






我们首先来了解SQL Server是如何存储数据的。
SQL Server会把磁盘分割成:
- 页(Page):每一个页大小8KB,这是数据库文件存储的基本单位。所以,即使只写入最小最简单的一行,也要使用一页。但一页可以存储多行,一行也可以占用多页。页里面既可以存储表的实际数据(我们称之为“行数据”),也可以存储索引(后文会讲)数据,以及其他系统数据。
- 区(Extent):8个连续的页。区是磁盘空间管理的基本单位,啥意思呢?就是每次SQL Server分配空间,至少是一个区(8个页)。
所以,我们知道表的行数据是存放在页里面的。但是,一个数据库里面可以有多张表。比如我们的数据库现在有Student(学生)和Teacher(老师)两张表,然后两张表都可以被这样插入数据:
- 先在Student中插入1行数据
- 然后在Teacher中插入2行数据
- 接着又在Student中插入5行数据
- 再在Teacher中插入3行数据
- 还可以再删除掉Student的1行数据
- ……
最后两张表一共有100行数据,用了100个页,但这些页是散乱的、无序的堆放在一起的(能不能想象那种效果?就像一个仓库,货物可以整整齐齐井井有条的摆放,也可以随意的堆成一堆),所以这种(没有被聚集索引组织的)页也被称之:堆(Heap)。
那么,当运行如下SQL语句的时候
SELECT SQL Server如何界定那些页(行)是属于Student表的呢?
举例:
- 一个仓库多个隔间,每个隔间都装有不同的货物(货物上没有“种类”标签),我要取出某种货物,怎么办?
- 一幢楼有多个房间,每个房间住着不同的人(Student/Teacher/Admin),所有人不知道自己属于……,我要找出所有Student,怎么办?
实际上,如果一个表没有建立聚集索引(后文详述),SQL Server会为每一张表建立一个“索引分配映射(Index Allocation Map)”,由IAM依次记录这张表所使用的所有“页”的信息:
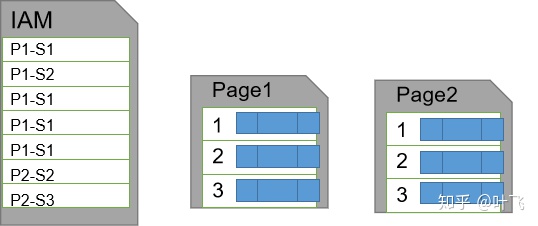
当使用SELECT进行表查找时,SQL Server会以IAM为基础,在IAM记录的所有页上依次查找,直到找到符合条件的数据。
—— 这就被称之为SQL Server的全表扫描 (Table Scan)。
但这样做有一个问题,假如Student表里有上万行数据(这其是还是非常小规模的),每行数据都有不同的Id。运行如下SQL语句:
SELECT 你要进行多少次的比对,才能找到这行数据?(复习:数据结构和算法,最好/最坏情况)
有没有更好的方法,可以快速的找到这行数据呢?同学们可以先自己想一想……
我们接下来学习SQL查询中的一个重要概念:索引(Index)。
比如我们在使用字典的时候,要查找某个字,就需要使用到(拼音)索引。通过索引指向的页码,我们就可以不用从第一页开始逐页逐页的查找,极大的提高查询速度。

