一次性付费进群,长期免费索取教程,没有付费教程。
进微信群回复公众号:微信群;QQ群:460500587
教程列表
见微信公众号底部菜单 |
本文底部有推荐书籍

微信公众号:计算机与网络安全
ID:Computer-network
在使用爬虫抓取有效数据时,有些网站用Python并不能直接获取数据。有的是需要指定User-Agent的信息(Python默认会声明自己为Python脚本),有的是需要cookie数据,还有的网站因为一些缘故无法直接访问的还需要加上代理,这时就需要在Pyspider中添加、修改headers数据加上代理,然后向服务器提出请求。相比Scrapy而言,Pyspider修改headers,添加代理更加方便简洁。毕竟Scrapy还需要修改中间件,而Pyspider更加类似bs4,直接在源码中修改就可以达到目的。
1、项目分析
以音悦台网站为目标,在音悦台中获取实时动态的音乐榜单。音悦台中的实时动态榜单有5个,这里只爬内地篇的榜单,如图1所示。
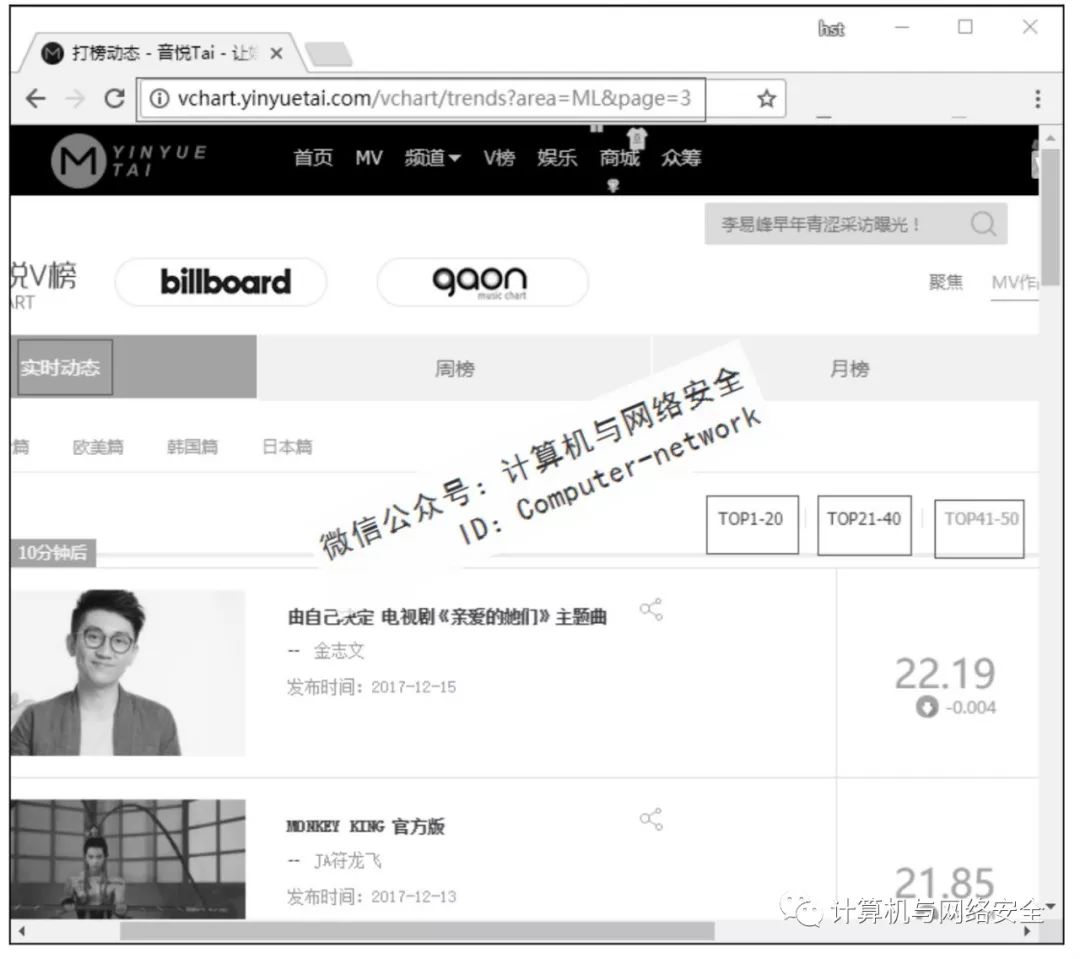
图1 音悦台实时榜单内地篇
从图1中可以看出,这个实时的榜单有3页,共50首歌曲。只需要获取当前榜单的歌曲名、歌手名、评分以及当前排名就可以了。打开页面编码,找到所需数据的位置,如图2所示。
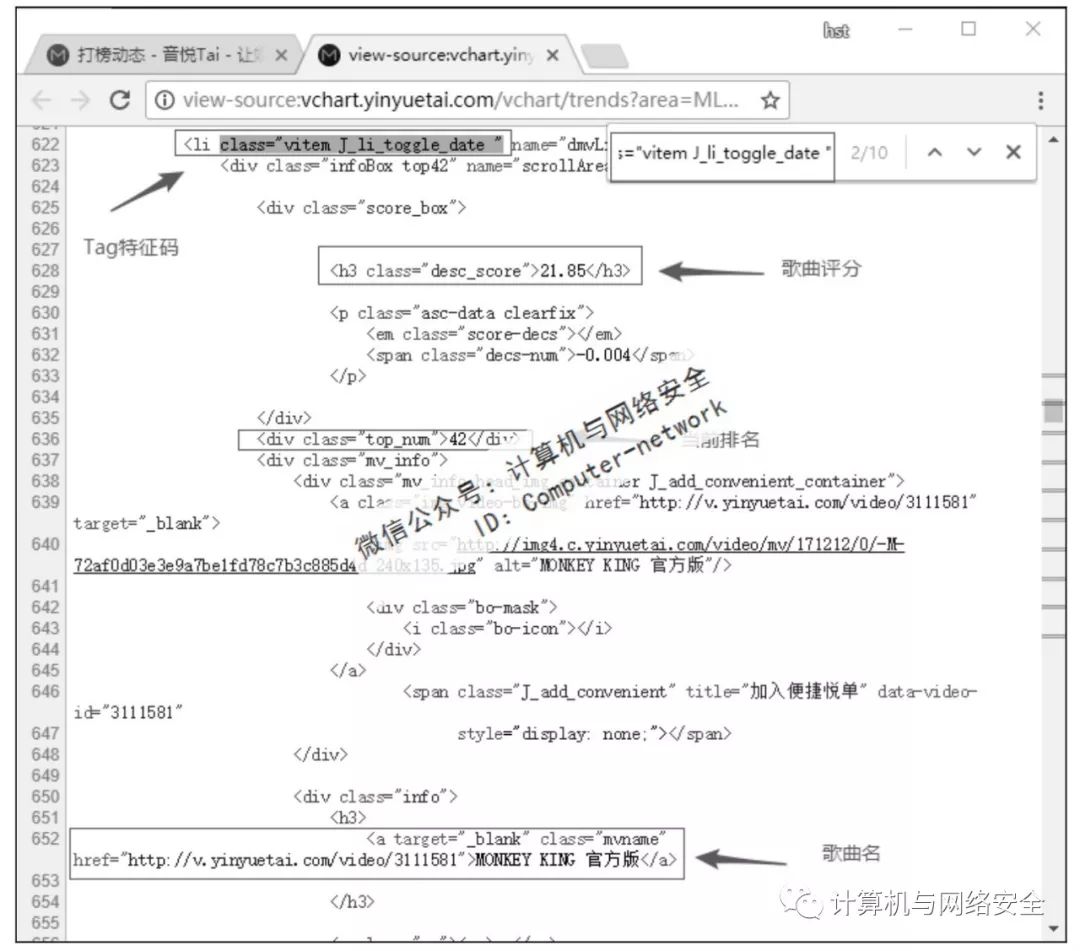
图2 榜单源码
爬虫
所需的所有数据都在这个标签里,只需要定位一次,就可以得到所有数据了。
2、爬虫编写
这个页面写得非常标准,可以很容易地根据特征标签获取到想要的数据,该爬虫的alpha版本如图3所示。
