






深度学习11个实用技巧
深度学习工程师George Seif发表了一篇博文,总结了7个深度学习的技巧,本文增加了几个技巧,总结了11个深度学习的技巧,主要从提高深度学习模型的准确性和速度两个角度来分析这些小技巧。在使用深度学习的时候,我们不能仅仅把它看成一个黑盒子,因为网络设计、训练过程、数据处理等很多步骤都需要精心的设计。作者分别介绍了7个非常实用小技巧:数据量、优化器选择、处理不平衡数据、迁移学习、数据增强、多个模型集成、加快剪枝。相信掌握了这7个技巧,能让你在实际工作中事半功倍!
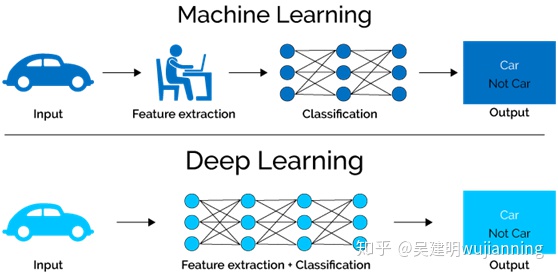
深度学习已经成为解决许多具有挑战性问题的方法。 在目标检测,语音识别和语言翻译方面,深度学习是迄今为止表现最好的方法。 许多人将深度神经网络(DNNs)视为神奇的黑盒子,我们输入一些数据,出来的就是我们的解决方案! 事实上,事情要复杂得多。
在设计和应用中,把DNN用到一个特定的问题上可能会遇到很多挑战。 为了达到实际应用所需的性能标准,数据处理、网络设计、训练和推断等各个阶段的正确设计和执行至关重要。
1. 过拟合与欠拟合
“欠拟合”常常在模型学习能力较弱,而数据复杂度较高的情况出现,此时模型由于学习能力不足,无法学习到数据集中的“一般规律”,因而导致泛化能力弱。与之相反,“过拟合”常常出现在模型学习
能力过强的情况,此时的模型学习能力太强,以至于将训练集单个样本自身的特点都能捕捉到,并将其认为是“一般规律”,同样这种情况也会导致模型泛化能力下降。过拟合与欠拟合的区别在于,欠拟合在训练集和测试集上的性能都较差,而过拟合往往能完美学习训练集数据的性质,而在测试集上的性能较差。
下图(a)与图(b)分别展示了对二维数据进行拟合时过拟合与欠拟合的情况。其中蓝色虚线代表数据的真实分布,橙色圆点为训练数据,黑色实线代表模型的拟合结果。图(a)使用简单的线性模型拟合,由于模型过于简单,没有能力捕捉模型的真实分布,产生了欠拟合。图(b)使用了高次多项式模型进行拟合,由于模型过于复杂,因此对每个测试数据都能精确预测,但模型拟合的结果没有抓住数据分布的本质特征,出现了过拟合。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 762
762











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









