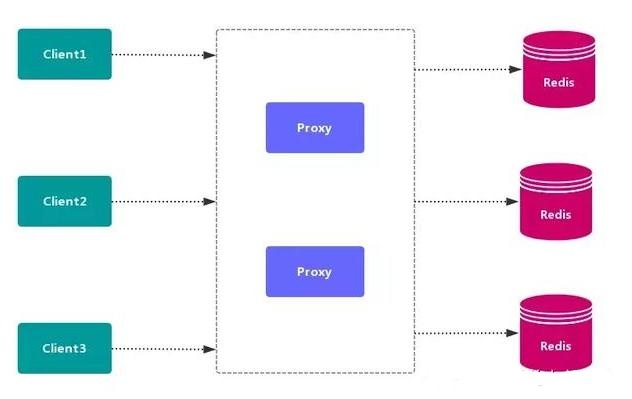
代理分区 主流实现的有方案有 Twemproxy 和 Codis。
2.1. Twemproxy
Twemproxy 也叫 nutcraker,是 twitter 开源的一个 redis 和 memcache 的 中间代理服务器 程序。Twemproxy 作为 代理,可接受来自多个程序的访问,按照 路由规则,转发给后台的各个 Redis 服务器,再原路返回。Twemproxy 存在 单点故障 问题,需要结合 Lvs 和 Keepalived 做 高可用方案。
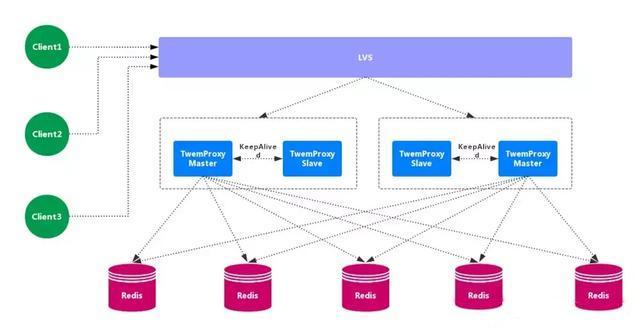
优点:应用范围广,稳定性较高,中间代理层 高可用。
缺点:无法平滑地 水平扩容/缩容,无 可视化管理界面,运维不友好,出现故障,不能 自动转移。
2.2. Codis
Codis 是一个 分布式 Redis 解决方案,对于上层应用来说,连接 Codis-Proxy 和直接连接 原生的 Redis-Server 没有的区别。Codis 底层会 处理请求的转发,不停机的进行 数据迁移 等工作。Codis 采用了无状态的 代理层,对于 客户端 来说,一切都是透明的。
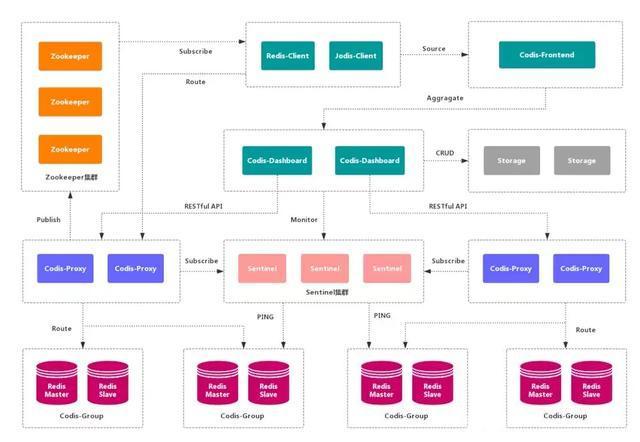
优点
实现了上层 Proxy 和底层 Redis 的 高可用,数据分片 和 自动平衡,提供 命令行接口 和 RESTful API,提供 监控 和 管理 界面,可以动态 添加 和 删除 Redis 节点。
缺点
部署架构 和 配置 复杂,不支持 跨机房 和 多租户,不支持 鉴权管理。
3、查询路由方案
客户端随机地 请求任意一个 Redis 实例,然后由 Redis 将请求 转发 给 正确 的 Redis 节点。Redis Cluster 实现了一种 混合形式 的 查询路由,但并不是 直接 将请求从一个 Redis 节点 转发 到另一个 Redis 节点,而是在 客户端 的帮助下直接 重定向( redirected)到正确的 Redis 节点。
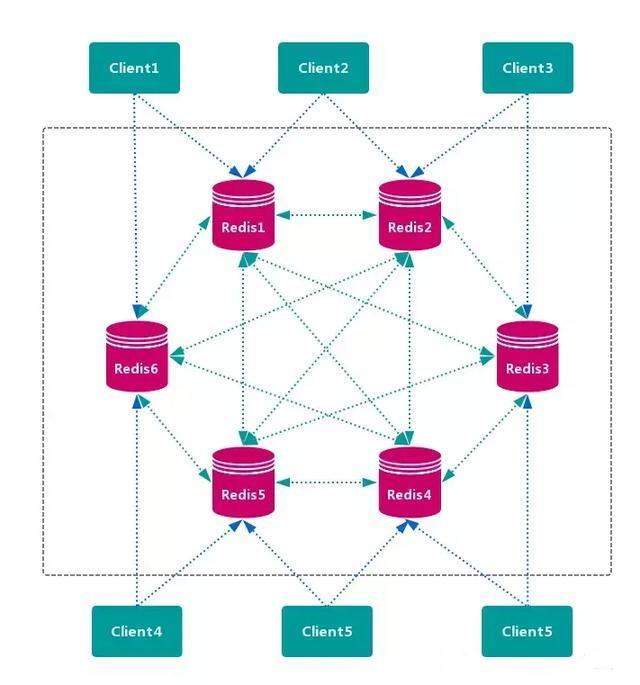
优点
无中心节点,数据按照 槽 存储分布在多个 Redis 实例上,可以平滑的进行节点 扩容/缩容,支持 高可用 和 自动故障转移,运维成本低。
缺点
严重依赖 Redis-trib 工具,缺乏 监控管理,需要依赖 Smart Client (维护连接,缓存路由表,MultiOp 和 Pipeline 支持)。Failover 节点的 检测过慢,不如 中心节点 ZooKeeper 及时。Gossip 消息具有一定开销。无法根据统计区分 冷热数据。
数据分布
1、数据分布理论
分布式数据库首先要解决把整个数据集按照分区规则映射到 多个节点 的问题,即把数据集划分到 多个节点 上,每个节点负责 整体数据 的一个子集。
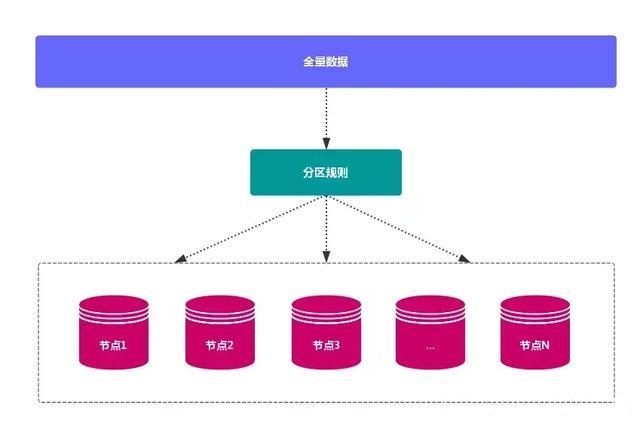
数据分布通常有 哈希分区 和 顺序分区 两种方式,对比如下:
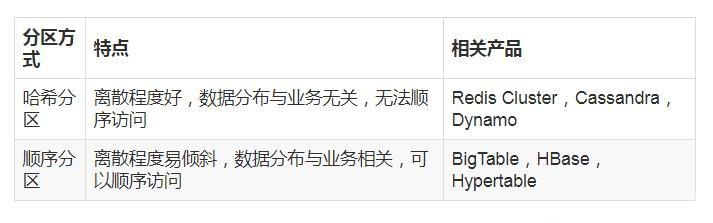
由于 Redis Cluster 采用 哈希分区规则,这里重点讨论 哈希分区。常见的 哈希分区 规则有几种,下面分别介绍:
1.1 节点取余分区
