





在前面两篇文章中,笔者已经介绍了两种聚类算法,同时还通过sklearn完成相应的示例。但是,到目前为止笔者还没有介绍如何来聚类的经过进行评估。这接下来的这篇文章中,笔者将会介绍在聚类算法中几种常见的评估指标,以及其中两种相应的原理。同时,如果不用关系其具体计算过程的,可以直接阅读第三部分即可。
如同之前介绍的其它算法模型一样,对于聚类来讲我们同样会通过一些评价指标来衡量聚类算法的优与劣。在聚类任务中,常见的评价指标有:准确率(Accuracy)、F值(F-score)、调整兰德系数(Adjusted Rand Index, ARI)和标准互信息素(Normalized Mutual Info, NMI),而这四种评价指标也是聚类相关论文中出现得最多的评价方法。下面,我们首先将对准去率和F值进行一个介绍,然后再对后面两个指标进行介绍。
1 准确率与F值
准确率与F值这两个评估指标相信大家听起来都不会感到陌生,因为我们在第一次介绍分类算法的时候已经介绍过了这两个指标。既然已经介绍过了为什么这里还要拿出来说呢?这是因为分类中的准确率和F值仅仅只是聚类中的某种情况而已,什么意思呢?
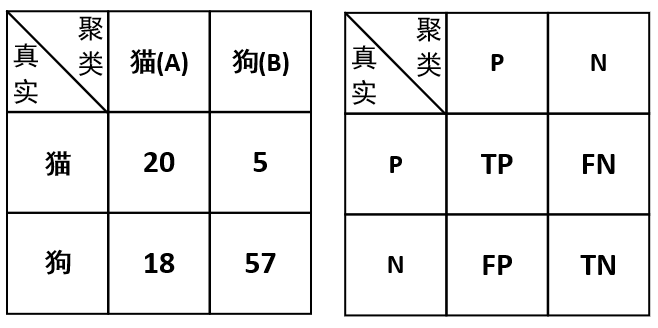
为了能够更加清楚的介绍这两种指标,我们还是以之前的猫狗图片识别的任务场景为例:假设我们现在有猫狗图片100张,其中猫又25张,狗有75张。现在我们通过某种聚类算法对其进行聚类,聚类的结果为簇A中有38张图片(其中20张猫18张狗),簇B中有62张图片(其中5张猫57张狗)。那么请问如何计算该聚类算法的准确率与F值?
由于聚类算法只会将原始数据样本划分为K个簇,但是并不会告诉我们每个簇分别对应那个类别。正如上述聚类结果一样,聚类算法只将这100张图片聚成了A、B两个簇,但是我们并不知道到底是簇A和簇B与猫狗的对应关系。因此,我们在计算准确率的时候就要分两种情况来考虑。
1.1 计算准确率
- 情况一:将簇A认为是猫,将簇B认为是狗
在这种假定情况下,我们将得到如下一个混淆矩阵:
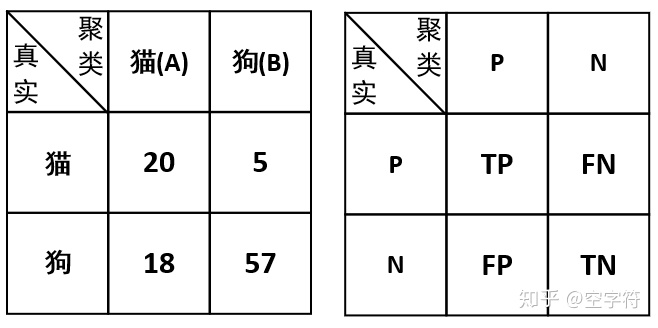
因此,根据这个混淆矩阵我们便能够计算出对应的准确率为:
- 情况二:将簇A认为是狗,将簇B认为是猫
在这种假定情况下,我们将得到另外一个混淆矩阵:
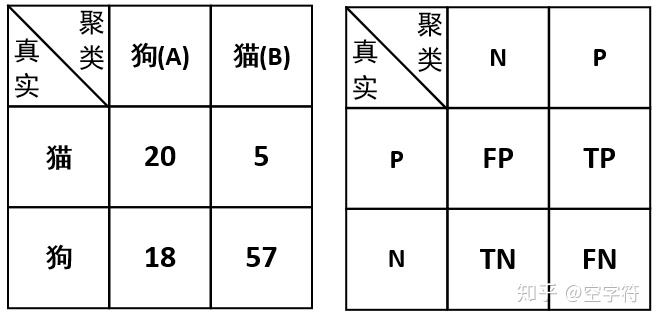
因此,根据这个混淆矩阵我们便能够计算出对应的准确率为:
由此我们发现,在不同情况下计算得到的准确率是不一样的,那我们最终应该选择哪个呢?当然是选择最高的,因为它才能真正代表聚类算法的聚类准确率。故,对于聚类算法来说,准确率可以看作是算法对簇划分准确度的一个评估指标。由此可知,我们在计算聚类结果的准确率时,应该分情况进行计算,然后选择最大值。
1.2 计算F值
有了上面计算准确率过程的铺垫,同理可知在不同情况下也会对应有不同的准确率与召回率,因此也就会得到不同的F值。具体的,
- 对于情况一来说,猫狗对应的精确率为:
召回率为:
F值为:
- 对于情况二来说,猫狗对应的精确率为:
召回率为:
F值为:
到此我们就分别计算出了两种情况下猫狗对应的F值,那我们应该选择哪种情况呢?自然的第一种情况对吧。但是由于不同类别都会对应有一个F值,那应该怎么来计算得到整体的F值呢?由于不同类别的数据样本在总样本中的占比不同,因此我们可以根据每个类别在总样本中的占比来加权得到F值,即:
因此对于本次聚类结果来说,其最终的准确率为
2 ARI与NMI
调整兰德系数是兰德系数的一个改进版本,总的来说兰德系数是通过计算两个簇之间的相似度来对聚类结果进行评估。而调整兰德系数是对兰德系数基于几率正则化的一种改进。至于标准互信息素,它也是基于互信息素的一种改进,总的来说互信息素也是用来衡量两种聚类结果(标签)之前相似程度的一个指标。关于这两种评价指标的具体计算方法在这里就先不进行介绍了,因为笔者自己也并不清楚,只是作为拿来主义直接进行使用的。下面分别是ARI和NMI的使用示例:
from sklearn.metrics.cluster import adjusted_rand_score
from sklearn.metrics.cluster import normalized_mutual_info_score
if __name__ == '__main__':
y_true = [0, 0, 0, 1, 1, 1]
y_pred = [0, 0, 1, 1, 2, 2]
ARI = adjusted_rand_score(y_true,y_pred)
NMI = normalized_mutual_info_score(y_true,y_pred)
print("ARI: {}, NMI: {}".format(ARI,NMI))
#结果:
ARI: 0.24242424242424246, NMI: 0.5158037429793889jj
其中ARI的取值范围为
3 使用方法
由于笔者之前曾做过一些关于聚类方面的工作,用的也是上述四种评价指标。因此,在这里就直接给大家贴出一份整合四项指标的一份代码[2],如果有需要直接调用即可。
- ARI与NMI
对于这两种评估指标,示例中的代码也是直接调用的sklearn中的方法
NMI = normalized_mutual_info_score(y_true, y_pred)
ARI = adjusted_rand_score(y_true, y_pred) - 准确率和F值
对于这两种指标,很遗憾sklearn中并没有实现。笔者当时也是参考了一份基于matlib的代码改写而来,但是现在找不到代码出处了,所以也就无法加上引用了,在此表示感谢。
if __name__ == '__main__':
y_true = [0] * 20 + [1] * 18 + [1] * 57 + [0] * 5
y_pred = [0] * 38 + [1] * 62
metrics = Metrics(y_true, y_pred)
fsc, acc, nmi, ari = metrics.getFscAccNmiAri()
print("Fscore:{} , Accuracy:{}, NMI:{}, ARI:{}".format(fsc, acc, nmi, ari))
#结果:
Fscore:0.7828177499710347 , Accuracy:0.77, NMI:0.20491462701724053, ARI:0.27600559939546343
如上代码所示便是对类Metrics调用的示例,通过getFscAccNmiAri()方法我们就能够一次得到四种指标的评估结果。
4 总结
在本篇文章中,笔者首先介绍了四种常见的聚类评价指标,包括准确率、F值、调整兰德系数和调整互信息素;同时笔者还就前两种指标的原理和计算过程进行了说明;最后,笔者还对这四种指标进行了整合,通过调用类Metrics中的``getFscAccNmiAri()`方法即可一次得到四项评估结果。本次内容就到此结束,感谢阅读!
若有任何疑问与见解,请发邮件至moon-hotel@hotmail.com并附上文章链接,青山不改,绿水长流,月来客栈见!
引用
[1]https://scikit-learn.org/stable/modules/clustering.html#clustering-evaluation
[2]示例代码 : https://github.com/moon-hotel/MachineLearningWithMe
近期文章
[1]Kmeans聚类算法
[2]Kmeans聚类算法求解与实现
[3]Kmeans++聚类算法














 3472
3472











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