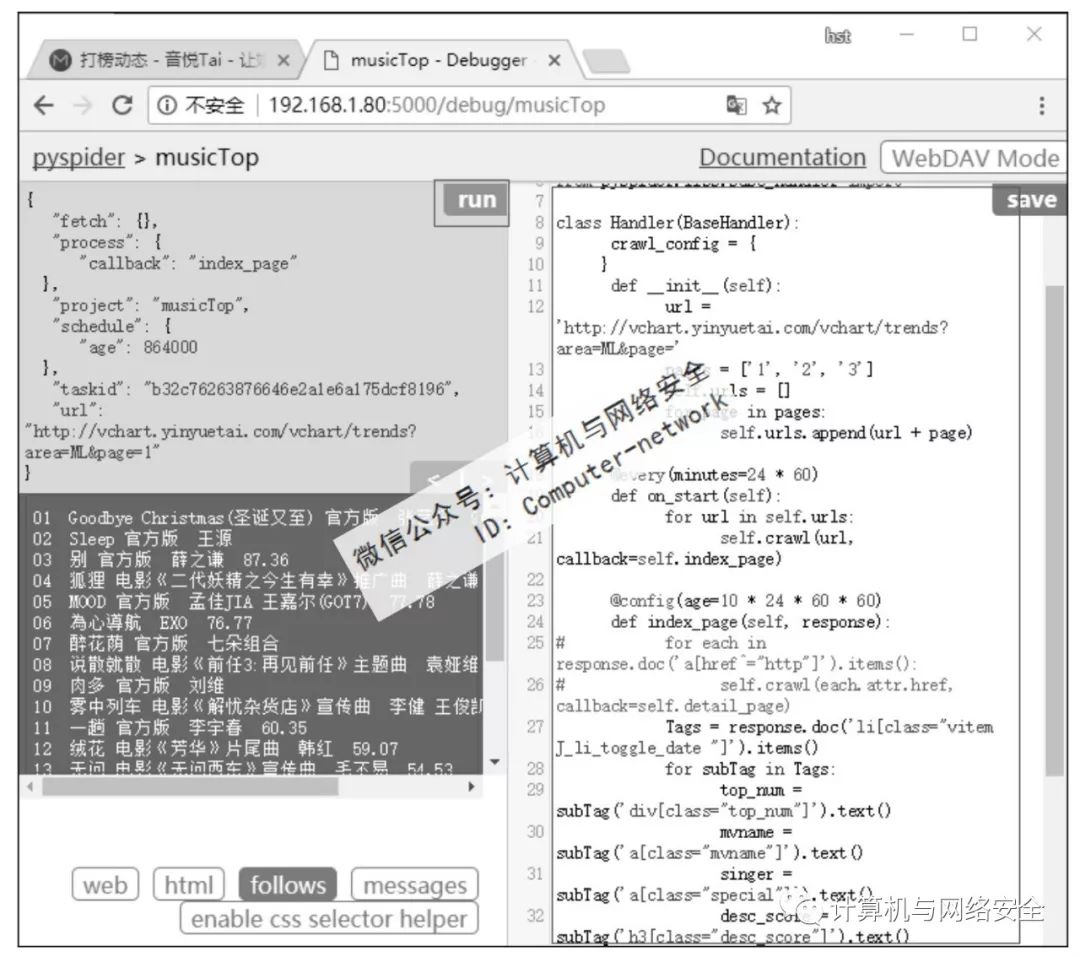
图3 测试alpha版爬虫
单击网页左侧页面预览区右上方的Run按钮测试一下。如图3所示,爬虫运行正常。现在为这个爬虫加上headers和proxy(通常为爬虫加载headers和proxy是因为页面不能返回数据或者是为了反爬虫需要,本例中页面是可以正常返回的,加载headers和proxy只是为了做演示)。为爬虫加载headers和proxy很简单,只需要在crawl_config中添加相应的值就可以了。一般情况下headers中只需要添加User-Agent就可以了,但有的网页也许会限制比较严格,这里添加的headers比较详细。Proxy只需要给一个可以使用的代理就可以了。单击左侧页面预览区右上方的Run按钮测试一下,如图4所示。
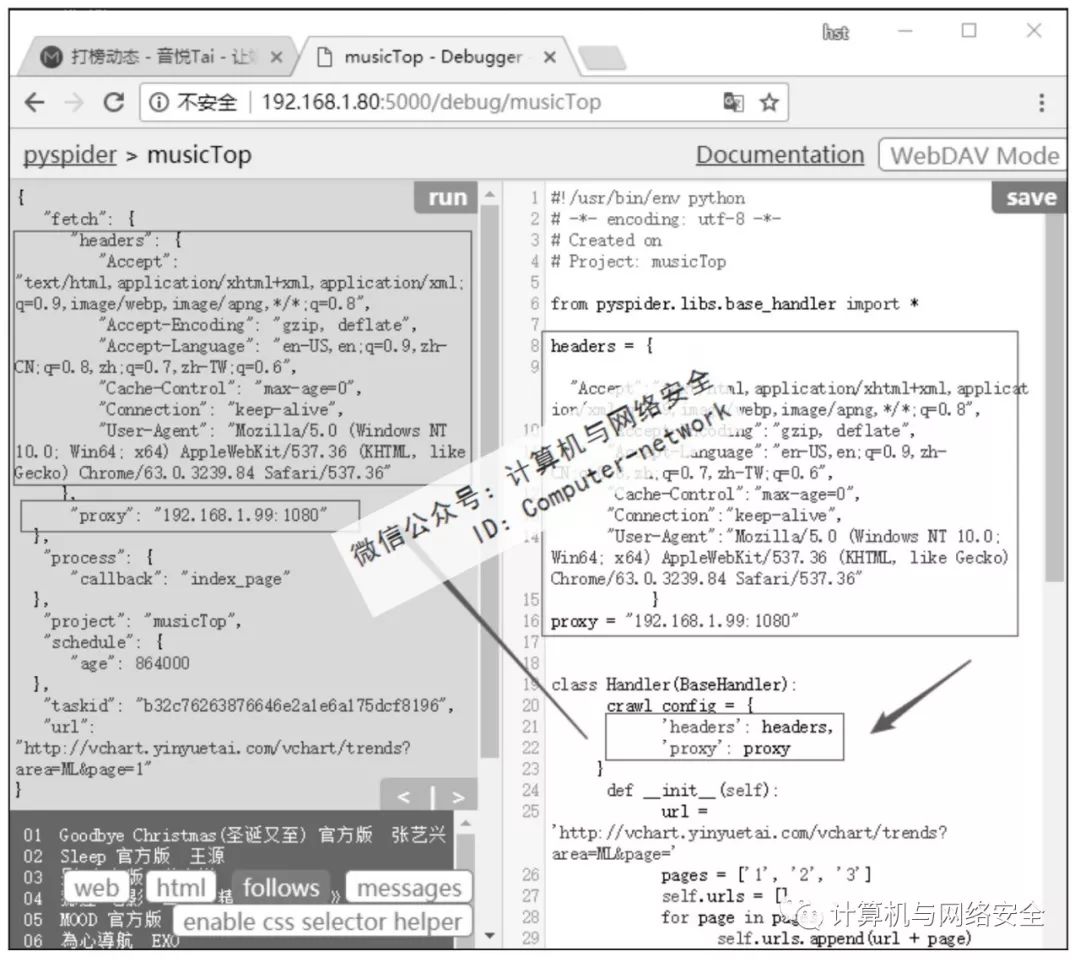
图4 测试beta版爬虫
在浏览器中可以打开页面而爬虫无法得到数据,一般加载headers就可以解决问题了。浏览器需要使用proxy才能打开的页面,爬虫也需要加载proxy才能得到数据。如果网站中设置了反爬虫,过滤频繁发送请求的IP的情况下怎么办呢?正常的应对方法是使用多个代理服务器进行轮询。通过网络搜索得到为Pyspider加载多个代理的方法是使用squid轮询。这种方法是可以,但需要安装squid软件,而且squid设置起来也比较麻烦。这里采用更加简单的方法,只要在爬虫发送请求的部位,随机地从代理池中挑选一个代理就可以了(按顺序挑选也可以,这就相当于代理的轮询了)。因此,爬虫最终版本omega版的代码如下:
1 #!/usr/bin/env python
2 # -*- encoding: utf8 -*-
3 # Created on
4 # Project: musicTop
5 from pyspider.libs.base_handler import *
6 import random
7 header={
8 "Accept":"text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",
9 "Accept-Encoding":"gzip,deflate",
10 "Accept-Language":"en-US,en;q=0.9,zh-CN;q=0.8,zh;q=0.7,zh-TW;q=0.6",
11 "Cache-Control":"max-age=0",
12 "Connection":"keep-alive",
13 "User-Agent":"Mozilla/5.0(Windows NT 10.0;Win64;x64)AppleWebKit/537.36(KHTML,like Gecko)Chrome/63.0.3239.84 Safari/537.36"
14 }
15 proxyList=["19.168.1.99:1080","101.68.73.54:53281",""]
16 class Handler(BaseHandler):
17 crawl_config={
18 # "proxy":proxy,
19 # "headers":headers
20 }
21 def __init__(self):
22 url='http://vchart.yinyuetai.com/vchart/trends?area=ML&page='
23 pages=['1','2','3']
24 self.urls=[]
25 for page in pages:
26 self.urls.append(url+page)
27 @every(minutes=24*60)
28 def on_start(self):
29 for url in self.urls:
30 self.crawl(url,callback=self.index_page,
31 proxy=random.choice(proxyList),headers=headers)
32 @config(age=10*24*60*60)
33 def index_page(self,response):
34 # for each in response.doc('a[href^="http"]').items():
35 # self.crawl(each.attr.href,callback=self.detail_page)
36 Tags=response.doc('li[]').items()
37 for subTag in Tags:
38 top_num=subTag('div[]').text()
39 mvname=subTag('a[]').text()
40 singer=subTag('a[]').text()
41 desc_score=subTag('h3[]').text()