使用特定的数据,如 Redis 的 键 或 用户 ID,再根据 节点数量 N 使用公式:hash(key)% N 计算出 哈希值,用来决定数据 映射 到哪一个节点上。
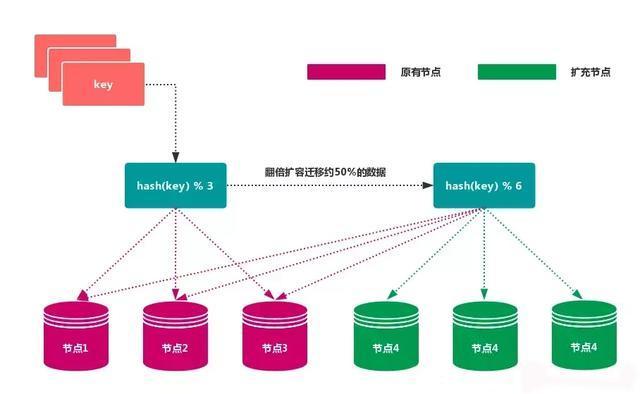
优点
这种方式的突出优点是 简单性,常用于数据库的分库分表规则。一般采用预分区的方式,提前根据 数据量规划好分区数。
比如划分为 512 或 1024 张表,保证可支撑未来一段时间的 数据容量,再根据 负载情况 将 表 迁移到其他 数据库 中。扩容时通常采用 翻倍扩容,避免 数据映射 全部被 打乱,导致 全量迁移 的情况。
缺点
当节点数量变化时,如扩容或收缩节点,数据节点映射关系需要重新计算,会导致数据的重新迁移。
1.2. 一致性哈希分区
一致性哈希 可以很好的解决稳定性问题,可以将所有的 存储节点排列在收尾相接的Hash 环上,每个 key 在计算 Hash后会顺时针找到临接的存储节点存放。而当有节点加入或退出时,仅影响该节点在 Hash 环上顺时针相邻的后续节点。
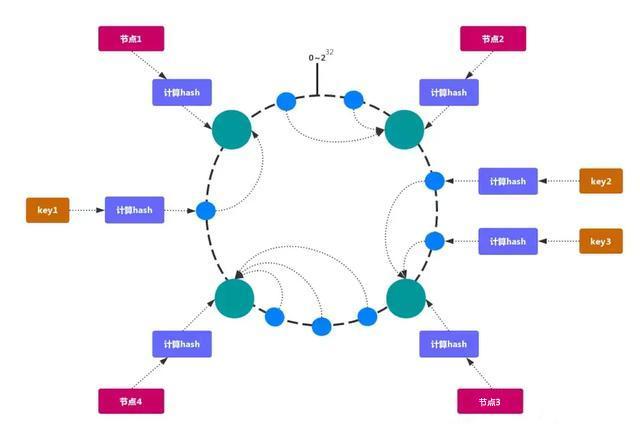
优点
加入 和 删除 节点只影响 哈希环 中 顺时针方向 的 相邻的节点,对其他节点无影响。
缺点
加减节点会造成哈希环中部分数据 无法命中。当使用少量节点 时,节点变化将大范围影响哈希环 中数据映射,不适合少量数据节点 的分布式方案。普通的 一致性哈希分区在增减节点时需要增加一倍或减去一半节点才能保证数据和负载的均衡。
注意:因为 一致性哈希分区 的这些缺点,一些分布式系统采用 虚拟槽 对 一致性哈希 进行改进,比如 Dynamo 系统。
1.3. 虚拟槽分区
虚拟槽分区 巧妙地使用了 哈希空间,使用 分散度良好 的 哈希函数 把所有数据 映射 到一个 固定范围 的 整数集合 中,整数定义为 槽(slot)。
这个范围一般远远大于节点数,比如 Redis Cluster 槽范围是 0 ~ 16383。槽是集群内数据管理和迁移的基本单位。采用大范围槽的主要目的是为了方便数据拆分和集群扩展。每个节点会负责 一定数量的槽,如图所示:
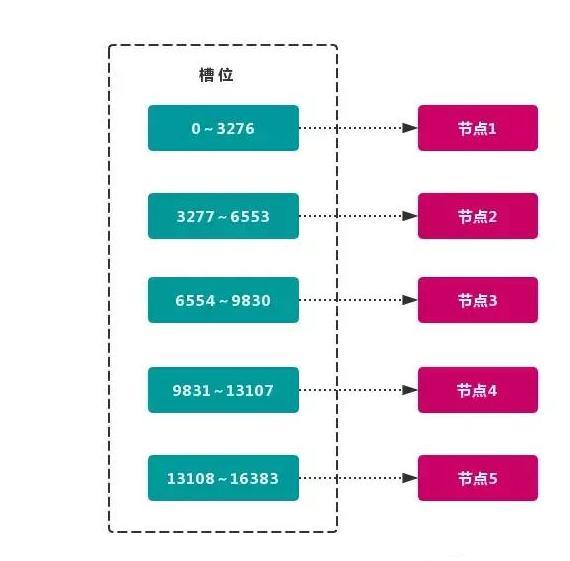
当前集群有 5 个节点,每个节点平均大约负责 3276 个 槽。由于采用 高质量 的 哈希算法,每个槽所映射的数据通常比较 均匀,将数据平均划分到 5 个节点进行 数据分区。Redis Cluster 就是采用 虚拟槽分区。
- 节点1: 包含 0 到 3276 号哈希槽。
- 节点2:包含 3277 到 6553 号哈希槽。
- 节点3:包含 6554 到 9830 号哈希槽。
- 节点4:包含 9831 到 13107 号哈希槽。
- 节点5:包含 13108 到 16383 号哈希槽。
这种结构很容易添加或者删除节点。如果增加 一个节点 6,就需要从节点 1 ~ 5 获得部分槽分配到节点 6 上。如果想移除节点 1,需要将节点 1 中的 槽 移到节点 2 ~ 5 上,然后将没有任何槽 的节点 1 从集群中移除即可。
由于从一个节点将 哈希槽 移动到另一个节点并不会 停止服务,所以无论添加删除或者改变某个节点的哈希槽的数量都不会造成集群不可用的状态。
2、Redis的数据分区
Redis Cluster 采用 虚拟槽分区,所有的 键 根据 哈希函数 映射到 0~16383 整数槽内,计算公式:slot = CRC16(key)& 16383。每个节点负责维护一部分槽以及槽所映射的 键值数据,如图所示:
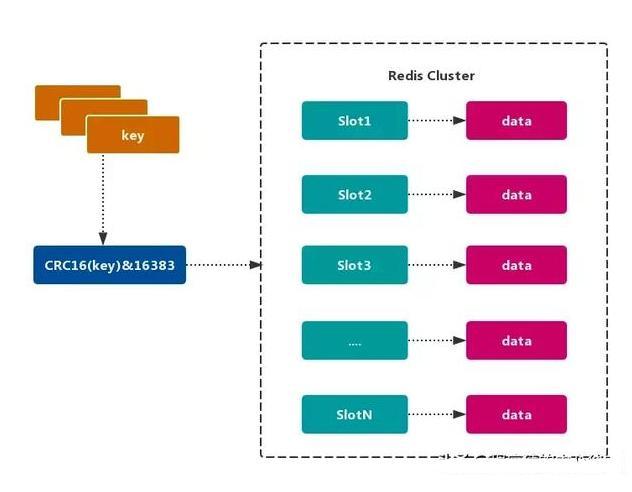
Redis虚拟槽分区的特点
解耦数据和节点之间的关系,简化了节点扩容和收缩难度。
节点自身 维护槽的 映射关系,不需要客户端或者代理服务维护槽分区元数据。
支持 节点、槽、键 之间的 映射查询,用于 数据路由、在线伸缩 等场景。
3、Redis集群的功能限制
Redis 集群相对 单机 在功能上存在一些限制,需要 开发人员 提前了解,在使用时做好规避。
key 批量操作支持有限。
类似 mset、mget 操作,目前只支持对具有相同 slot 值的 key 执行 批量操作。对于 映射为不同 slot 值的 key 由于执行 mget、mget 等操作可能存在于多个节点上,因此不被支持。
key 事务操作支持有限。
只支持 多 key 在 同一节点上 的 事务操作,当多个 key 分布在 不同 的节点上时 无法 使用事务功能。
key 作为数据分区的最小粒度
不能将一个 大的键值 对象如 hash、list 等映射到 不同的节点。
不支持多数据库空间
单机下的Redis可以支持 16 个数据库(db0 ~ db15),集群模式 下只能使用一个数据库空间,即 db0。
复制结构只支持一层
从节点 只能复制 主节点,不支持 嵌套树状复制 结构。
Redis集群搭建
Redis-Cluster 是 Redis 官方的一个 高可用 解决方案,Cluster 中的 Redis 共有 2^14(16384) 个 slot 槽。创建 Cluster 后,槽 会 平均分配 到每个 Redis 节点上。
下面介绍一下本机启动 6 个 Redis 的 集群服务,并使用 redis-trib.rb 创建 3主3从 的 集群。搭建集群工作需要以下三个步骤:
1、准备节点
Redis 集群一般由多个节点组成,节点数量至少为 6 个,才能保证组成完整高可用的集群。每个节点需要开启配置 cluster-enabled yes,让 Redis 运行在集群模式下。
Redis 集群的节点规划如下:
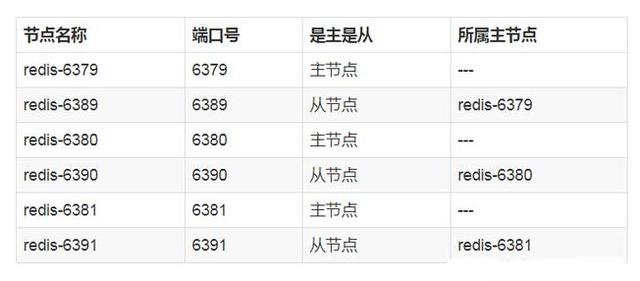
注意:建议为集群内 所有节点 统一目录,一般划分三个目录:conf、data、log,分别存放 配置、数据 和 日志 相关文件。把 6 个节点配置统一放在 conf 目录下。
1.1、创建redis各实例目录
$ sudo mkdir -p /usr/local/redis-cluster
$ cd /usr/local/redis-cluster
$ sudo mkdir conf data log
$ sudo mkdir -p data/redis-6379 data/redis-6389 data/redis-6380 data/redis-6390 data/redis-6381 data/redis-63911.2 redis配置文件管理
根据以下 模板 配置各个实例的 redis.conf,以下只是搭建集群需要的 基本配置,可能需要根据实际情况做修改。
# redis后台运行
daemonize yes
# 绑定的主机端口
bind 127.0.0.1
# 数据存放目录
dir /usr/local/redis-cluster/data/redis-6379
# 进程文件
pidfile /var/run/redis-cluster/${自定义}.pid
