






1. 准备工作
我们来看看强大的 Zeppelin 能够给 Hive 带来什么吧。首先需要安装 Hive 和 Zeppelin。具体请参考如下两篇文章:
Zeppelin 安装与初体验
Hive 安装与配置
完成以上步骤我们才能进行下一步。
2. Hive 服务
HiveServer2 是一种可选的 Hive 内置服务,可以允许远程客户端使用不同编程语言向 Hive 提交请求并返回结果。在 Zeppelin 中使用 Hive,也需要开启 HiveServer2 服务:
|
具体参考:如何启动HiveServer2
除此之外,Zeppelin 在访问 Hive 中的数据时需要得到 Hive 中的所有元数据信息,因此需要部署一个 HiveMetaStore 服务提供 Hive 的元数据信息。启动 HiveMetaStore 服务的命令如下:
|
上述表示在后台启动 Hive 的 MetaStore 服务,MetaStore 服务监听 9083 端口,也可以不指定端口而使用默认端口。
具体参考:Hive元数据服务MetaStore
3. 配置Hive解释器
解释器(Interpreter)是 Zeppelin 里最重要的概念,每一种解释器都对应一个引擎。需要注意的是 Hive 解释器被弃用并合并到 JDBC 解释器中。可以通过使用具有相同功能的 JDBC Interpreter 来使用 Hive Interpreter。Zeppelin 是通过 Hive 的 Jdbc 接口来运行 Hive SQL。
接下来我们可以在 Zeppelin 的 Interpreter 页面配置 Jdbc Interpreter 来启用 Hive。Jdbc Interpreter 可以支持所有 Jdbc 协议的数据库,包括 Hive。Jdbc Interpreter 默认连接 Postgresql。使用 Zeppelin 启动 Hive,我们可以有2种选择:
修改默认 Jdbc Interpreter 的配置项:这种配置下,在 Note 里用 hive 可以直接 %jdbc 开头。
创建一个新的 Jdbc interpreter 并命名为 Hive:这种配置下,在 Note 里用 hive 可以直接 %hive 开头。
这里我建议选用第2种方法,针对每一种引擎,单独创建一个解释器。这里我会创建一个新的 Hive Interprete。在解释器页面点击创建按钮,创建一个名为 hive 的解释器,解释器组选择为 jdbc:
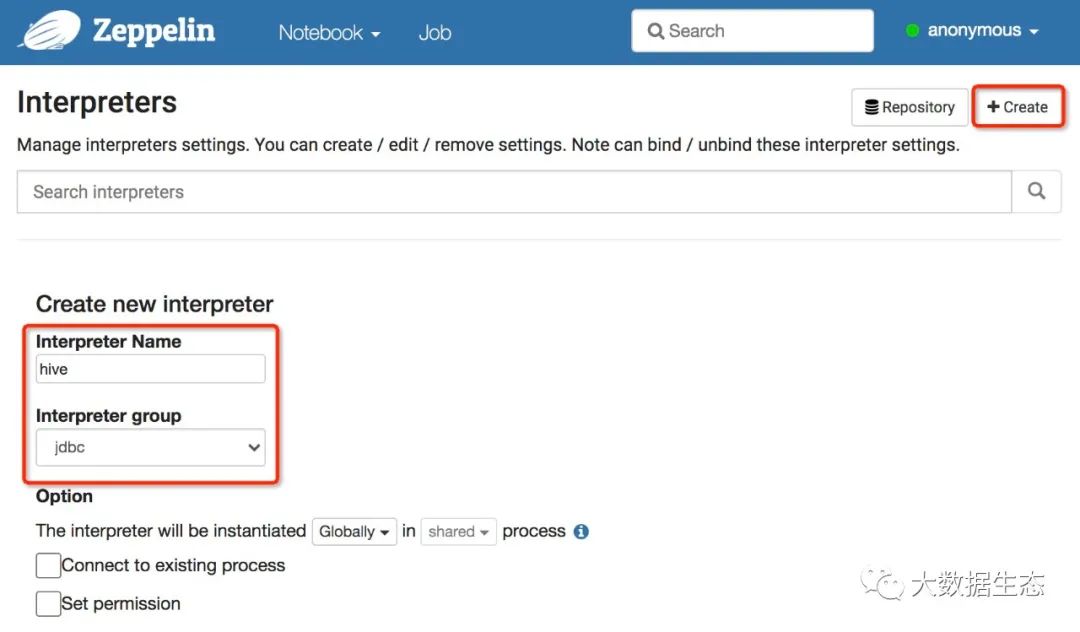
具体配置如下所示:
| 配置项 | 配置值 | 配置说明 |
|---|---|---|
| default.driver | org.apache.hive.jdbc.HiveDriver | JDBC驱动程序的类路径 |
| default.url | jdbc:hive2://localhost:10000 | 连接 URL |
| default.user | 可选 | 连接用户名 |
| default.password | 可选 | 连接密码 |
| zeppelin.interpreter.dep.mvnRepo | http://insecure.repo1.maven.org/maven2/ | Maven 远程仓库地址 |
其他选择默认配置