42 print('%s %s %s %s' %(top_num,mvname,singer,desc_score))
43 @config(priority=2)
44 def detail_page(self,response):
45 return {
46 "url":response.url,
47 "title":response
.doc('title').text(),
48 }
当前爬虫只有index_page函数需要发送请求,因此,只需要在回调这个函数时随机挑选一个代理加入参数就可以了。
单击爬虫页面左侧预览栏右上方的Run按钮测试一下,结果如图5所示。
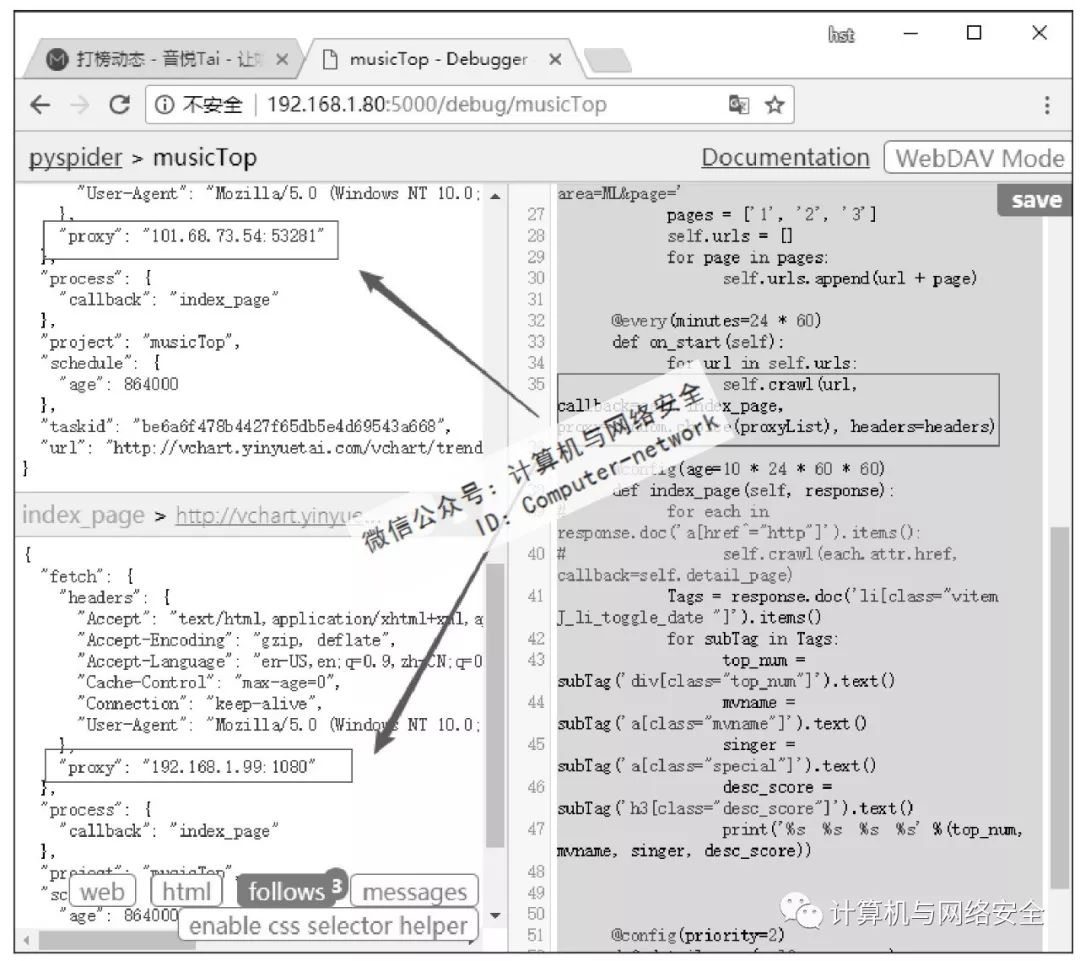
图5 爬虫轮询代理
这里需要注意的是,代理池中的所有代理必须是可靠可用的。
为了安全起见,可以在爬虫中添加一个测试程序,在每次使用代理前做个测试。
如果网站是通过IP来判断用户身份的,就使用该代理IP。
如果是通过User-Agent来判断用户身份,那就轮询或者随机挑选User-Agent。
如果是通过Cookies来判断用户,那就轮询或随机选Cookies……总之,网站的反爬虫防哪一部分,爬虫就需要绕过这一部分。
微信公众号:计算机与网络安全
ID:Computer-network
【推荐书籍】




















 2971
2971











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









