





这篇是在前一篇的基础上,因为PHP的数组在进行['key':'value']的存储时,也同样是使用x33算法做的,因此,可以使用前一篇的方法构造冲突串。这一篇的目的,其实更重要的是理解PHP数组——面试PHP的时候可能会用得上。
首先看一下PHP数据的使用和实现。
PHP 中的数组是一种强大且灵活的数据类型。首先看一下基本的使用。
// 可以使用数字下标的形式定义数组
$arr= ['Mike', 2 => 'JoJo'];
echo $arr[0], $arr[2]; 它的效果是在$arr[0]中存放了'Mike',$arr[1]空缺,$arr[1]中存放了'JoJo'。
使用var_dump($arr)可以得到
array(2) { [0]=> string(4) "Mike" [2]=> string(4) "JoJo" } 也可以使用字符串下标定义数组 :
$arr = ['name' => 'Mike', 'age' => 22]; 得到的结果:
array(2) { ["name"]=> string(4) "Mike" ["age"]=> int(22) } 可以顺序读取数组中的数据
foreach ($arr as $key => $value) {
echo $key,":",$value,"<br>";
}
echo current($arr);
echo next($arr);
// 也可以随机读取数组中的数据
$arr = ['name' => 'Mike', 'age' => 22];
echo $arr['name'];
// 数组的长度是可变的 $arr = [1, 2, 3];
$arr[] = 4;
array_push($arr, 5);
基于这些特性,我们可以很轻易的使用 PHP 中的数组实现集合、栈、列表、字典等多种数据结构。
在了解了PHP数组的基本使用之后,来看一段代码:
$arr = array();
$arr[0] = 0;
$arr[1] = 1;
$arr= array('name' => 'Mike', 'age' => 22,5 => "mary",6=>"alice" );
$b = array_values($arr);
foreach ($arr as $key => $value) {
echo $key,":", $arr[$key], "<br>";
}
foreach ($b as $key => $value) {
echo $key,":", $b[$key], "<br>";
}
分析一下,以上代码的输出是什么呢?
name:Mike
age:22
5:mary
6:alice
0:Mike
1:22
2:mary
3:alice这里要注意的是,最开始的两个赋值,
$arr[0] = 0;
$arr[1] = 1;被后面的覆盖了。
再看一段:
$arr = array(1,2,3,4,5);
$arr['name'] = "mary";
$arr['first'] = "second";
$b = array_values($arr);
foreach ($arr as $key => $value) {
echo $key,":", $arr[$key], "<br>";
}
foreach ($b as $key => $value) {
echo $key,":", $b[$key], "<br>";
}
输出是:
0:1
1:2
2:3
3:4
4:5
name:mary
first:second
0:1
1:2
2:3
3:4
4:5
5:mary
6:second【array_values() 函数返回一个包含给定数组中所有键值的数组,但不保留键名。被返回的数组将使用数值键,从 0 开始并以 1 递增。】
那么再看下面一段代码:
$arr = array('name'=>'Mary','first'=>'Alice','last'=>'Smith','Age'=>'20');
$arr[0] = 0;
$arr[1] = 1;
$b = array_values($arr);
foreach ($arr as $key => $value) {
echo $key,":", $arr[$key], "<br>";
}
foreach ($b as $key => $value) {
echo $key,":", $b[$key], "<br>";
}
预期的结果是什么呢?下面的结果和预期是否一致呢?
name:Mary
first:Alice
last:Smith
Age:20
0:0
1:1
0:Mary
1:Alice
2:Smith
3:20
4:0
5:1从上面的结果我们可以看出PHP数组的重要特性:它既支持键值对数组,也即使用map的方法将键映射到整型的Index,同时还保存了一部分的顺序性——也即,数组在存放的时候是按照赋值的顺序保存的。
另外再看一个删除元素的代码:
<?php
// 创建一个简单的数组
$array = array(1, 2, 3, 4, 5);
print_r($array);
// 现在删除其中的所有元素,但保持数组本身不变:
foreach ($array as $i => $value) {
unset($array[$i]);
}
print_r($array);
// 添加一个单元(注意新的键名是 5,而不是你可能以为的 0)
$array[] = 6;
print_r($array);
// 重新索引:
$array = array_values($array);
$array[] = 7;
print_r($array);
?>以上代码的输出是:
Array
(
[0] => 1
[1] => 2
[2] => 3
[3] => 4
[4] => 5
)
Array
(
)
Array
(
[5] => 6
)
Array
(
[0] => 6
[1] => 7
)
在unset的时候,元素并没有真正删除(导致数组中的元素重新建立索引),而仅仅是将原素设置为undefined;当使用array_values()的时候会真正进行元素重新建立索引。
那么,什么样的底层实现可以达到这样的效果呢?