# 日志文件
logfile /usr/local/redis-cluster/log/${自定义}.log
# 端口号
port 6379
# 开启集群模式,把注释#去掉
cluster-enabled yes
# 集群的配置,配置文件首次启动自动生成
cluster-config-file /usr/local/redis-cluster/conf/${自定义}.conf
# 请求超时,设置10秒
cluster-node-timeout 10000
# aof日志开启,有需要就开启,它会每次写操作都记录一条日志
appendonly yesredis-6379.conf
daemonize yes
bind 127.0.0.1
dir /usr/local/redis-cluster/data/redis-6379
pidfile /var/run/redis-cluster/redis-6379.pid
logfile /usr/local/redis-cluster/log/redis-6379.log
port 6379
cluster-enabled yes
cluster-config-file /usr/local/redis-cluster/conf/node-6379.conf
cluster-node-timeout 10000
appendonly yesredis-6389.conf
daemonize yes
bind 127.0.0.1
dir /usr/local/redis-cluster/data/redis-6389
pidfile /var/run/redis-cluster/redis-6389.pid
logfile /usr/local/redis-cluster/log/redis-6389.log
port 6389
cluster-enabled yes
cluster-config-file /usr/local/redis-cluster/conf/node-6389.conf
cluster-node-timeout 10000
appendonly yesredis-6380.conf
daemonize yes
bind 127.0.0.1
dir /usr/local/redis-cluster/data/redis-6380
pidfile /var/run/redis-cluster/redis-6380.pid
logfile /usr/local/redis-cluster/log/redis-6380.log
port 6380
cluster-enabled yes
cluster-config-file /usr/local/redis-cluster/conf/node-6380.conf
cluster-node-timeout 10000
appendonly yesredis-6390.conf
daemonize yes
bind 127.0.0.1
dir /usr/local/redis-cluster/data/redis-6390
pidfile /var/run/redis-cluster/redis-6390.pid
logfile /usr/local/redis-cluster/log/redis-6390.log
port 6390
cluster-enabled yes