default.url 的默认配置形式是 jdbc:hive2://host:port/, 这里的 host 是你的 hiveserver2 的机器名,port 是 hiveserver2 的 thrift 端口 (如果你的 hiveserver2 用的是 binary 模式,那么对应的 hive 的 hive.server2.thrift.port 配置默认为 10000,如果是 http 模式,那么对应的配置默认为 10001。db_name 是你要连的 hive 数据库的名字,默认是 default。
default.driver 配置为 org.apache.hive.jdbc.HiveDriver,因为 Zeppelin 没有把 Hive 打包进去,所以默认情况下找不到这个类,需要我们在这个 Interpreter 配置中添加 Dependency:
org.apache.hive:hive-jdbc:2.3.7
org.apache.hadoop:hadoop-common:2.7.7
如下图所示:
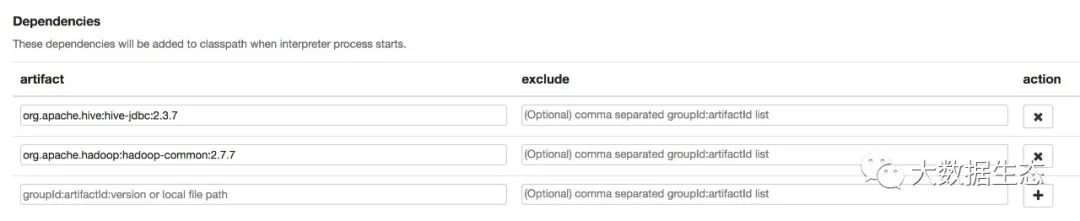
依赖的版本具体取决于你的 Hive 和 Hadoop 安装版本。
需要注意的是 zeppelin.interpreter.dep.mvnRepo 配置项如果使用默认值 http://repo1.maven.org/maven2/,在下载依赖时可能会抛出如下异常:
|
主要原因是从2020年1月15日开始,Maven 中央存储库不再支持通过纯 HTTP 进行的不安全通信,并且要求对存储库的所有请求都要通过 HTTPS 进行加密。http://repo1.maven.org/maven2/ 需要替换为 https://repo1.maven.org/maven2/,http://repo.maven.apache.org/maven2/ 需要替换为 https://repo.maven.apache.org/maven2/。