如果对之前的内容有足够的了解,那么就应该知道为了实现键值对存储,肯定使用了hashtable;和之前的介绍不同的是,为了实现顺序性,PHP使用了两个数组,一个是用来存储值,一个是用来进一步存储哈希的结果与存储位置的对应关系,也即多了一个中间映射表。
对比一下:
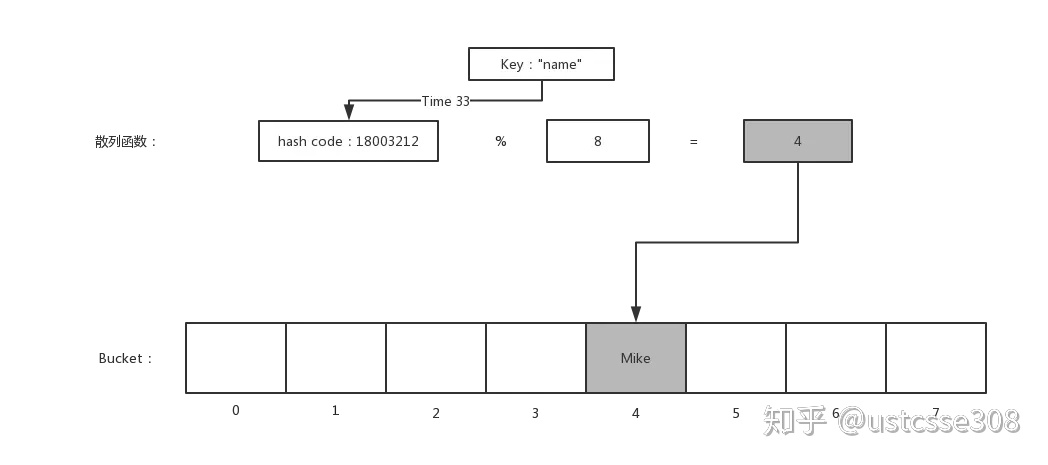
上图是一次哈希的,也即直接根据X33的结果,对数组的大小取模,然后值就存在所得到的模所对应的位置。
PHP中的做法是这样的:
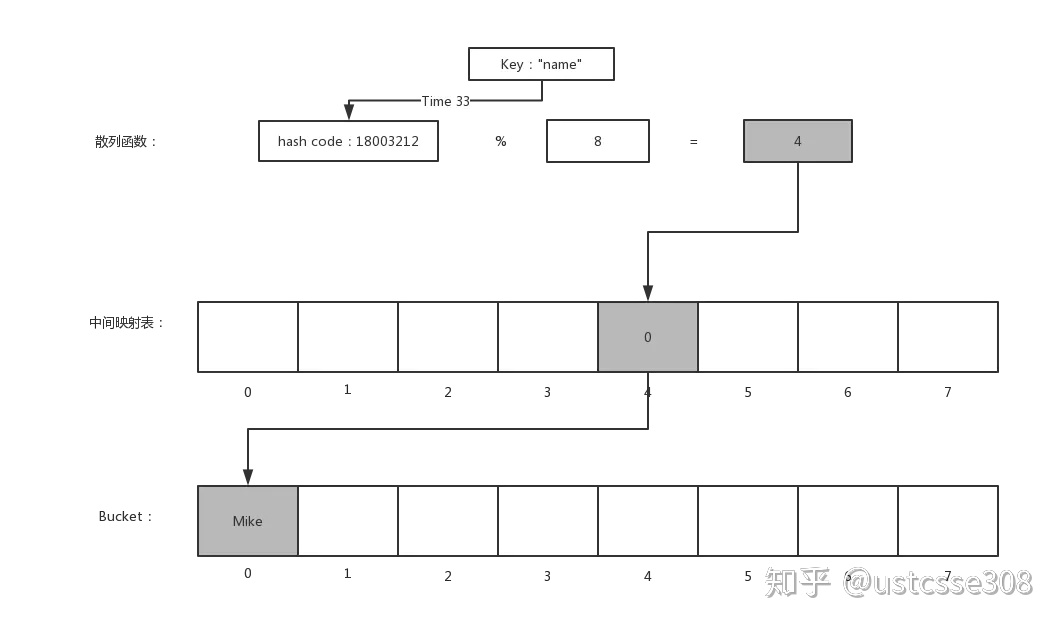
在上面的图中,可以看到在获得了“name”这个键的哈希4之后,这个4被用在中间映射表中,然后在中间映射表的4的位置,存放的是存放真正的值的bucket数组的位置0(之所以为0是因为 name => mike是目前插入的第一个键值对)。
实际上,中间映射表和Bucket是相邻的一块连续内存。zend_array 中并没有单独定义中间映射表,而是将其与 arData 放在一起,数组初始化时并不只分配 Bucket 大小的内存,同时还会分配相同大小空间的数据来作为中间映射表,其实现方式如图:
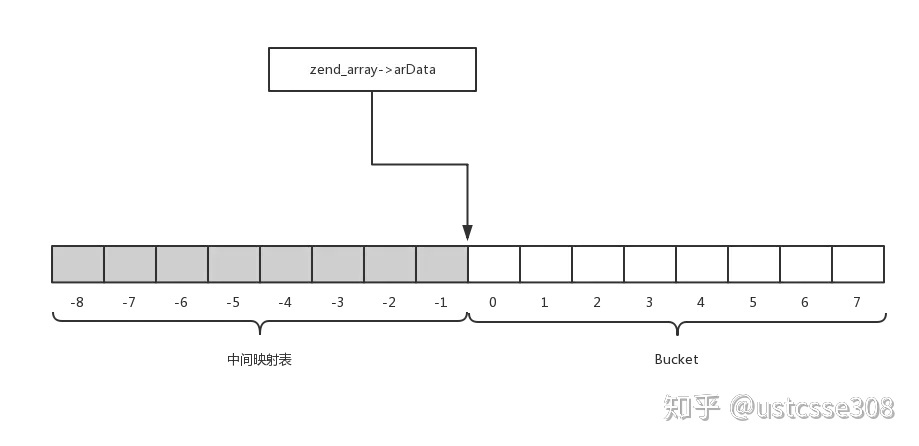
正如在一次哈希的过程中,需要使用对数组大小求余来找到具体的位置一样,PHP 中也需要做X33的结果进行一次处理来找到在中间映射表中的位置,采用如下方式对 hash code 进行散列:
nIndex = key->h | nTableMask;这里有一个新的变量nTableMask。将哈希值和nTableMask进行或运算即可得出映射表的下标,其中nTableMask数值为nTableSize的负数。并且由于nTableSize的值为 2 的幂次方,所以key->h | nTableMask的取值范围在 [nTableMask, -1]之间,正好在映射表的下标范围内。本质上它就是求余,那为什么不直接使用简单的「取余」呢?而是这么麻烦地采用「按位或」运算呢?因为「按位或」运算的速度要比「取余」运算要快。PHP对与改进性能还是很注意的。
接下来看一下哈希冲突。
任何散列函数都会出现哈希冲突的问题,常见的解决哈希冲突的方法有以下几种:
- 开放定址法
- 链地址法
- 重哈希法
PHP 采用的是其中的链地址法,将冲突的 Bucket 串成链表,这样中间映射表映射出的就不是某一个元素,而是一个 Bucket 链表,通过散列函数定位到对应的 Bucket 链表时,需要遍历链表,逐个对比 Key 值,继而找到目标元素。
新元素 Hash 冲突时的插入分为以下两步:
- 将旧元素的下标储存到新元素的
next中 - 将新元素的下标储存到中间映射表中
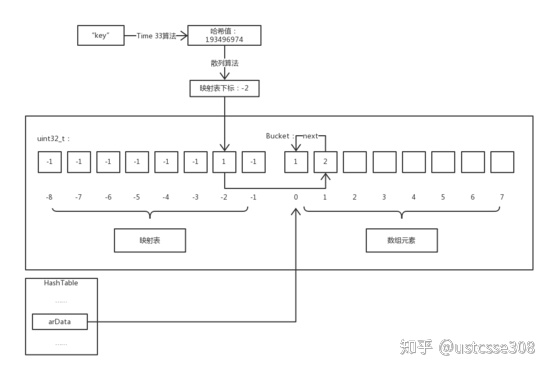
上图中假设存储了两个键值对,key1=>1;key2=>2; 并且X33时,key1和key2冲突。当存储key1=>1时,hash['key1']的结果是-2,然后中间映射表中-2这个位置存放了0,也即在bucket中的位置0处,存放了key1对应的value 1。当存放key2=>2的时候,计算出来得到中间映射表的值同样是-2,此时,将-2中原始存放的0放在key2=>2的元素的val.u2.next中,然后把-2中的值更新为1。也即,在bucket的位置1处存放了key2对应的value 2,同时value 2的val.u2.next中存放的上一个冲突的键值对存放的位置。
此时访问$a['key1']的过程多了一些步骤。首先通过散列运算得出映射表下标为 -2 ,然后访问映射表发现其内容指向bucket数组中下标为 1 的元素。该元素的key和要访问的键名相比较,发现两者并不相等,意味着发生了冲突,该元素并非我们所想访问的元素,而该元素的val.u2.next保存的值正是下一个具有相同散列值的元素对应bucket数组的下标,所以我们可以不断通过next的值遍历直到找到键名相同的元素或查找失败。
总结一下查找过程:
HashTable 中的查找过程其实已经在上面说完了:
- 使用 x33 算法对 key 值计算得到hash code
- 使用散列函数计算 hash code 得到散列值 nIndex,即元素在中间映射表的下标
- 通过 nIndex 从中间映射表中取出元素在 Bucket 中的下标 idx
- 通过 idx 访问 Bucket 中对应的数组元素,该元素同时也是一个静态链表的头结点