cluster-config-file /usr/local/redis-cluster/conf/node-6390.conf
cluster-node-timeout 10000
appendonly yesredis-6381.conf
daemonize yes
bind 127.0.0.1
dir /usr/local/redis-cluster/data/redis-6381
pidfile /var/run/redis-cluster/redis-6381.pid
logfile /usr/local/redis-cluster/log/redis-6381.log
port 6381
cluster-enabled yes
cluster-config-file /usr/local/redis-cluster/conf/node-6381.conf
cluster-node-timeout 10000
appendonly yesredis-6391.conf
daemonize yes
bind 127.0.0.1
dir /usr/local/redis-cluster/data/redis-6391
pidfile /var/run/redis-cluster/redis-6391.pid
logfile /usr/local/redis-cluster/log/redis-6391.log
port 6391
cluster-enabled yes
cluster-config-file /usr/local/redis-cluster/conf/node-6391.conf
cluster-node-timeout 10000
appendonly yes2、环境准备
2.1 安装Ruby环境
$ sudo brew install ruby2.2. 准备rubygem redis依赖
$ sudo gem install redis
Password:
Fetching: redis-4.0.2.gem (100%)
Successfully installed redis-4.0.2
Parsing documentation for redis-4.0.2
Installing ri documentation for redis-4.0.2
Done installing documentation for redis after 1 seconds
1 gem installed2.3. 拷贝redis-trib.rb到集群根目录
redis-trib.rb 是redis官方推出的管理redis 集群的工具,集成在redis的源码src 目录下,将基于 redis提供的集群命令封装成简单、便捷、实用的操作工具。
$ sudo cp /usr/local/redis-4.0.11/src/redis-trib.rb /usr/local/redis-cluster查看 redis-trib.rb 命令环境是否正确,输出如下:
$ ./redis-trib.rb
Usage: redis-trib <command> <options> <arguments ...>
create host1:port1 ... hostN:portN
--replicas <arg>
check host:port
info host:port
fix host:port
--timeout <arg>
reshard host:port
--from <arg>