数据库也一样,索引是一个帮助我们进行快速查询的工具。
而在SQL Server中,也有索引,索引对应的数据结构叫做:树。
源栈培训:人人都是程序猿(十二)平衡排序二叉树·一起帮17bang.ren
思考:为什么这么麻烦呢?直接按从小到大排序,使用二分查找不行么?
SQL Server可以使用表的一列或多列(这些列被称为索引列)数据,用于构建索引。在进行SELECT查询时,可以先检索索引,然后再根据索引找到完整的行数据。
实际上,为了更进一步的降低查询树的深度(提高查询效率),SQL Server数据库使用的是“多叉平衡查询树”。有意思的是,SQL Server在“构建”平衡树时:
- 一个叶子节点存储的是多行数据
- 是从叶子节点开始,向上添加枝和根(查找时,还是从根节点开始)
演示:构建一个索引树
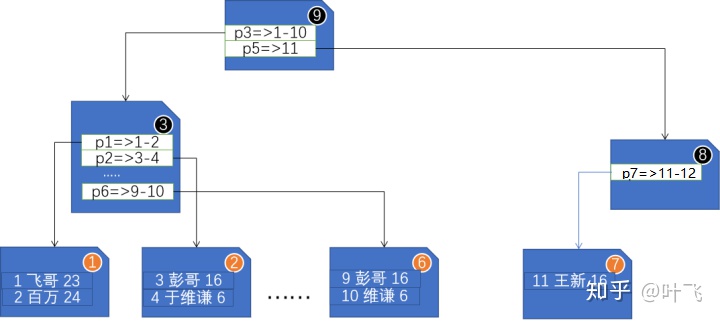
SQL Server中的索引分为以下几种:
聚集(clustered)索引
聚集索引的叶子节点直接存放的就是行数据。(如上图所示)
我们可以认为:聚集索引就是直接“包含”行数据的,一个聚集索引就可以代表一个表;而且,聚集索引决定了表中行的物理存放位置。想一想“树”的构建,当我们使用INSERT插入一行时,这行数据究竟放置在哪里,是不是由这个数据的“索引值”决定的?
所以,每张表只能有一个聚集索引。能不能想明白?
非聚集(non-clustered)索引
和聚集索引不同,非聚集索引的叶子节点中存放的不是实际的行数据,而是指向行数据的“指针”。指针可以被认为“行定位器”,具体来说,这里的指针分为两种(假设我们在Student表的Score列上建立一个非聚集索引):
- 如果Student表上已经在Id列建立了聚集索引,指针就记录这个Id(聚集索引的键值)即可;
- 如果Student表上还没有任何聚集索引,指针只能记录SQL Server为数据行建立的由文件Id、页Id和槽Id(FileID:PageId:SlotId)组成的RID(Row Id)。(也就是IAM里记录的RID?)
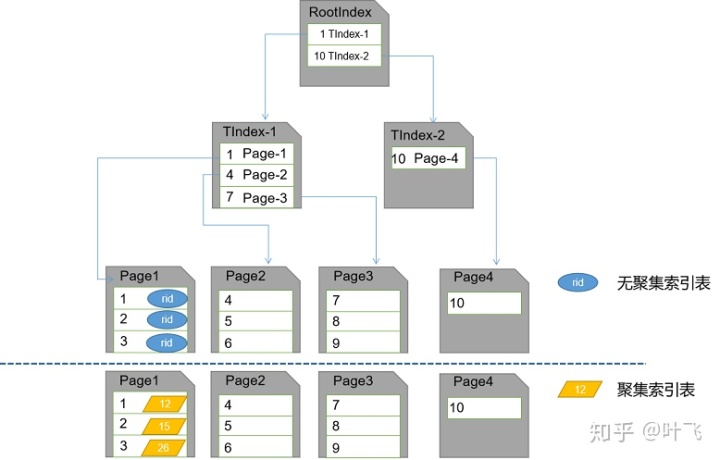
所以,实际上当我们使用非聚集索引进行查找时,并不能直接的获取目标行数据。我们还得再根据其叶子节点中存储的“指针”,再在IAM或者聚集索引中进行查找,最终才能获得行数据。这就是“聚集索引比非聚集索引快”的原因。
和聚集索引不同,一张表可以创建249个非聚集索引。
此外,索引还可以分为:
唯一和非唯一索引
如果列上的值是唯一的,我们就可以在这个列上建立唯一索引;否则,我们就只能在其上建立非唯一索引。
但在底层实现上,SQL Server里实际只有唯一索引。具体来说,SQL Server给所有的索引键值中都添加了一个后缀uniquifier:
- 如果是唯一索引,该uniquifier值始终为空,相当于不使用
- 如果是非唯一索引,SQL Server会为uniquifier自动赋值,所以可以利用uniquifier配合原索引键值,从而形成事实上的唯一索引,即每一个索引键值+uniquifier的组合都不相同
接下来我们来学习如何使用SQL语句,来建立和删除索引。为了便于演示,我们新建一个表Teacher:
CREATE 建立索引
建立索引时需要:
- 指定索引的种类:CLUSTERED还是NONCLUSTERED(默认),UNIQUE还是非UNIQUE(默认)的
- 自己给索引取一个名字,建议以IX开头,下划线连接表名和列名
- 索引在哪个表哪些个列上
示例如下:
在Teacher表Id列上建一个名为IX_Teacher_Id的聚集索引列
CREATE 一张表只能有一个聚集索引,所以不能再建立另外一个聚集索引了:
CREATE 会报错:
Cannot create more than one clustered index on table 'Teacher'. Drop the existing clustered index 'IX_Teacher_Id' before creating another.
但可以在其他列建立非聚集索引,比如:
CREATE NONCLUSTERED是默认的,所以可以省略,上述SQL等同于:
CREATE 一张表上可以建立多个非聚集索引,包括:
CREATE 关于唯一索引,需要注意:
- 建立唯一索引不需要事先添加UNIQUE约束
- 如果列中数据已有重复,将无法建立唯一索引。
甚至,多个非聚集索引还可以建立在同一个列上。但是,索引名不能重复:
CREATE 注意,在一个列上的索引是没有任何必要的而且会拖累性能的。但当一个数据库年代久远、被多人操作时,我们很容易建立冗余的索引。为了避免这种状况:
- 按上文要求对Index规范命名
- 在新建Index时,首先检查是否已有Index存在
在SQL Server Object Explore里可以查看我们已建好的Indxies:
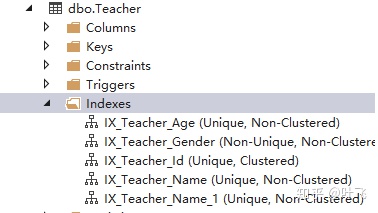
索引还可以被建立在多个列上,比如:
CREATE 如上表所示,IX_Teacher_Age_Gender是一个而不是两个索引,它建立在Age和Gender两个列上。这种索引的键值是Age和Gender的组合(不同类型的数据如何组合由SQL Server自行确定),和IX_Age或IX_Gender并不重复。多列的索引在WHERE子句同时包含多列时有用。
删除索引
删除索引时需要同时指定表名和索引名称(用点(.)连接),如下所示:
DROP 删除索引不会删除表数据(体会索引和表分离)。
作业:
制作PPT,全面的解释说明SQL Server的索引机制,包括但不限于:
- 无索引时如何进行全表扫描
- 索引是一个什么样的数据结构,如何构建和使用
- 聚集索引和非聚集索引的区别,唯一索引和非唯一索引的区别
- ……
每日单词:
感谢童鞋们的阅读!^_^
我就是:黑律师/包工头/创业狗/老码农……现在还是教书匠的大飞哥。
再次重申这个系列的目标是:
1)通俗易懂。2)实战为主。3)面向就业。
系列内容的完善需要你的反馈!
欢迎点赞和评论,以及加入我们的QQ交流群:326801052。














 355
355











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