- 遍历链表,分别判断每个元素中的 key 值是否与我们要查找的 key 值相同
- 如果相同,终止遍历
扩容
在 C 语言中,数组的长度是定长的,那么如果空间已满还需继续插入的时候怎么办呢?PHP 的数组在底层实现了自动扩容机制,当插入一个元素且没有空闲空间时,就会触发自动扩容机制,扩容后再执行插入。
需要提出的一点是,当删除某一个数组元素时,会先使用标志位对该元素进行逻辑删除,而不会立即删除该元素所在的 Bucket,因为后者在每次删除时进行一次排列操作,从而造成不必要的性能开销。
扩容的过程为:
- 如果已删除元素所占比例达到阈值,则会移除已被逻辑删除的 Bucket,然后将后面的 Bucket 向前补上空缺的 Bucket,因为 Bucket 的下标发生了变动,所以还需要更改每个元素在中间映射表中储存的实际下标值。
- 如果未达到阈值,PHP 则会申请一个大小是原数组两倍的新数组,并将旧数组中的数据复制到新数组中,因为数组长度发生了改变,所以 key-value 的映射关系需要重新计算,这个步骤为重建索引。
PHP数组最小容量是8(2^3),最大容量是0×80000000(2^31),并向2的整数次幂圆整(即长度会自动扩展为2的整数次幂,如13个元素的哈希表长度为16;100个元素的哈希表长度为128)。
ZEND_API int _zend_hash_init(HashTable *ht, uint nSize, hash_func_t pHashFunction, dtor_func_t pDestructor, zend_bool persistent ZEND_FILE_LINE_DC)
{
uint i = 3;
Bucket **tmp;
SET_INCONSISTENT(HT_OK);
//长度向2的整数次幂圆整
if (nSize >= 0x80000000) {
/* prevent overflow */
ht->nTableSize = 0x80000000;
} else {
while ((1U << i) < nSize) {
i++;
}
ht->nTableSize = 1 << i;
}
ht->nTableMask = ht->nTableSize - 1;
......