如果你的环境由于某种原因无法支持 HTTPS,可以选择使用 Maven 专用的非安全端点:http://insecure.repo1.maven.org/maven2/。
具体参考:Central 501 HTTPS Required
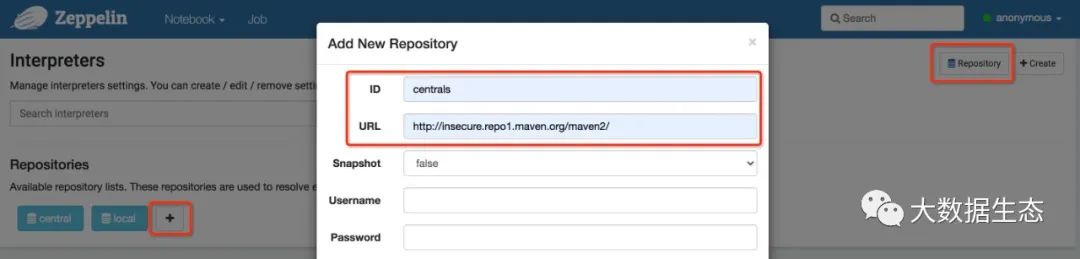
除了修改存储仓库的配置项,我们还需要创建一个可用的存储仓库来解析这些依赖。默认自动会创建两个(Central、local),下面我们创建使用 Maven 专用的非安全端点的仓库 Centrals,如下图所示:
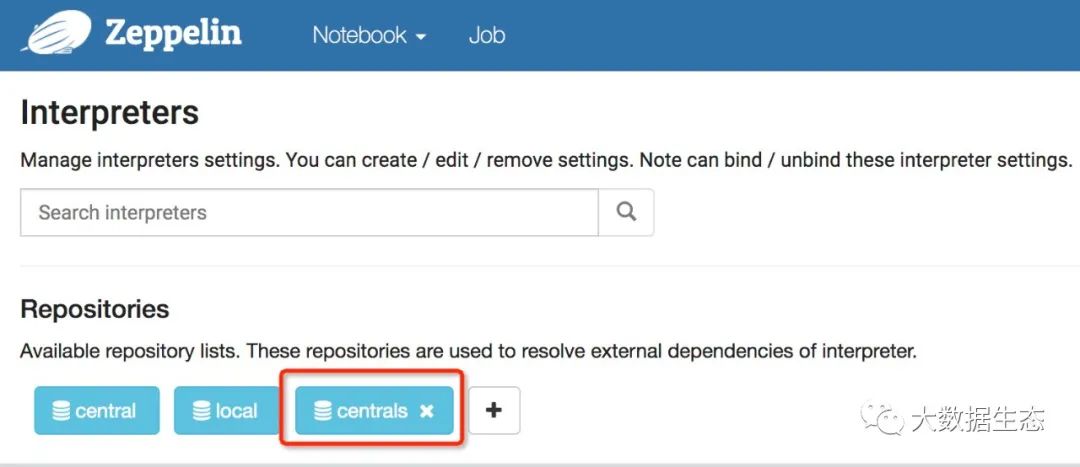
到此为止,我们就创建好了 Hive 解释器。下面我们具体看看如何在 Zeppelin 中使用 Hive。
4. 如何使用
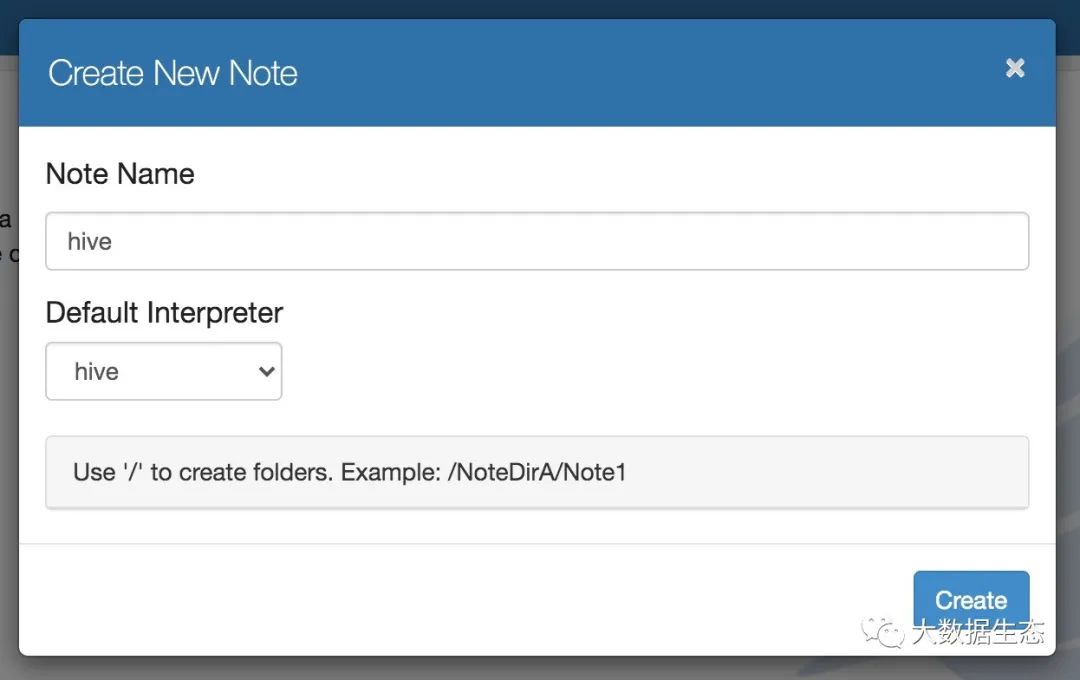
创建一个名为 hive 的 Note,记得勾选选用 Hive 解释器:
输入查询语句,注意查询语句前需要有前缀 %hive:
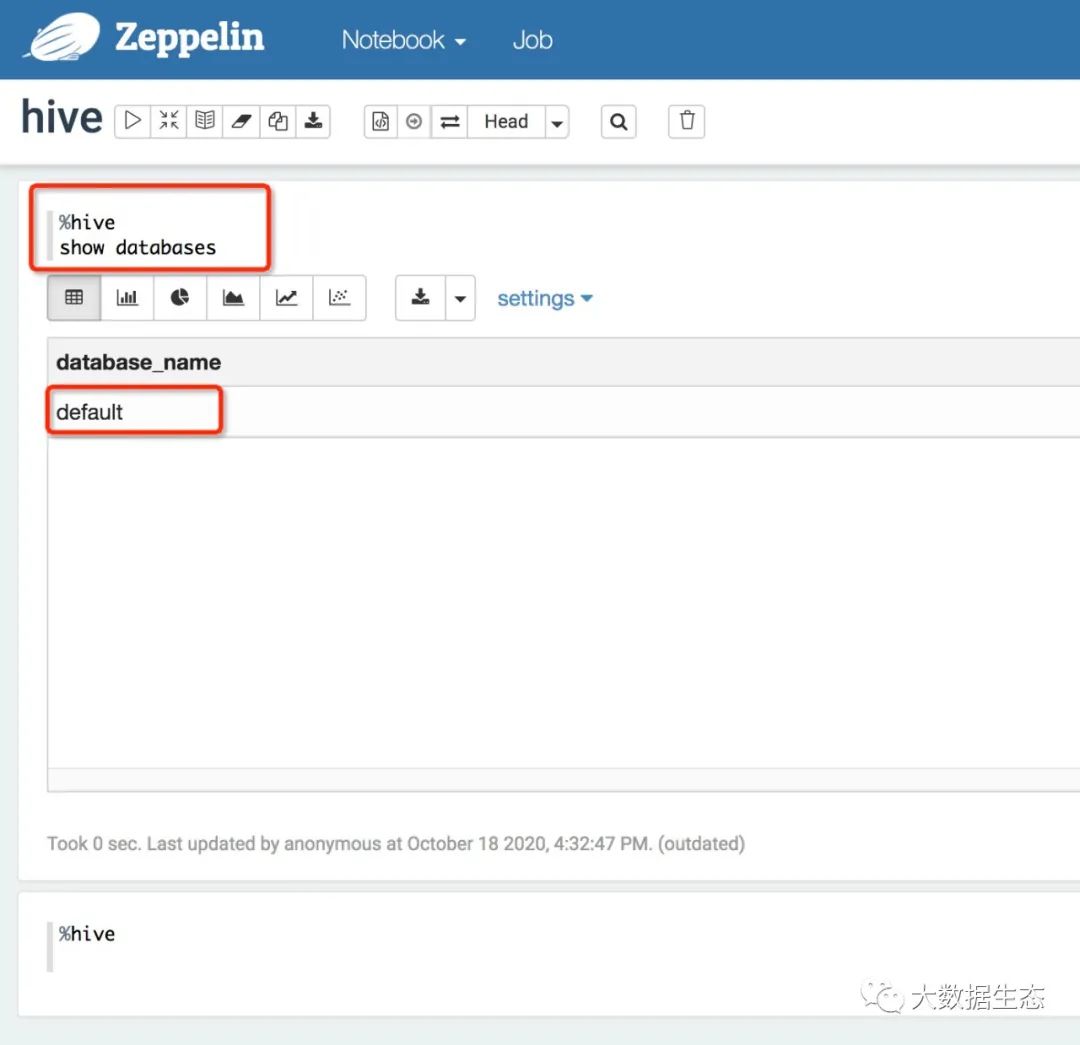
语句末尾不能加分号,不然会有错误。
欢迎关注我的公众号和博客:

参考:
Hive Interpreter for Apache Zeppelin
如何在Zeppelin里玩转Hive
Apache Zeppelin 中 Hive 解释器















 2655
2655











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