--to <arg>
--slots <arg>
--yes
--timeout <arg>
--pipeline <arg>
rebalance host:port
--weight <arg>
--auto-weights
--use-empty-masters
--timeout <arg>
--simulate
--pipeline <arg>
--threshold <arg>
add-node new_host:new_port existing_host:existing_port
--slave
--master-id <arg>
del-node host:port node_id
set-timeout host:port milliseconds
call host:port command arg arg .. arg
import host:port
--from <arg>
--copy
--replace
help (show this help)
For check, fix, reshard, del-node, set-timeout you can specify the host and port of any working node in the cluster.redis-trib.rb 是 redis 作者用 ruby 完成的。redis-trib.rb 命令行工具 的具体功能如下:
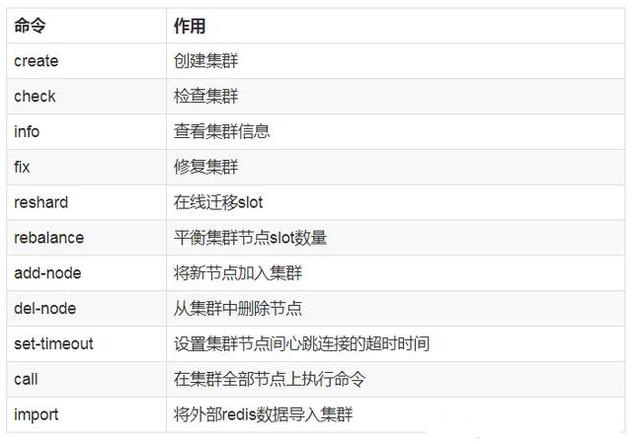
3、安装集群
3.1 启动redis服务节点
运行如下命令启动 6 台 redis 节点:
sudo redis-server conf/redis-6379.conf
sudo redis-server conf/redis-6389.conf
sudo redis-server conf/redis-6380.conf
sudo redis-server conf/redis-6390.conf
sudo redis-server conf/redis-6381.conf
sudo redis-server conf/redis-6391.conf启动完成后,redis 以集群模式启动,查看各个 redis 节点的进程状态:
$ ps -ef | grep redis-server
0 1908 1 0 4:59下午 ?? 0:00.01 redis-server *:6379 [cluster]
0 1911 1 0 4:59下午 ?? 0:00.01 redis-server *:6389 [cluster]
0 1914 1 0 4:59下午 ?? 0:00.01 redis-server *:6380 [cluster]
0 1917 1 0 4:59下午 ?? 0:00.01 redis-server *:6390 [cluster]
0 1920 1 0 4:59下午 ?? 0:00.01 redis-server *:6381 [cluster]
0 1923 1 0 4:59下午 ?? 0:00.01 redis-server *:6391 [cluster]在每个 redis 节点的 redis.conf 文件中,我们都配置了 cluster-config-file 的文件路径,集群启动时,conf 目录会新生成 集群 节点配置文件。查看文件列表如下:
$ tree -L 3 .