return SUCCESS;好,基础介绍完毕。
攻击:
那么要对PHP的数组发起DOS攻击,思路和之前是一样的,也即需要让它失去hashtable本身快速检索的性能,让它遇到最坏情况,达到100%碰撞,所有的key都塞进一个bucket里去,hashtable就变成了一个长链表。此时的链表查询就变成了顺序查找,复杂度大大增加。
一种最简单的方法是利用掩码规律制造碰撞。上文提到Zend HashTable的长度nTableSize会被圆整为2的整数次幂,假设我们构造一个2^16的哈希表,则nTableSize的二进制表示为:1 0000 0000 0000 0000,而nTableMask = nTableSize – 1为:0 1111 1111 1111 1111。接下来,可以以0为初始值,以2^16为步长,制造足够多的数据,可以得到如下推测:
0000 0000 0000 0000 0000 & 0 1111 1111 1111 1111 = 0
0001 0000 0000 0000 0000 & 0 1111 1111 1111 1111 = 0
0010 0000 0000 0000 0000 & 0 1111 1111 1111 1111 = 0
0011 0000 0000 0000 0000 & 0 1111 1111 1111 1111 = 0
0100 0000 0000 0000 0000 & 0 1111 1111 1111 1111 = 0
……
概况来说只要保证后16位均为0,则与掩码位于后得到的哈希值全部碰撞在位置0。
【16也可以是其他的数字;因为mask的位数必定全部为1,所以只要key的值本身足够大,后面的位上的值都相同,那么必然会造成冲突】
看一下攻击代码:
<?php
/**
* Created by PhpStorm.
* User: FZF
* Date: 2018/12/16
* Time: 17:13
*/
header("Content-Type: text/html; charset=utf-8");
$size = pow(2, 16);
$len =0;
$startTime = microtime(true);
$array = array();
$flag = 3;
for ($key = 0, $maxKey = ($size - 1) * $size; $key <= $maxKey; $key += $size) {
$array[$key] = 0;
$len = count($array);
if($temp < 20000){
$temp++;
}
else
break;
}
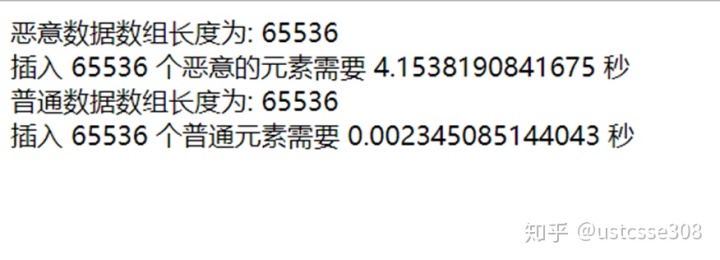
echo "恶意数据数组长度为: ".$len."<br>";
$endTime = microtime(true);
echo '插入 ', $size, ' 个恶意的元素需要 ', $endTime - $startTime, ' 秒', "<br>";
echo "<br><br>";
$startTime = microtime(true);
$array = array();
for ($key = 0, $maxKey = $size - 1; $key <= $maxKey; ++$key) {
$array[$key] = 0;
$len = count($array);
}
echo "普通数据数组长度为: ".$len."<br>";
$endTime = microtime(true);
echo '插入 ', $size, ' 个普通元素需要 ', $endTime - $startTime, ' 秒', "<br>";
?>上述代码来自18级同学;
结果如下:
参考:
- https://juejin.im/post/5bce1c35518825781f7b0935
- https://www.codercto.com/a/25717.html
- https://blog.knownsec.com/2015/08/php-7-zend_hash_if_full_do_resize-use-after-free-analysis/
- https://www.php.cn/php-notebook-93962.html
- http://www.vlambda.com/wz_wxi2HnzUkj.html
- http://www.zzvips.com/article/44683.html
- https://www.php.net/manual/zh/language.types.array.php
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









