





注:RL系列皆是莫烦教程的学习笔记,笔者仅做记录。
1.前言
本篇教程是基于Deep Q network(DQN)的教程,缩减了在DQN方面的介绍,着重强调Double DQN和DQN的不同之处。
接下来我们说说为什么会有Double DQN这种算法,所以我们从Double DQN相对于Natural DQN(传统DQN)的优势说起。
一句话概括,DQN基于Q-Learning,Q-Learning中有Qmax,Qmax会导致Q现实当中的过估计(overestimate)。而Double DQN就是用来解决出现的过估计问题的。在实际问题中,如果你输出你的DQN的Q值,可能就会发现,Q值都超级大,这就是出现了overestimate。
这次的Double DQN的算法实战基于的是OpenAI Gym中的Pendulum环境。以下是本次实战结果,目的是经过训练保持杆子始终向上:

2.算法
我们知道DQN的神经网络部分可以看成一个最新的神经网络+老神经网络,他们有相同的结构,但内部的参数更新却有时差(TD差分,老神经网络的参数是隔一段时间更新),而它的Q现实部分是这样的:
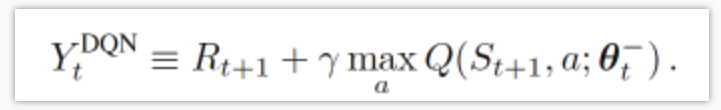
因为我们的神经网络预测Qmax本来就有误差,而每次更新也是向着最大误差的Q现实改进神经网络,就是因为这个Qmax导致了overestimate。所以Double DQN的想法就是引入另一个神经网络来打消一些最大误差的影响。而DQN中本来就有两个神经网络,所以我们就可以利用一下DQN这个地理优势。我们使用Q估计的神经网络估计Q现实中Qmax(s', a')的最大动作值。然后用这个被Q估计初级出来的动作来选择Q现实中的Q(s')。总结一下:
有两个神经网络:Q_eval(Q估计中的),Q_next(Q现实中的)。
原本的Q_next = max(Q_next(s', a_all))
而现在Double DQN 中的Q_next = Q_next(s', argmax(Q_eval(s', a_all))),也可以表达成下面那样