.
├── appendonly.aof
├── conf
│ ├── node-6379.conf
│ ├── node-6380.conf
│ ├── node-6381.conf
│ ├── node-6389.conf
│ ├── node-6390.conf
│ ├── node-6391.conf
│ ├── redis-6379.conf
│ ├── redis-6380.conf
│ ├── redis-6381.conf
│ ├── redis-6389.conf
│ ├── redis-6390.conf
│ └── redis-6391.conf
├── data
│ ├── redis-6379
│ ├── redis-6380
│ ├── redis-6381
│ ├── redis-6389
│ ├── redis-6390
│ └── redis-6391
├── log
│ ├── redis-6379.log
│ ├── redis-6380.log
│ ├── redis-6381.log
│ ├── redis-6389.log
│ ├── redis-6390.log
│ └── redis-6391.log
└── redis-trib.rb
9 directories, 20 files3.2 redis-trib关联集群节点
按照 从主到从 的方式 从左到右 依次排列 6 个 redis 节点。
$ sudo ./redis-trib.rb create --replicas 1 127.0.0.1:6379 127.0.0.1:6380 127.0.0.1:6381 127.0.0.1:6389 127.0.0.1:6390 127.0.0.1:6391集群创建后,redis-trib 会先将 16384 个哈希槽分配到3 个主节点,即 redis-6379,redis-6380 和 redis-6381。然后将各个 从节点 指向 主节点,进行数据同步。
>>> Creating cluster
>>> Performing hash slots allocation on 6 nodes...
Using 3 masters:
127.0.0.1:6379
127.0.0.1:6380
127.0.0.1:6381
Adding replica 127.0.0.1:6390 to 127.0.0.1:6379
Adding replica 127.0.0.1:6391 to 127.0.0.1:6380
Adding replica 127.0.0.1:6389 to 127.0.0.1:6381
>>> Trying to optimize slaves allocation for anti-affinity
[WARNING] Some slaves are in the same host as their master
M: ad4b9ffceba062492ed67ab336657426f55874b7 127.0.0.1:6379
slots:0-5460 (5461 slots) master
M: df23c6cad0654ba83f0422e352a81ecee822702e 127.0.0.1:6380
slots:5461-10922 (5462 slots) master
M: ab9da92d37125f24fe60f1f33688b4f8644612ee 127.0.0.1:6381
slots:10923-16383 (5461 slots) master
S: 25cfa11a2b4666021da5380ff332b80dbda97208 127.0.0.1:6389
replicates ad4b9ffceba062492ed67ab336657426f55874b7
S: 48e0a4b539867e01c66172415d94d748933be173 127.0.0.1:6390
replicates df23c6cad0654ba83f0422e352a81ecee822702e
S: d881142a8307f89ba51835734b27cb309a0fe855 127.0.0.1:6391
replicates ab9da92d37125f24fe60f1f33688b4f8644612ee然后输入 yes,redis-trib.rb 开始执行 节点握手 和 槽分配 操作,输出如下:
Can I set the above configuration? (type 'yes' to accept): yes
>>> Nodes configuration updated
>>> Assign a different config epoch to each node
>>> Sending CLUSTER MEET messages to join the cluster
Waiting for the cluster to join....
>>> Performing Cluster Check (using node 127.0.0.1:6379)
M: ad4b9ffceba062492ed67ab336657426f55874b7 127.0.0.1:6379
slots:0-5460 (5461 slots) master
1 additional replica(s)
M: ab9da92d37125f24fe60f1f33688b4f8644612ee 127.0.0.1:6381
slots:10923-16383 (5461 slots) master
1 additional replica(s)
S: 48e0a4b539867e01c66172415d94d748933be173 127.0.0.1:6390
slots: (0 slots) slave
replicates df23c6cad0654ba83f0422e352a81ecee822702e
S: d881142a8307f89ba51835734b27cb309a0fe855 127.0.0.1:6391
slots: (0 slots) slave
replicates ab9da92d37125f24fe60f1f33688b4f8644612ee
M: df23c6cad0654ba83f0422e352a81ecee822702e 127.0.0.1:6380
slots:5461-10922 (5462 slots) master
1 additional replica(s)
S: 25cfa11a2b4666021da5380ff332b80dbda97208 127.0.0.1:6389
slots: (0 slots) slave
replicates ad4b9ffceba062492ed67ab336657426f55874b7
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.执行 集群检查,检查各个 redis 节点占用的哈希槽(slot)的个数以及slot覆盖率。16384个槽位中,主节点 redis-6379、redis-6380 和 redis-6381 分别占用了 5461、5461 和 5462 个槽位。
3.3. redis主节点的日志
可以发现,通过 BGSAVE 命令,从节点 redis-6389 在 后台 异步地从 主节点 redis-6379 同步数据。
$ cat log/redis-6379.log
1907:C 05 Sep 16:59:52.960 # oO0OoO0OoO0Oo Redis is starting oO0OoO0OoO0Oo
1907:C 05 Sep 16:59:52.961 # Redis version=4.0.11, bits=64, commit=00000000, modified=0, pid=1907, just started
1907:C 05 Sep 16:59:52.961 # Configuration loaded
1908:M 05 Sep 16:59:52.964 * Increased maximum number of open files to 10032 (it was originally set to 256).
1908:M 05 Sep 16:59:52.965 * No cluster configuration found, I'm ad4b9ffceba062492ed67ab336657426f55874b7
1908:M 05 Sep 16:59:52.967 * Running mode=cluster, port=6379.
1908:M 05 Sep 16:59:52.967 # Server initialized
1908:M 05 Sep 16:59:52.967 * Ready to accept connections
1908:M 05 Sep 17:01:17.782 # configEpoch set to 1 via CLUSTER SET-CONFIG-EPOCH
1908:M 05 Sep 17:01:17.812 # IP address for this node updated to 127.0.0.1
1908:M 05 Sep 17:01:22.740 # Cluster state changed: ok
1908:M 05 Sep 17:01:23.681 * Slave 127.0.0.1:6389 asks for synchronization
1908:M 05 Sep 17:01:23.681 * Partial resynchronization not accepted: Replication ID mismatch (Slave asked for '4c5afe96cac51cde56039f96383ea7217ef2af41', my replication IDs are '037b661bf48c80c577d1fa937ba55367a3692921' and '0000000000000000000000000000000000000000')
1908:M 05 Sep 17:01:23.681 * Starting BGSAVE for SYNC with target: disk
1908:M 05 Sep 17:01:23.682 * Background saving started by pid 1952
1952:C 05 Sep 17:01:23.683 * DB saved on disk
1908:M 05 Sep 17:01:23.749 * Background saving terminated with success
1908:M 05 Sep 17:01:23.752 * Synchronization with slave 127.0.0.1:6389 succeeded3.4 redis集群完整性检测
使用 redis-trib.rb check 命令检测之前创建的 两个集群 是否成功,check 命令只需要给出集群中 任意一个节点地址 就可以完成 整个集群 的 检查工作,命令如下:
$ ./redis-trib.rb check 127.0.0.1:6379当最后输出如下信息,提示集群 所有的槽 都已分配到节点:
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.本文介绍了Redis集群解决方案,数据分布和集群搭建。
集群方案包括客户端分区方案,代理分区方案和查询路由方案。数据分布部分简单地对节点取余分区,一致性哈希分区以及虚拟槽分区进行了阐述和对比。
最后对使用 Redis-trib 搭建了一个 三主三从 的 虚拟槽集群示例。














 1321
1321











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