2.1更新方法
这里的代码都是基于之前的DQN中的代码,在RL_brain中,我们将class的名字改成DoubleDQN,为了对比Natural DQN,我们也保留原来大部分的DQN的代码。我们在init中加入一个double_q参数来表示使用的是Natural DQn还是Double DQN,为了对比的需要,我们的tf.Session()也单独传入,并移除原本在 DQN 代码中的这一句:self.sess.run(tf.global_variables_initializer())
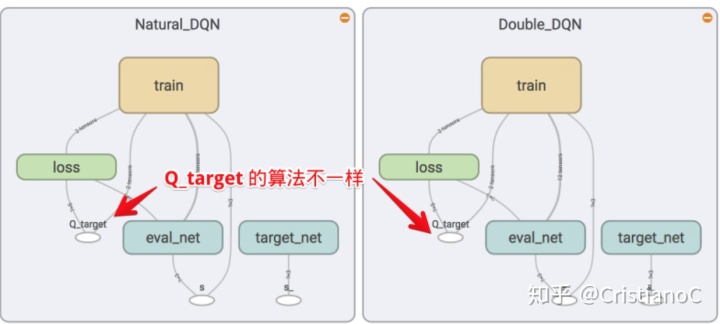
我们对比Double DQN和Natural DQN在tensorboard中的图,发现他们的结构并没有不同,但是在计算q_target(也就是Q现实)的时候,方法是不同的。
1class DoubleDQN:
2 def learn(self):
3 # 这一段和 DQN 一样:
4 if self.learn_step_counter % self.replace_target_iter == 0:
5 self.sess.run(self.replace_target_op)
6 print('ntarget_params_replacedn')
7
8 if self.memory_counter > self.memory_size:
9 sample_index = np.random.choice(self.memory_size, size=self.batch_size)
10 else:
11 sample_index = np.random.choice(self.memory_counter, size=self.batch_size)
12 batch_memory = self.memory[sample_index, :]
13
14 # 这一段和 DQN 不一样
15 q_next, q_eval4next = self.sess.run(
16 [self.q_next, self.q_eval],
17 feed_dict={self.s_: batch_memory[:, -self.n_features:], # next observation
18 self.s: batch_memory[:, -self.n_features:]}) # next observation
19 q_eval = self.sess.run(self.q_eval, {self.s: batch_memory[:, :self.n_features]})
20 q_target = q_eval.copy()
21 batch_index = np.arange(self.batch_size, dtype=np.int32)
22 eval_act_index = batch_memory[:, self.n_features].astype(int)
23 reward = batch_memory[:, self.n_features + 1]
24
25 if self.double_q: # 如果是 Double DQN
26 max_act4next = np.argmax(q_eval4next, axis=1) # q_eval 得出的最高奖励动作
27 selected_q_next = q_next[batch_index, max_act4next] # Double DQN 选择 q_next 依据 q_eval 选出的动作
28 else: # 如果是 Natural DQN
29 selected_q_next = np.max(q_next, axis=1) # natural DQN
30
31 q_target[batch_index, eval_act_index] = reward + self.gamma * selected_q_next
32
33
34 # 这下面和 DQN 一样:
35 _, self.cost = self.sess.run([self._train_op, self.loss],
36 feed_dict={self.s: batch_memory[:, :self.n_features],
37 self.q_target: q_target})
38 self.cost_his.append(self.cost)
39 self.epsilon = self.epsilon + self.epsilon_increment if self.epsilon < self.epsilon_max else self.epsilon_max
40 self.learn_step_counter += 1
2.2 记录Q值
为了记录下我们选择动作时的Q值,接下来我们就修改choose_action()功能,让他记录下每次选择的Q值。
1class DoubleDQN:
2 def choose_action(self, observation):
3 observation = observation[np.newaxis, :]
4 actions_value = self.sess.run(self.q_eval, feed_dict={self.s: observation})
5 action = np.argmax(actions_value)
6
7 if not hasattr(self, 'q'): # 记录选的 Qmax 值
8 self.q = []
9 self.running_q = 0
10 self.running_q = self.running_q*0.99 + 0.01 * np.max(actions_value)
11 self.q.append(self.running_q)
12
13 if np.random.uniform() > self.epsilon: # 随机选动作
14 action = np.random.randint(0, self.n_actions)
15 return action
2.3对比结果
接下来我们就来对比Natural DQN和Double DQN带来的不同结果,注意现在小棒子的动作是连续的,我们要把他离散化方便观看。
1import gym
2from RL_brain import DoubleDQN
3import numpy as np
4import matplotlib.pyplot as plt
5import tensorflow as tf
6
7
8env = gym.make('Pendulum-v0')
9env.seed(1) # 可重复实验
10MEMORY_SIZE = 3000
11ACTION_SPACE = 11 # 将原本的连续动作分离成 11 个动作
12
13sess = tf.Session()
14with tf.variable_scope('Natural_DQN'):
15 natural_DQN = DoubleDQN(
16 n_actions=ACTION_SPACE, n_features=3, memory_size=MEMORY_SIZE,
17 e_greedy_increment=0.001, double_q=False, sess=sess
18 )
19
20with tf.variable_scope('Double_DQN'):
21 double_DQN = DoubleDQN(
22 n_actions=ACTION_SPACE, n_features=3, memory_size=MEMORY_SIZE,
23 e_greedy_increment=0.001, double_q=True, sess=sess, output_graph=True)
24
25sess.run(tf.global_variables_initializer())
26
27
28def train(RL):
29 total_steps = 0
30 observation = env.reset()
31 while True:
32 # if total_steps - MEMORY_SIZE > 8000: env.render()
33
34 action = RL.choose_action(observation)
35
36 f_action = (action-(ACTION_SPACE-1)/2)/((ACTION_SPACE-1)/4) # 在 [-2 ~ 2] 内离散化动作
37
38 observation_, reward, done, info = env.step(np.array([f_action]))
39
40 reward /= 10 # normalize 到这个区间 (-1, 0). 立起来的时候 reward = 0.
41 # 立起来以后的 Q target 会变成 0, 因为 Q_target = r + gamma * Qmax(s', a') = 0 + gamma * 0
42 # 所以这个状态时的 Q 值大于 0 时, 就出现了 overestimate.
43
44 RL.store_transition(observation, action, reward, observation_)
45
46 if total_steps > MEMORY_SIZE: # learning
47 RL.learn()
48
49 if total_steps - MEMORY_SIZE > 20000: # stop game
50 break
51
52 observation = observation_
53 total_steps += 1
54 return RL.q # 返回所有动作 Q 值
55
56# train 两个不同的 DQN
57q_natural = train(natural_DQN)
58q_double = train(double_DQN)
59
60# 出对比图
61plt.plot(np.array(q_natural), c='r', label='natural')
62plt.plot(np.array(q_double), c='b', label='double')
63plt.legend(loc='best')
64plt.ylabel('Q eval')
65plt.xlabel('training steps')
66plt.grid()
67plt.show()
对比图:
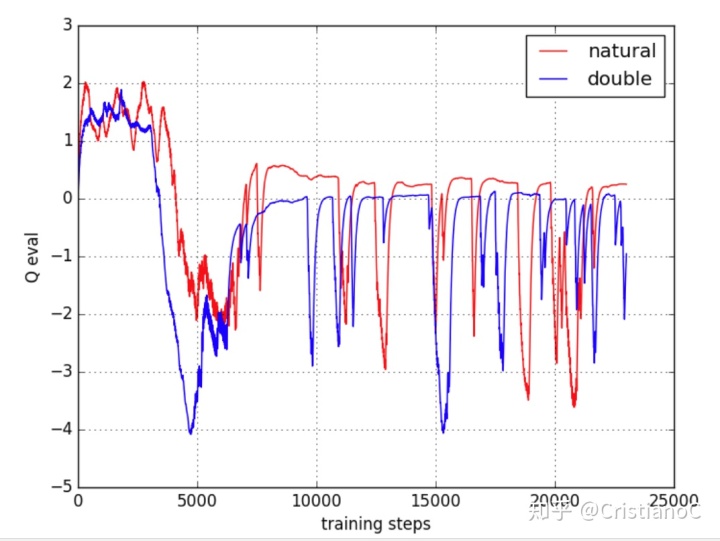
可以看出,Natural DQN学的差不多的时候,在立起来时,大部分时间都是 估计的 Q值 要大于0, 这时就出现了 overestimate, 而 Double DQN 的 Q值 就消除了一些 overestimate, 将估计值保持在 0 左右.(小部分还有超过0是因为初始化参数的时候是随机的)
完整代码:https://github.com/cristianoc20/RL_learning/tree/master/Double_DQN
参考:https://github.com/MorvanZhou
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









